Discesa per Coordinate vs Ottimizzazione Bayesiana: Chi Trova i Parametri Migliori
Questo è il quinto articolo della serie "Backtest Senza Illusioni". Negli articoli precedenti abbiamo trattato l'asimmetria perdita-profitto, il bootstrap Monte Carlo, l'impatto dei tassi di finanziamento e la cache Parquet per backtest più veloci. Parliamo ora del processo di ricerca dei parametri ottimali della strategia — un compito in cui l'intuizione fallisce più spesso.
Hai una strategia con 12 parametri. Ogni parametro prende ~9 valori. Vuoi trovare la combinazione che massimizza il PnL con un drawdown limitato. Come lo fai?
Se la tua risposta è "itero attraverso tutte le combinazioni" — hai un problema. Se la tua risposta è "cambio un parametro alla volta" — hai un problema diverso. Questo articolo parla di quali problemi si nascondono dietro ogni approccio e come risolverli.
Perché la Ricerca Esaustiva è Impossibile

La Maledizione della Dimensionalità
La ricerca esaustiva (grid search) testa ogni combinazione di valori per ogni parametro. Per due parametri con 9 valori, sono esecuzioni — perfettamente fattibile. Per tre: — tollerabile.
Ma per una strategia reale con 12 parametri:
Duecentottantadue miliardi di esecuzioni. Anche se un singolo backtest richiede 1 secondo (il che è già ottimistico), la ricerca esaustiva richiederebbe:
Questa è una crescita esponenziale: ogni nuovo parametro moltiplica lo spazio di ricerca per 9. Aggiungi un 13° parametro — e invece di 9.000 anni ne servono 80.000.
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""Stima il costo della ricerca esaustiva."""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Anni: {cost['total_years']:,.0f}") # 8,950
Anche con il Precalcolo
Nell'articolo sulla cache Parquet abbiamo mostrato come il precalcolo dei timeframe e degli indicatori velocizza un singolo backtest a ~1 secondo. Ma anche a 0,1 secondi per esecuzione, la ricerca esaustiva di 12 parametri richiederebbe 895 anni. Il precalcolo aiuta, ma non risolve il problema fondamentale della crescita esponenziale.
Abbiamo bisogno di metodi che esplorino lo spazio dei parametri in modo più intelligente della ricerca esaustiva.
Discesa per Coordinate e OAT: Veloci ma Cieche
Due Varianti della Stessa Idea
Esistono due approcci correlati — entrambi ottimizzano un parametro alla volta, ma differiscono nel numero di passaggi:
OAT (One-at-a-Time) sweep — un singolo passaggio attraverso tutti i parametri. Itera sui valori del primo parametro, fissa il migliore, passa al secondo — e così via. Una volta sola. Veloce ed economico.
Discesa per Coordinate — multipassaggio. Dopo aver ottimizzato l'ultimo parametro, torna al primo e verifica se l'ottimo è cambiato (poiché il contesto è cambiato — i valori degli altri parametri sono ora diversi). Ripeti i cicli fino alla convergenza. Più costosa, ma più precisa — ogni ciclo può affinare la soluzione.
In pratica, per i backtest si usa più spesso OAT: un singolo passaggio attraverso 12 parametri — 96 esecuzioni. La discesa per coordinate con 3-5 cicli — 300-500 esecuzioni, che è già paragonabile a Optuna, ma senza i suoi vantaggi.
Per 12 parametri con ~8 valori ciascuno:
Confronta con per la grid search. OAT è lineare: invece di . Questo è sia il suo principale vantaggio sia il suo principale problema.
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT sweep: singolo passaggio, ottimizzando un parametro alla volta.
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: valori iniziali per tutti i parametri
metric: metrica da ottimizzare (effective_score raccomandato —
PnL per tempo attivo estrapolato a un anno)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
Quale metrica scegliere per l'ottimizzazione? Invece del PnL grezzo o PnL@MaxLev, si raccomanda di usare l'effective score — PnL per tempo attivo estrapolato a un anno. Questa metrica tiene conto del tempo in posizione e permette un confronto corretto tra strategie con frequenze di trading diverse.
Il Punto Cieco: Interazioni tra Parametri
OAT assume che l'effetto di ogni parametro sia additivo — cioè, il valore ottimale di un parametro non dipende dai valori degli altri. Questa assunzione regge per alcuni parametri, ma si rompe per quelli accoppiati.
Parametri Additivi vs Accoppiati
Prima di ottimizzare — è utile classificare i parametri:
Additivi (indipendenti) — il valore ottimale di uno non dipende dall'altro. Possono essere ottimizzati uno alla volta a basso costo:
htf_entry_sellehtf_entry_buy— soglie di ingresso per diverse direzioni (vendita/acquisto) sullo stesso timeframe. La soglia di vendita filtra i segnali short, quella di acquisto — i long. Operano su sottoinsiemi di trade non sovrapposti.tp_targetebe_trigger— take-profit e breakeven, se non creano condizioni di uscita conflittuali.
Accoppiati (interattivi) — il valore ottimale di uno dipende dall'altro. È necessaria un'ottimizzazione congiunta:
htf_entry_sellemtf_entry_sell— soglie per la stessa direzione (vendita) su timeframe diversi. HTF determina quali segnali raggiungono MTF, e la soglia MTF determina l'efficacia del filtraggio. L'ottimo HTF si sposta quando cambia MTF.ltf_entry_sell,mtf_entry_sell,htf_entry_sell— l'intera catena di soglie per una direzione.partial_fracetp_target— la dimensione della chiusura parziale dipende dal livello TP.
Approccio pratico: prima ottimizza a basso costo i parametri additivi tramite OAT. Poi ottimizza i gruppi accoppiati tramite Optuna. Questo riduce il budget: invece di 12 parametri in Optuna, si inviano solo 6-8 accoppiati, mentre gli altri sono già fissati.
Esempio: Come OAT Perde un'Interazione
Considera due soglie accoppiate:
htf_entry_sell— soglia sul timeframe superiore (direzione vendita)mtf_entry_sell— soglia sul timeframe medio (direzione vendita)
OAT fissa mtf_entry_sell = 0.01 (valore iniziale) e itera su htf_entry_sell. Trova il valore migliore: htf_entry_sell = 0.02. Lo fissa e passa al parametro successivo — non torna mai indietro.
Ecco cosa OAT ha perso:
htf_entry_sell |
mtf_entry_sell |
PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
La combinazione (0.03, 0.02) produce un PnL +51%, ma OAT non la considererà mai perché con mtf_entry_sell = 0.01 fisso, il valore htf_entry_sell = 0.03 produce solo +35%. OAT si è "bloccato" nell'ottimo locale (0.02, 0.01) e non riesce a vedere l'ottimo globale (0.03, 0.02).
Questo è un problema classico: se il paesaggio della funzione obiettivo contiene creste diagonali (quando l'ottimo di un parametro si sposta al variare di un altro), OAT le perde.
Formalizzare il Problema
Sia la funzione obiettivo (PnL). OAT trova un punto dove:
Ma questa è una condizione necessaria, non sufficiente per un ottimo globale. Se la matrice Hessiana ha elementi fuori diagonale significativi — OAT non tiene conto delle derivate incrociate quando .
Per i parametri accoppiati (soglie della stessa direzione su più timeframe) — le interazioni sono la regola, non l'eccezione. La soglia di ingresso sul timeframe superiore determina quali segnali raggiungono quello medio, e la soglia su quello medio determina l'efficacia del filtraggio su quello inferiore. Per i parametri additivi (direzioni diverse, filtri indipendenti) le derivate incrociate sono vicine a zero — e OAT funziona bene.
Ottimizzazione Bayesiana: Ricerca Intelligente

L'Idea
Invece dell'enumerazione cieca o della ricerca greedy, l'ottimizzazione bayesiana costruisce un modello surrogato della funzione obiettivo e ad ogni passo seleziona il punto in cui il miglioramento atteso è massimo.
Algoritmo:
- Scegli diversi punti casuali, valuta la funzione obiettivo
- Costruisci un modello surrogato (approssima dai punti osservati)
- Trova il punto con il massimo miglioramento atteso (funzione di acquisizione)
- Valuta la funzione obiettivo in quel punto
- Aggiorna il modello surrogato
- Ripeti i passi 3-5
La differenza chiave rispetto a OAT: l'ottimizzazione bayesiana considera tutti i parametri simultaneamente e può esplorare le creste diagonali nello spazio dei parametri.
TPE (Tree-structured Parzen Estimator)

TPE è il campionatore predefinito in Optuna. Invece di modellare direttamente, TPE modella due distribuzioni:
- — distribuzione dei parametri dove la funzione obiettivo è migliore della soglia
- — distribuzione dei parametri dove la funzione obiettivo è peggiore della soglia
La funzione di acquisizione di TPE — il rapporto:
TPE seleziona i punti dove è grande (parametri simili a quelli "buoni") e è piccolo (parametri non simili a quelli "cattivi").
Perché TPE è adatto per i backtest:
- Gestisce le dipendenze condizionali tra parametri
- Non richiede la continuità della funzione obiettivo
- Efficiente con budget moderati (100-1000 iterazioni)
- Supporta parametri categorici e discreti
Processo Gaussiano (GP)
Un'alternativa a TPE — il Processo Gaussiano. GP modella come un processo normale multivariato e fornisce non solo una previsione del valore, ma anche l'incertezza in ogni punto.
dove è la media, è la funzione di covarianza (kernel).
GP funziona bene quando:
- I parametri sono pochi (fino a 10-15)
- La funzione obiettivo è liscia
- Ogni esecuzione è costosa (minuti, ore)
Per i backtest con una cache Parquet precalcolata, dove una singola esecuzione richiede ~1 secondo, TPE è di solito preferito: costruisce il modello più velocemente e scala meglio a 500+ iterazioni.
Integrazione Pratica con Optuna
Esempio Completo Funzionante
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
Esegue un backtest con i parametri dati.
Restituisce un dict con metriche: pnl, max_dd, n_trades, trading_time, sharpe.
Usa la cache Parquet precalcolata — ~1 secondo per esecuzione.
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Funzione obiettivo per Optuna."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Miglior PnL: {-study.best_value:.2f}%")
print(f"Migliori parametri: {study.best_params}")
print(f"Totale trials: {len(study.trials)}")
A ~1 secondo per backtest (con cache precalcolata):
Otto minuti contro 8.950 anni di ricerca esaustiva. E TPE in 500 iterazioni trova combinazioni che OAT perde in 96, perché esplora lo spazio dei parametri simultaneamente invece che asse per asse.
Salvare e Riprendere uno Studio
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # continua se lo studio esiste già
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
Aggiungere Vincoli
Non tutte le combinazioni di parametri sono valide. Per esempio, la soglia di uscita non dovrebbe superare quella di ingresso:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
Confronto dei Campionatori
Optuna supporta diversi campionatori. Ognuno ha i propri punti di forza.
TPESampler (predefinito)
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # trial casuali prima che inizi la modellazione
seed=42,
)
- Principio: Tree-structured Parzen Estimator
- Punti di forza: buono per tipi di parametri misti, scala a 1000+ iterazioni
- Punti deboli: può essere meno efficiente con forti interazioni tra parametri
- Quando usarlo: di default, se non c'è ragione di scegliere un altro
CmaEsSampler
sampler = optuna.samplers.CmaEsSampler(seed=42)
- Principio: Covariance Matrix Adaptation Evolution Strategy — un algoritmo evolutivo che adatta la matrice di covarianza
- Punti di forza: eccellente nel trovare interazioni tra parametri continui, tiene conto delle correlazioni
- Punti deboli: non supporta parametri categorici, richiede più iterazioni per l'inizializzazione
- Quando usarlo: se tutti i parametri sono continui e si sospettano forti interazioni
GPSampler
sampler = optuna.samplers.GPSampler(seed=42)
- Principio: Processo Gaussiano con funzione di acquisizione
- Punti di forza: migliore efficienza del campionamento (meno iterazioni per un buon risultato), fornisce stime dell'incertezza
- Punti deboli: nel numero di iterazioni — lento quando
- Quando usarlo: se un singolo backtest è costoso (minuti) e il budget è limitato a 100-200 iterazioni
RandomSampler (baseline)
sampler = optuna.samplers.RandomSampler(seed=42)
- Principio: campionamento casuale uniforme
- Punti di forza: non si blocca negli ottimi locali, copertura completa dello spazio
- Punti deboli: non usa i risultati precedenti
- Quando usarlo: come baseline per il confronto, o per l'analisi esplorativa
QMCSampler
sampler = optuna.samplers.QMCSampler(seed=42)
- Principio: Quasi-Monte Carlo (sequenze di Sobol/Halton) — riempie lo spazio in modo più uniforme di un campionatore casuale
- Punti di forza: migliore copertura dello spazio rispetto a RandomSampler, riproducibilità
- Punti deboli: non si adatta ai risultati
- Quando usarlo: per le prime 50-100 iterazioni prima di passare a TPE
Tabella Riassuntiva
| Campionatore | Tipo | Interazioni | Categorici | Budget Ottimale |
|---|---|---|---|---|
| TPE | Bayesiano | Parziale | Sì | 100-1000 |
| CmaEs | Evolutivo | Sì | No | 200-2000 |
| GP | Bayesiano | Sì | Limitato | 50-200 |
| Random | Casuale | No | Sì | Qualsiasi (baseline) |
| QMC | Quasi-casuale | No | No | 50-500 |
Benchmark Pratico
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""Confronta i campionatori sullo stesso compito."""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: miglior PnL={result['best_value']:.2f}%, "
f"trovato al trial #{result['best_trial']}, "
f"tempo={result['elapsed_sec']:.1f}s")
Risultati tipici per una strategia con 12 parametri:
| Campionatore | Miglior PnL | Trovato all'Iterazione | Overhead del Campionatore |
|---|---|---|---|
| TPE | ~51% | ~180 | Basso |
| CmaEs | ~49% | ~250 | Medio |
| GP | ~48% | ~90 | Alto quando |
| Random | ~42% | ~270 | Minimo |
| QMC | ~43% | ~200 | Minimo |
TPE e CmaEs superano consistentemente la ricerca casuale del 15-20% nel PnL finale. GP trova buoni risultati prima ma raggiunge un tetto computazionale con un gran numero di iterazioni.
Ottimizzazione Multi-Obiettivo: PnL vs MaxDD
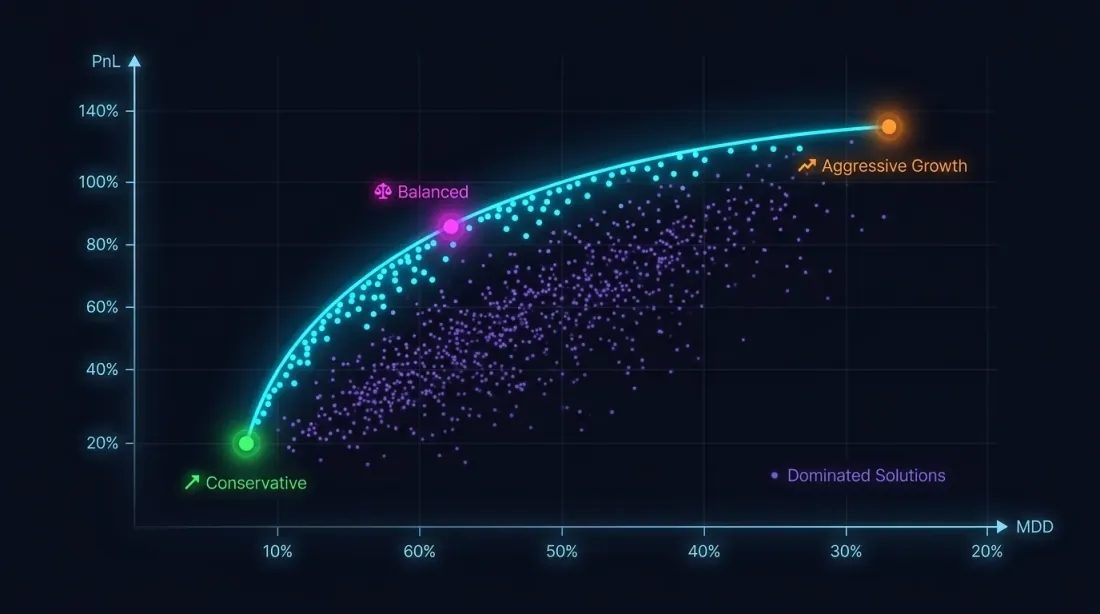
Perché un Singolo Criterio Non Basta
Massimizzare il PnL senza vincoli sul drawdown è la strada verso il disastro. Una strategia con PnL +80% e MaxDD -30% è, a causa dell'asimmetria perdita-profitto, significativamente più rischiosa di una strategia con PnL +50% e MaxDD -5%.
Il problema di ottimizzazione è in realtà multi-obiettivo:
Questi obiettivi sono in conflitto: i parametri aggressivi aumentano sia il PnL che il drawdown. La soluzione non è un singolo punto, ma un fronte di Pareto: un insieme di soluzioni in cui non è possibile migliorare una metrica senza peggiorare l'altra.
NSGA-II / NSGA-III in Optuna
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""Funzione multi-obiettivo: (PnL, MaxDD)."""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # massimizza
max_dd = result["max_dd"] # minimizza (già un numero negativo)
return pnl, max_dd # Optuna: entrambe le direzioni sono impostate in create_study
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Fronte di Pareto: {len(pareto_trials)} soluzioni")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
Selezionare un Punto sul Fronte di Pareto
Il fronte di Pareto fornisce molteplici soluzioni. Come sceglierne una?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
Filtra il fronte di Pareto per vincoli.
max_dd_limit: drawdown massimo accettabile (es. -5%)
min_pnl: PnL minimo accettabile (%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
Nota: nel calcolo del PnL alla leva massima, è necessario tenere conto dei tassi di finanziamento, altrimenti una leva teoricamente elevata si trasformerà in una perdita sul mercato reale. Inoltre, il PnL finale è una stima puntuale, e per valutare la stabilità dei risultati è necessario il bootstrap Monte Carlo.
Esempio: Tre Strategie sul Fronte di Pareto
| Strategia | PnL | MaxDD | MaxLev | PnL@MaxLev | Tempo di trading |
|---|---|---|---|---|---|
| Strategia A | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| Strategia B | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| Strategia C | ~300% | ~17% | ~3x | ~900% | ~45% |
La Strategia C con un impressionante PnL di +300% risulta essere la meno attraente per PnL@MaxLev a causa dell'elevato drawdown. La Strategia A guida nel rendimento netto con leva, ma tenendo conto del PnL per tempo attivo, la Strategia B può essere preferibile — il 95% del tempo libero può essere riempito con altre strategie.
Grafici a Contorno e Importanza dei Parametri

Visualizzazione del Paesaggio
Dopo l'ottimizzazione — la visualizzazione. Optuna fornisce strumenti integrati:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
Grafico a Contorno: Leggere le Interazioni
Un grafico a contorno costruisce una sezione bidimensionale della funzione obiettivo per una coppia di parametri. Se le isolinee sono parallele a uno degli assi — i parametri non interagiscono, e OAT avrebbe trovato lo stesso ottimo. Se le isolinee sono diagonali — c'è interazione, e OAT la perderà.
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
Se un grafico a contorno mostra un plateau — una regione dove la funzione obiettivo cambia poco — questo è un buon segno. Un plateau significa che il risultato è robusto a piccole deviazioni dei parametri. Di più sull'analisi dei plateau e sulla sua relazione con l'overfitting — nell'articolo in arrivo Analisi del plateau.
Importanza dei Parametri
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
Output tipico:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
I parametri con importanza < 0.01 possono essere fissati al loro valore predefinito — questo riduce la dimensionalità del problema e velocizza l'ottimizzazione. Ma attenzione: una bassa importanza può anche significare che il parametro è importante solo nell'interazione con altri. Verifica tramite grafici a contorno.
Cache Precalcolata: Perché 1 Secondo per Backtest Cambia Tutto
La velocità di un singolo backtest determina quale metodo di ottimizzazione puoi permetterti.
| Tempo Backtest | 96 OAT | 500 TPE | 2000 CmaEs |
|---|---|---|---|
| 60 secondi | 1.6 ore | 8.3 ore | 33 ore |
| 10 secondi | 16 minuti | 83 minuti | 5.5 ore |
| 1 secondo | 1.5 minuti | 8 minuti | 33 minuti |
| 0.1 secondi | 10 secondi | 50 secondi | 3.3 minuti |
A 60 secondi per backtest, 500 iterazioni TPE richiedono 8 ore. Già tollerabile, ma iterare (cambiare la funzione obiettivo, riavviare) è costoso. A 1 secondo — 8 minuti, e puoi eseguire decine di esperimenti al giorno.
Ecco precisamente perché il precalcolo nella cache Parquet non è solo un'ottimizzazione della velocità, ma un'espansione dello spazio dei metodi disponibili. Senza cache sei limitato a OAT o 100 iterazioni GP. Con cache — puoi permetterti 2000 iterazioni CmaEs o un NSGA-III multi-obiettivo completo.
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache caricata in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
Raccomandazioni Pratiche
Quando Usare OAT
OAT è giustificato nei seguenti casi:
-
Analisi esplorativa. Stai iniziando a esplorare una strategia e vuoi capire quali parametri influenzano il risultato. 96 esecuzioni in 1.5 minuti — un ottimo punto di partenza.
-
Parametri additivi. Per i parametri che operano su sottoinsiemi di trade non sovrapposti (direzioni vendita vs acquisto, strumenti diversi), OAT darà un risultato corretto più velocemente.
-
Backtest molto costoso. Se una singola esecuzione richiede 10+ minuti e non può essere velocizzata, OAT con 96 esecuzioni (16 ore) è preferibile a 500 iterazioni TPE (3.5 giorni).
Quando Usare Optuna
Optuna è preferibile nella maggior parte dei casi:
-
Più di 3 parametri. Le interazioni sono praticamente garantite — OAT perderà l'ottimo.
-
Strategie multi-timeframe. Le soglie su diversi timeframe sono quasi sempre interconnesse.
-
Ottimizzazione finale. Quando la strategia ha superato il bootstrap Monte Carlo e sei sicuro della sua robustezza — Optuna troverà i parametri migliori.
-
Problemi multi-obiettivo. PnL vs MaxDD vs tempo di trading — OAT non può risolvere questo problema in linea di principio.
Approccio Ibrido: OAT per Additivi + Optuna per Accoppiati
Non devi scegliere tra OAT e Optuna — è meglio combinarli:
-
Classifica i parametri. Dividi in additivi (indipendenti) e accoppiati (interattivi). Esempio per 12 parametri di separazione:
- Additivi:
htf_entry_sell<->htf_entry_buy,mtf_entry_sell<->mtf_entry_buy,ltf_entry_sell<->ltf_entry_buy(vendita/acquisto — direzioni diverse, operano su trade non sovrapposti) - Gruppo accoppiato vendita:
htf_entry_sell,mtf_entry_sell,ltf_entry_sell(catena di filtraggio: HTF -> MTF -> LTF per i segnali di vendita) - Gruppo accoppiato acquisto:
htf_entry_buy,mtf_entry_buy,ltf_entry_buy
- Additivi:
-
OAT per additivi. Ottimizza i gruppi vendita e acquisto indipendentemente. Se i parametri di vendita non influenzano i trade di acquisto — OAT darà un risultato corretto in minuti.
-
Optuna per accoppiati. All'interno di ogni gruppo (vendita: 6 parametri entrata+uscita) usa TPE. 6 parametri invece di 12 — il budget è dimezzato.
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6 parametri → 300 sono sufficienti
Pipeline di Ottimizzazione Completa
1. Precalcola la cache Parquet (una volta sola)
2. Classifica i parametri: additivi vs accoppiati
3. OAT per additivi (~50 esecuzioni, ~1 min) → fissa
4. Optuna TPE per gruppi accoppiati (300 iterazioni x 2 gruppi, ~10 min)
5. Optuna NSGA-III per meta-parametri (500 iterazioni, ~8 min) → fronte di Pareto
6. Grafici a contorno → visualizza le interazioni
7. Bootstrap Monte Carlo dei punti migliori → intervalli di confidenza
8. Walk-Forward → validazione out-of-sample
Il passo 8 — ottimizzazione walk-forward — è fondamentale per la protezione contro l'overfitting. Di più su questo nell'articolo in arrivo Walk-Forward.
Insidie dell'Ottimizzazione
Overfitting. Più parametri e più precisa è l'ottimizzazione — maggiore è il rischio di adattare la strategia ai dati storici. 500 iterazioni Optuna con 12 parametri troveranno una combinazione che funziona perfettamente sul set di addestramento, ma è inutile su nuovi dati.
Protezione:
- Dividi i dati in train/test (70/30)
- Usa il bootstrap Monte Carlo per valutare la stabilità
- Valida tramite walk-forward
- Preferisci soluzioni sui plateau (di più in Analisi del plateau)
Problema dei confronti multipli. Se testi 500 combinazioni, la probabilità di trovare casualmente un risultato "buono" cresce. La correzione di Bonferroni o il controllo FDR (False Discovery Rate) aiutano, ma l'approccio più semplice è la validazione out-of-sample.
Budget insufficiente. TPE con 50 iterazioni per 12 parametri è troppo poco. Le prime 20 iterazioni sono casuali (startup), lasciando solo 30 per la modellazione. Budget minimo: iterazioni per 12 parametri, raccomandato: .
Freqtrade: Come Funziona in un Framework di Produzione

Freqtrade — uno dei framework di algotrading più popolari — usa Optuna internamente attraverso il modulo Hyperopt. La sua esperienza conferma le nostre raccomandazioni:
- Campionatori: TPE (predefinito), GP, CmaEs, NSGA-II, QMC — tutti disponibili tramite configurazione
- Funzioni di perdita: 12 funzioni di perdita integrate, incluse ShortTradeDurHyperOptLoss, SharpeHyperOptLoss, MaxDrawDownHyperOptLoss
- Multi-obiettivo: supporto per NSGA-II e NSGA-III per l'ottimizzazione simultanea di più metriche
- Campionatori personalizzati: possibilità di collegare qualsiasi campionatore compatibile con Optuna
Una lezione chiave dall'ecosistema Freqtrade: le funzioni di perdita integrate coprono scenari tipici, ma per un'ottimizzazione seria è necessaria una funzione obiettivo personalizzata che tenga conto delle specificità della tua strategia — tempo attivo, costi di finanziamento, drill-down adattivo per una simulazione accurata degli eseguiti.
Conclusione

La discesa per coordinate (OAT) è un metodo veloce e intuitivo. Per 12 parametri richiede solo 96 esecuzioni e termina in un minuto e mezzo. Ma è cieca alle interazioni tra parametri — e nelle strategie multi-timeframe, le interazioni sono quasi sempre presenti.
L'ottimizzazione bayesiana tramite Optuna (TPE, GP, CmaEs) esplora lo spazio dei parametri nel suo insieme. 500 iterazioni in 8 minuti — con una cache Parquet precalcolata — trovano combinazioni invisibili a OAT.
L'ottimizzazione multi-obiettivo (NSGA-III) trasforma il problema di "massimizzare il PnL" nel problema di "costruire un fronte di Pareto PnL vs MaxDD" — e fornisce un insieme di soluzioni con diversi compromessi rischio-rendimento.
Ma l'ottimizzazione è solo una parte della pipeline. I parametri trovati devono essere validati tramite bootstrap Monte Carlo, corretti per i tassi di finanziamento, ricalcolati tenendo conto del tempo attivo e sottoposti a validazione walk-forward. Di più su questo nei prossimi articoli della serie.
Link Utili
- Optuna: A Next-generation Hyperparameter Optimization Framework (Akiba et al., 2019)
- Algorithms for Hyper-Parameter Optimization (Bergstra et al., 2011) — il paper originale su TPE
- Optuna Documentation — Samplers
- Optuna Visualization Module
- Hansen, N. — The CMA Evolution Strategy: A Tutorial
- Deb, K. et al. — NSGA-II: A Fast and Elitist Multiobjective Genetic Algorithm (2002)
- Snoek, J. et al. — Practical Bayesian Optimization of Machine Learning Algorithms (2012)
- Freqtrade Documentation — Hyperopt
- Marcos Lopez de Prado — Advances in Financial Machine Learning, Chapter 12
- Bergstra, J. & Bengio, Y. — Random Search for Hyper-Parameter Optimization (2012)
Citazione
@article{soloviov2026optuna,
author = {Soloviov, Eugen},
title = {Discesa per Coordinate vs Ottimizzazione Bayesiana: Chi Trova i Parametri Migliori},
year = {2026},
url = {https://marketmaker.cc/it/blog/post/optuna-vs-coordinate-descent},
description = {Perché la ricerca esaustiva è impossibile per 12+ parametri, come la discesa per coordinate perde le interazioni e come Optuna con un campionatore TPE trova in 500 iterazioni ciò che OAT non riesce a trovare in 96.}
}
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più

Drill-Down Adattivo: Backtest con Granularità Variabile dai Minuti ai Trade Grezzi

Cache Parquet Aggregata: Come Accelerare i Backtest Multi-Timeframe di Centinaia di Volte
