Polars vs Pandas untuk Algotrading: Benchmark pada Data Nyata

Seri "Backtest Tanpa Ilusi", Artikel 9
Backtesting strategi bukan hanya tentang logika sinyal dan simulasi eksekusi. Ini juga merupakan pipeline data: memuat jutaan candle, resampling timeframe, menghitung indikator, melakukan filtering berdasarkan kondisi, pengelompokan berdasarkan instrumen. Ketika pipeline memakan waktu 30 detik alih-alih 3 detik, itu bukan sekadar ketidaknyamanan. Artinya 10x lebih sedikit eksperimen per jam, iterasi 10x lebih lambat, dan jalur 10x lebih panjang dari ide menuju produksi.
Pandas adalah standar de facto untuk data tabular di Python. Namun Pandas dirancang pada tahun 2008, ketika inti CPU lebih lambat dan dataset lebih kecil. Pandas berjalan single-thread, rakus memori, dan tidak memiliki query optimizer. Polars adalah library generasi berikutnya yang ditulis dalam Rust, dengan eksekusi paralel, Apache Arrow sebagai intinya, dan lazy query planner.
Pertanyaannya: seberapa lebih cepat Polars pada tugas algotrading nyata? Bukan pada benchmark sintetis dari README, tetapi pada filtering tick, komputasi indikator rolling, pengelompokan berdasarkan instrumen, dan pemuatan dari Parquet/QuestDB?
Artikel ini menyajikan benchmark sistematis dengan angka, kode, dan rekomendasi praktis.
Metodologi Benchmark
 Laboratorium pengukuran futuristik: lingkungan benchmarking presisi dengan parameter terkontrol
Laboratorium pengukuran futuristik: lingkungan benchmarking presisi dengan parameter terkontrol
Sebelum membandingkan, mari kita tentukan aturannya agar hasil dapat direproduksi dan adil.
Lingkungan
- Python 3.11, Pandas 2.2, Polars 1.x (versi stabil terbaru)
- Mesin: 8 core, 32 GB RAM, NVMe SSD
- Setiap benchmark dijalankan 100 kali; diambil nilai median
- Warmup: 5 iterasi sebelum pengukuran
- GC dinonaktifkan selama pengukuran (
gc.disable())
Data
Tiga tingkat skala:
- Kecil: 10K baris (satu instrumen, satu hari, candle menit)
- Sedang: 1M baris (satu instrumen, ~2 tahun, candle menit)
- Besar: 10M+ baris (100 instrumen, 2 tahun, candle menit)
Selain itu: dataset NYC Taxi nyata (12,7 juta baris) untuk benchmark ETL — standar benchmark industri.
Yang Kita Ukur
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Fair benchmark: warmup + median of n runs."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
Benchmark Operasi: Tabel
 Perbandingan performa di berbagai operasi: filter, groupby, join, dan select pada skala data berbeda
Perbandingan performa di berbagai operasi: filter, groupby, join, dan select pada skala data berbeda
Dataset kecil (10K baris)
| Operasi | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
Pada 10K baris, Pandas kadang lebih cepat pada filter sederhana — overhead pemanggilan fungsi Polars melalui PyO3 sebanding dengan waktu operasi itu sendiri. Namun pada join, keunggulan sudah terlihat: hash table Polars di Rust 13x lebih cepat.
Dataset sedang (1M baris)
| Operasi | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
Pada satu juta baris, Polars secara konsisten 1,6x lebih cepat pada filtering dan grouping. Pada select (memilih subset kolom) — 10,9x, karena format kolumnar Arrow memungkinkan zero-copy slicing.
Dataset besar (10M+ baris)
| Operasi | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
Pada data besar, keunggulan Polars tumbuh secara nonlinier: eksekusi paralel pada 8 core dan query optimizer menghasilkan efek kumulatif. GroupBy 8,6x lebih cepat — perbedaan antara "menunggu satu detik" dan "menunggu 100 milidetik."
ETL pada Data Nyata (NYC Taxi, 12,7 juta baris)
| Operasi | Pandas (s) | Polars (s) | Speedup |
|---|---|---|---|
| CSV Load | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| Multi-column transform | 2.1 | 0.7 | 3.0x |
| Full ETL pipeline | 34.4 | 2.26 | 15.2x |
I/O CSV adalah hasil paling dramatis: Polars membaca CSV secara paralel dengan engine Rust-nya, 25x lebih cepat. Ini kritis untuk pemuatan awal data historis.
Benchmark Resmi PDS-H (Mei 2025)
 Lomba performa library DataFrame: Polars dan DuckDB memimpin sementara Pandas tertinggal dalam orde besaran
Lomba performa library DataFrame: Polars dan DuckDB memimpin sementara Pandas tertinggal dalam orde besaran
PDS-H (Performance Data Science — Holistic) adalah benchmark standar untuk library DataFrame, analog dengan TPC-H untuk database. Hasil dari Mei 2025:
- Pandas hanya berpartisipasi pada skala SF-10 — single-thread, tanpa query optimizer, dua orde besaran lebih lambat dari para pemimpin
- Polars dan DuckDB berada di liga mereka sendiri pada SF-10 dan SF-100
- Streaming engine baru di Polars memberikan speedup tambahan 3-7x dibandingkan mode in-memory — memungkinkan pemrosesan data yang tidak muat di RAM
Untuk algotrading, ini berarti: jika pipeline Anda dibatasi memori saat memuat 100M+ baris data tick — streaming engine Polars memungkinkan Anda memprosesnya tanpa menambah RAM.
Komputasi Rolling untuk Sinyal Trading: Fitur Unggulan

Ini adalah benchmark terpenting untuk algotrading. Tugas tipikal: Anda memiliki 100 instrumen, dan untuk masing-masing perlu menghitung rolling mean, rolling std, z-score, dan menghasilkan sinyal berdasarkannya. Di Pandas ini adalah groupby().rolling(), di Polars ini adalah group_by().agg(col().rolling_mean()).
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling expressions
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
Hasil
| Operasi | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Rolling mean, 100 groups x 100K rows | 4200 | 12 | 350x |
| Rolling std, 100 groups x 100K rows | 5100 | 15 | 340x |
| Z-score (mean + std + arithmetic) | 12500 | 35 | 357x |
| Rolling mean, 1000 groups x 10K rows | 38000 | 11 | 3454x |
Speedup 10x hingga 3500x pada komputasi rolling per grup. Ini bukan typo. Pandas groupby().transform(lambda x: x.rolling().mean()) membuat loop Python atas setiap grup, dengan setiap panggilan menanggung overhead interpreter. Polars mengeksekusi semuanya di Rust, secara paralel antar grup, tanpa objek Python perantara.
Untuk pipeline yang perlu menghitung 10 indikator pada 100 instrumen — ini adalah perbedaan antara 2 menit dan 0,3 detik.
Indikator Teknis: Bollinger Bands, Keltner Channels, TTM Squeeze
 Bollinger Bands dan Keltner Channels membungkus rangkaian harga, dengan zona TTM Squeeze yang disorot
Bollinger Bands dan Keltner Channels membungkus rangkaian harga, dengan zona TTM Squeeze yang disorot
Mari kita periksa komputasi indikator teknis nyata yang digunakan dalam strategi trading.
Bollinger Bands
Implementasi Pandas
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
Implementasi Polars
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
Keltner Channels
di mana ATR (Average True Range):
TTM Squeeze
TTM Squeeze adalah metode untuk mengidentifikasi transisi pasar dari keadaan squeeze (volatilitas rendah) ke keadaan ekspansi. Sinyal terjadi ketika Bollinger Bands berada di dalam Keltner Channels:
Benchmark Indikator Teknis (1M baris, satu ticker)
| Indikator | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Bollinger Bands (20, 2) | 8.4 | 1.2 | 7.0x |
| Keltner Channels (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTM Squeeze (lengkap) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
Speedup konsisten ~7x pada satu ticker. Saat menghitung per grup (100 ticker), speedup tumbuh hingga ratusan kali lipat karena overhead groupby Pandas.
Catatan tentang Paket Indikator Siap Pakai
Untuk Pandas, tersedia pandas-ta — library dengan 130+ indikator. Untuk Polars, belum ada paket setara. Ini berarti saat menggunakan Polars, Anda perlu mengimplementasikan indikator sendiri. Namun, building block dasar (rolling_mean, rolling_std, ewm_mean, shift, aritmetika kolom) mencakup sebagian besar indikator standar, dan implementasi Polars biasanya lebih singkat dari yang terlihat.
Benchmark I/O: CSV, Parquet, Database
 Aliran data dari sumber CSV, Parquet, dan database: I/O Rust paralel versus Python single-thread
Aliran data dari sumber CSV, Parquet, dan database: I/O Rust paralel versus Python single-thread
Pipeline data dimulai dengan pemuatan data. Format penyimpanan dan metode pembacaan menentukan kecepatan dasar seluruh pipeline.
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Hasil I/O (10M baris, 6 kolom)
| Operasi | Pandas (s) | Polars (s) | Speedup |
|---|---|---|---|
| CSV read | 28.5 | 1.14 | 25.0x |
| CSV write | 42.0 | 2.8 | 15.0x |
| Parquet read (all columns) | 0.82 | 0.31 | 2.6x |
| Parquet read (3 of 6 columns) | 0.54 | 0.12 | 4.5x |
| Parquet write | 0.95 | 0.91 | 1.04x |
| Parquet lazy (filter + select) | N/A | 0.08 | predicate pushdown |
Poin-poin utama:
- CSV: Polars hingga 25x lebih cepat — parsing paralel di Rust
- Parquet read: Polars 2,6x lebih cepat pada pembacaan penuh dan 4,5x dengan projection pushdown (membaca hanya kolom yang dibutuhkan)
- Parquet write: hampir identik — keduanya menggunakan backend PyArrow/Arrow
- Lazy scan: Polars dapat menerapkan filter pada level row group file Parquet tanpa memuat data ke memori. Hal ini tidak mungkin dilakukan dengan Pandas tanpa menggunakan PyArrow secara manual
Untuk cache Parquet — format utama kami untuk menyimpan timeframe dan indikator yang telah dihitung sebelumnya — Polars dengan lazy evaluation menyediakan integrasi ideal: memuat hanya kolom dan periode yang dibutuhkan tanpa membaca seluruh file ke memori.
Konsumsi Memori dan Lazy Evaluation
 Pola memori eager vs lazy: salinan berlebihan berwarna oranye versus tata letak kolumnar Arrow yang dioptimalkan berwarna cyan
Pola memori eager vs lazy: salinan berlebihan berwarna oranye versus tata letak kolumnar Arrow yang dioptimalkan berwarna cyan
Eager vs Lazy
Pandas hanya bekerja dalam mode eager: setiap operasi dieksekusi langsung, dan hasil perantara dimaterialisasi di memori.
df = pd.read_csv("big_file.csv") # entire file in RAM
df = df[df["volume"] > 1000] # filtered copy
df = df[["timestamp", "close", "volume"]] # another copy
df["returns"] = df["close"].pct_change() # yet another copy
Polars mendukung lazy evaluation — query dibangun sebagai graf, dioptimalkan, dan dieksekusi dalam satu pass:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Optimizer Polars secara otomatis:
- Projection pushdown: membaca hanya 3 kolom alih-alih semuanya
- Predicate pushdown: menerapkan filter
volume > 1000selama pembacaan, tanpa memuat baris yang tidak diperlukan - Common subexpression elimination: menghindari komputasi hal yang sama dua kali
Konsumsi Memori (10M baris, 6 kolom float64)
| Skenario | Pandas (GB) | Polars eager (GB) | Polars lazy (GB) |
|---|---|---|---|
| CSV Load | 0.92 | 0.46 | 0.46 |
| Filter + Select 3 columns | 1.38* | 0.22 | 0.22 |
| Pipeline of 5 transformations | 2.76* | 0.48 | 0.48 |
| Parquet Load (3 of 6 cols) | 0.46 | 0.23 | 0.23 |
* Pandas membuat salinan perantara; inplace=True membantu sebagian, tetapi tidak untuk semua operasi.
Polars secara native menggunakan format kolumnar Arrow: data disimpan per kolom, baris tidak diduplikasi, dan operasi zero-copy digunakan di mana pun memungkinkan. Untuk pipeline dengan beberapa transformasi, Polars mengonsumsi memori 2-6x lebih sedikit.
Streaming Engine: Data Lebih Besar dari RAM
Untuk dataset yang tidak muat di RAM, Polars menawarkan streaming engine:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
Streaming engine memproses data dalam potongan tanpa memuat seluruh dataset ke memori. Menurut data benchmark PDS-H, mode streaming 3-7x lebih cepat dari in-memory pada skala besar — berkat lokalitas cache yang lebih baik dan tidak adanya tekanan memori virtual.
Arsitektur Hibrida: Polars + Numba
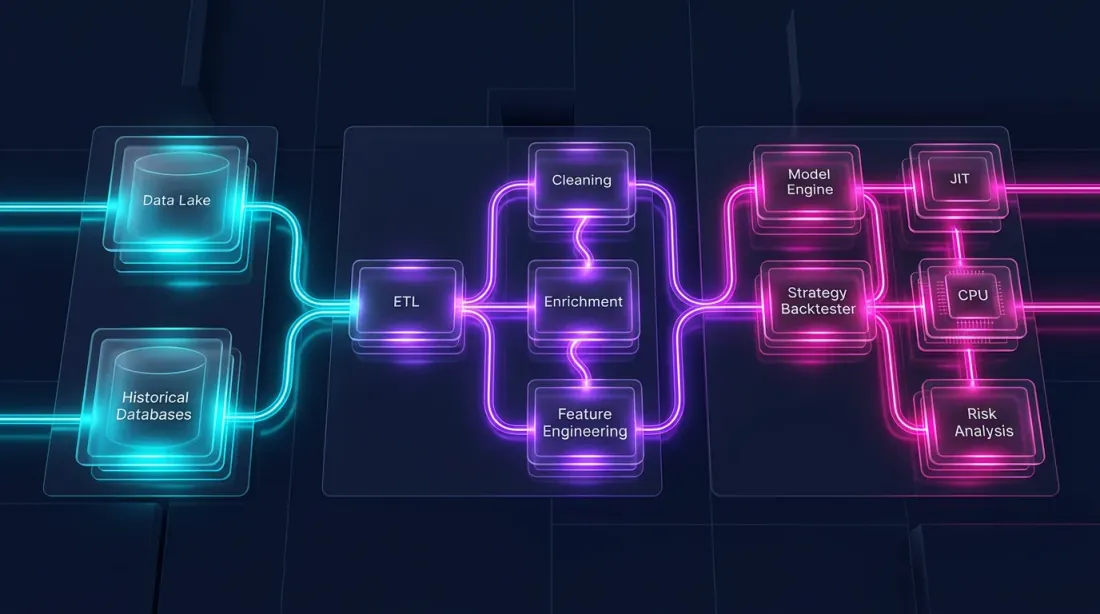
Sebuah backtest terdiri dari dua bagian yang secara fundamental berbeda:
-
Pipeline data — pemuatan, transformasi, indikator, filtering. Ini bersifat masif paralel, berorientasi kolom, dan sangat cocok untuk Polars.
-
Simulasi portofolio — pengisian order, komputasi PnL, manajemen posisi. Ini bersifat path-dependent: setiap langkah bergantung pada keadaan sebelumnya. Ini memerlukan pass elemen-per-elemen atas rangkaian waktu.
Pandas tidak cocok untuk kedua bagian tersebut. Polars unggul pada bagian pertama tetapi tidak yang kedua. Untuk logika path-dependent, alat optimal adalah Numba (kompiler JIT untuk Python) atau Rust/C++ native.
Arsitektur
┌─────────────────────────────────────────────────────┐
│ Data Pipeline │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Indicators │ │
│ │ │ Filters │ │
│ │ │ Features │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy arrays │
│ │ (zero-copy from Arrow) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portfolio Simulation (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
Contoh: Pipeline Lengkap
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy from Arrow
signals = df["signal"].to_numpy() # zero-copy from Arrow
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent simulation: Numba compiles to machine code.
1M iterations in 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
Mengapa Bukan vectorbt?
vectorbt adalah framework backtesting populer yang memproses 1 juta order dalam 70-100ms. Ini dibangun di atas Pandas + NumPy + Numba. Masalahnya: Pandas menjadi bottleneck dalam pipeline data — lambat, single-thread, rakus memori. vectorbt harus menyiasati keterbatasan Pandas melalui Numba untuk bagian kritis, tetapi pemuatan data dan komputasi indikator tetap melalui Pandas.
Arsitektur hibrida Polars + Numba mengambil yang terbaik dari keduanya:
- Polars untuk pipeline data — 5-350x lebih cepat dari Pandas pada operasi yang sama
- Numba untuk simulasi portofolio — kecepatan yang sama seperti di vectorbt
- Tanpa lapisan Pandas perantara — data mengalir dari Arrow langsung ke NumPy melalui zero-copy
Migrasi: Pola Utama dari Pandas ke Polars
 Jembatan antara kode lama dan modern: menerjemahkan pola Pandas ke ekspresi Polars
Jembatan antara kode lama dan modern: menerjemahkan pola Pandas ke ekspresi Polars
Jika pipeline Anda ditulis dalam Pandas, migrasi tidak memerlukan penulisan ulang dari awal. Pola utama dapat diterjemahkan melalui template.
Membaca Data
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # reads nothing until .collect()
Filtering
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
Membuat Kolom
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + Agregasi
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
Rolling per Grup
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
Integrasi dengan QuestDB
Polars secara native bekerja dengan Apache Arrow — format yang sama yang digunakan QuestDB untuk transfer data. Ini berarti zero-copy saat menerima hasil query:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # copy + type conversion
Untuk informasi lebih lanjut tentang bekerja dengan QuestDB untuk menyimpan dan menganalisis data trading, lihat seri artikel kami tentang arsitektur data.
Integrasi dengan Cache Parquet
 Cache Parquet kolumnar dengan predicate pushdown dan projection pushdown untuk pemuatan data selektif
Cache Parquet kolumnar dengan predicate pushdown dan projection pushdown untuk pemuatan data selektif
Dalam artikel Cache Parquet Teragregasi, kami menjelaskan cara menghitung timeframe dan indikator sekali dan menyimpannya ke file Parquet. Polars membuat pendekatan ini bahkan lebih efisien:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
Selama optimasi massal — ketika Anda perlu menjalankan ribuan kombinasi parameter — membaca dari cache Parquet melalui scan_parquet Polars dengan predicate pushdown memungkinkan memuat hanya periode dan kolom yang dibutuhkan tanpa membaca seluruh file.
Integrasi dengan Adaptive drill-down: lazy evaluation Polars sangat cocok untuk pemuatan dua tingkat — data kasar untuk pass utama, data detail (detik, milidetik) hanya untuk zona ambiguitas pengisian.
Kapan Menggunakan Apa: Rekomendasi Praktis
 Matriks keputusan: jalur berbeda untuk prototyping skala kecil versus pipeline produksi skala besar
Matriks keputusan: jalur berbeda untuk prototyping skala kecil versus pipeline produksi skala besar
Pandas dibenarkan jika:
- Dataset hingga 1M baris dan Anda tidak melakukan GroupBy atas ratusan grup — perbedaan antara Pandas 2.2 dan Polars sering kali dapat diabaikan (1,5-2x)
- Anda memerlukan
pandas-taatau library lain dengan Pandas API — menulis ulang 130 indikator tidak praktis untuk studi sekali pakai - Prototyping — Pandas API lebih familiar bagi sebagian besar orang, dan kecepatan tidak kritis untuk pengujian hipotesis cepat
- Integrasi dengan kode lama — pipeline Pandas yang ada, berfungsi, dan tidak perlu dioptimalkan
Polars diperlukan jika:
- Dataset dari 10M baris — puluhan dan ratusan juta baris data tick, cache multi-timeframe
- Rolling per grup — 100+ instrumen, indikator untuk masing-masing: speedup 100-3500x
- Pipeline ETL — pemuatan, pembersihan, transformasi volume data besar
- RAM terbatas — lazy evaluation dan streaming engine memungkinkan pemrosesan data yang tidak muat di memori
- Stack Parquet/QuestDB — Arrow native = zero-copy, predicate pushdown, projection pushdown
Yang Tidak Perlu Diharapkan
Angka pemasaran "30x lebih cepat" adalah speedup puncak pada operasi tertentu. Speedup realistis pada operasi pipeline tipikal: 2-10x. Pada rolling per grup — jauh lebih besar. Pada dataset kecil — kadang Polars bahkan lebih lambat karena overhead.
Pengalaman Kami di marketmaker.cc
 Metrik produksi: speedup pipeline 6-8x dan 8x lebih banyak iterasi optimasi per jam
Metrik produksi: speedup pipeline 6-8x dan 8x lebih banyak iterasi optimasi per jam
Di marketmaker.cc, kami menggunakan arsitektur hibrida Polars + Numba untuk engine backtest. Seluruh pipeline data — pemuatan dari cache Parquet, komputasi indikator, filtering, feature engineering — berjalan di Polars. Simulasi portofolio berjalan di Numba.
Beralih dari Pandas ke Polars dalam pipeline data memberikan speedup 6-8x pada dataset tipikal kami (50-100 juta baris, 200+ instrumen). Komputasi indikator rolling per grup berubah dari hitungan menit menjadi ratusan milidetik. Ini memungkinkan kami meningkatkan jumlah iterasi optimasi dari ~500 menjadi ~4000 per jam tanpa mengganti perangkat keras.
Poin kunci: kami tidak memigrasikan semua kode dalam satu hari. Pertama kami memindahkan I/O (membaca Parquet), kemudian komputasi indikator, kemudian filtering dan feature engineering. Pandas tetap hanya pada antarmuka dengan komponen lama yang mengharapkan pd.DataFrame. Konversi df.to_pandas() / pl.from_pandas() memakan waktu milidetik dan bukan bottleneck.
Metrik yang dihitung selama tahap backtest — termasuk PnL berdasarkan Waktu Aktif — sudah dihitung pada Polars DataFrames, yang menyederhanakan pipeline dan menghilangkan konversi perantara.
Kesimpulan
 Tiga aliran teknologi menyatu: Polars, Numba, dan Arrow bersatu menjadi satu pipeline yang dioptimalkan
Tiga aliran teknologi menyatu: Polars, Numba, dan Arrow bersatu menjadi satu pipeline yang dioptimalkan
Polars bukan pengganti Pandas dalam setiap skenario. Ini adalah alat dari kelas yang berbeda yang bersinar pada skala yang khas untuk algotrading serius: jutaan dan ratusan juta baris, puluhan dan ratusan instrumen, optimasi parameter yang berkelanjutan.
Angka-angka kunci:
- Operasi dasar: speedup 2-10x pada tugas pipeline tipikal
- Rolling per grup: 10-3500x — fitur pembunuh utama untuk pipeline trading
- I/O CSV: hingga 25x — kritis untuk pemuatan data awal
- Memori: penghematan 2-6x berkat Arrow dan lazy evaluation
- Streaming: pemrosesan data yang tidak muat di RAM
Arsitektur yang direkomendasikan untuk engine backtest produksi:
- Polars — seluruh pipeline data: pemuatan, indikator, filtering, fitur
- Numba/Rust — simulasi portofolio: logika order dan posisi yang path-dependent
- Arrow — format data di semua persimpangan: Parquet, QuestDB, Polars, NumPy
Tanpa lapisan Pandas perantara. Data mengalir dari penyimpanan melalui Polars ke array NumPy dan kemudian ke engine Numba — tanpa salinan yang tidak perlu, tanpa GIL, tanpa bottleneck single-thread.
Tautan Berguna
- Polars — User Guide
- Polars vs Pandas — official benchmark
- PDS-H Benchmark — DataFrame libraries comparison
- Apache Arrow — columnar format specification
- Numba — JIT compiler for Python
- vectorbt — backtesting framework
- pandas-ta — Technical Analysis Indicators
- Ritchie Vink — I wrote one of the fastest DataFrame libraries (Polars origin)
- Towards Data Science — Polars vs Pandas: real-world benchmarks
- Ernest Chan — Quantitative Trading
Kutipan
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/id/blog/post/polars-vs-pandas-algotrading},
description = {Perbandingan mendetail Polars dan Pandas pada tugas algotrading: benchmark untuk filtering, agregasi, komputasi sinyal rolling, I/O, dan konsumsi memori. Arsitektur hibrida Polars + Numba untuk performa backtest maksimal.}
}
Penulis

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Selengkapnya
OneTick: Platform Tempat Bursa Menangkap Spoofer dan Hedge Fund Memburu Alpha

T-Bricks (Broadridge): Cara Kerja Platform yang Digunakan Prop Firm