Polars vs Pandas untuk Algotrading: Penanda Aras pada Data Sebenar

Siri "Backtest Tanpa Ilusi", Artikel 9
Backtest strategi bukan sekadar logik isyarat dan simulasi pelaksanaan. Ia juga merupakan saluran data: memuatkan jutaan lilin, mengambil semula jangka masa, mengira penunjuk, menapis mengikut syarat, mengumpulkan mengikut instrumen. Apabila saluran mengambil masa 30 saat berbanding 3 saat, ia bukan sekadar ketidakselesaan. Ia bermakna 10x lebih sedikit eksperimen sejam, 10x lebih perlahan pengulangan, dan 10x lebih panjang laluan dari idea ke pengeluaran.
Pandas adalah piawaian de facto untuk data jadual dalam Python. Tetapi Pandas direka pada tahun 2008, apabila teras CPU lebih perlahan dan set data lebih kecil. Pandas adalah satu benang, memerlukan banyak memori, dan tiada pengoptimum pertanyaan. Polars adalah perpustakaan generasi seterusnya yang ditulis dalam Rust, dengan pelaksanaan selari, Apache Arrow sebagai terasnya, dan perancang pertanyaan malas.
Soalannya: berapa banyak lebih cepat Polars pada tugas algotrading sebenar? Bukan pada penanda aras sintetik dari README, tetapi pada penapisan tik, pengiraan penunjuk bergulir, pengelompokan mengikut instrumen, dan pemuatan dari Parquet/QuestDB?
Artikel ini menyediakan penanda aras sistematik dengan nombor, kod, dan cadangan praktikal.
Metodologi Penanda Aras
 Makmal pengukuran futuristik: persekitaran penanda aras ketepatan dengan parameter terkawal
Makmal pengukuran futuristik: persekitaran penanda aras ketepatan dengan parameter terkawal
Sebelum membandingkan, mari kita tetapkan peraturan supaya hasil boleh diulang dan adil.
Persekitaran
- Python 3.11, Pandas 2.2, Polars 1.x (versi stabil terkini)
- Mesin: 8 teras, 32 GB RAM, NVMe SSD
- Setiap penanda aras dijalankan 100 kali; nilai median diambil
- Pemanasan: 5 lelaran sebelum pengukuran
- GC dilumpuhkan semasa pengukuran (
gc.disable())
Data
Tiga tahap skala:
- Kecil: 10K baris (satu instrumen, satu hari, lilin minit)
- Sederhana: 1M baris (satu instrumen, ~2 tahun, lilin minit)
- Besar: 10M+ baris (100 instrumen, 2 tahun, lilin minit)
Tambahan: set data NYC Taxi sebenar (12.7M baris) untuk penanda aras ETL — penanda aras standard industri.
Apa yang Kami Ukur
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Fair benchmark: warmup + median of n runs."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
Penanda Aras Operasi: Jadual
 Perbandingan prestasi merentasi operasi: filter, groupby, join, dan select pada skala data berbeza
Perbandingan prestasi merentasi operasi: filter, groupby, join, dan select pada skala data berbeza
Set data kecil (10K baris)
| Operasi | Pandas (ms) | Polars (ms) | Pelajaran |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
Pada 10K baris, Pandas kadangkala lebih cepat pada penapis mudah — overhed memanggil fungsi Polars melalui PyO3 setanding dengan masa operasi itu sendiri. Tetapi pada join, kelebihan sudah kelihatan: jadual cincang Polars dalam Rust adalah 13x lebih cepat.
Set data sederhana (1M baris)
| Operasi | Pandas (ms) | Polars (ms) | Pelajaran |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
Pada satu juta baris, Polars secara konsisten 1.6x lebih cepat pada penapisan dan pengelompokan. Pada select (memilih subset lajur) — 10.9x, kerana format lajur Arrow membenarkan hirisan sifar-salin.
Set data besar (10M+ baris)
| Operasi | Pandas (ms) | Polars (ms) | Pelajaran |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
Pada data besar, kelebihan Polars berkembang secara tidak linear: pelaksanaan selari pada 8 teras dan pengoptimum pertanyaan menghasilkan kesan kumulatif. GroupBy adalah 8.6x lebih cepat — perbezaan antara "menunggu satu saat" dan "menunggu 100 milisaat."
ETL pada Data Sebenar (NYC Taxi, 12.7M baris)
| Operasi | Pandas (s) | Polars (s) | Pelajaran |
|---|---|---|---|
| Muatan CSV | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| Transformasi berbilang lajur | 2.1 | 0.7 | 3.0x |
| Saluran ETL penuh | 34.4 | 2.26 | 15.2x |
I/O CSV adalah hasil paling dramatik: Polars membaca CSV secara selari pada enjin Rustnya, 25x lebih cepat. Ini kritikal untuk pemuatan awal data sejarah.
Penanda Aras Rasmi PDS-H (Mei 2025)
 Perlumbaan prestasi perpustakaan DataFrame: Polars dan DuckDB memimpin sementara Pandas ketinggalan beberapa magnitud
Perlumbaan prestasi perpustakaan DataFrame: Polars dan DuckDB memimpin sementara Pandas ketinggalan beberapa magnitud
PDS-H (Performance Data Science — Holistic) adalah penanda aras standard untuk perpustakaan DataFrame, analog kepada TPC-H untuk pangkalan data. Keputusan dari Mei 2025:
- Pandas hanya menyertai pada skala SF-10 — satu benang, tiada pengoptimum pertanyaan, dua magnitud lebih perlahan daripada pemimpin
- Polars dan DuckDB berada dalam liga tersendiri pada SF-10 dan SF-100
- Enjin penstriman baharu dalam Polars memberikan 3-7x laju tambahan berbanding mod dalam memori — membolehkan pemprosesan data yang tidak muat dalam RAM
Untuk algotrading, ini bermakna: jika saluran anda terikat memori ketika memuatkan 100M+ baris data tik — enjin penstriman Polars membolehkan anda memprosesnya tanpa menambah RAM.
Pengiraan Bergulir untuk Isyarat Dagangan: Ciri Pembunuh

Ini adalah penanda aras paling penting untuk algotrading. Tugas tipikal: anda mempunyai 100 instrumen, dan untuk setiap satu anda perlu mengira min bergulir, std bergulir, z-score, dan menghasilkan isyarat berdasarkan mereka. Dalam Pandas ini adalah groupby().rolling(), dalam Polars ia adalah group_by().agg(col().rolling_mean()).
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling expressions
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
Keputusan
| Operasi | Pandas (ms) | Polars (ms) | Pelajaran |
|---|---|---|---|
| Rolling mean, 100 kumpulan x 100K baris | 4200 | 12 | 350x |
| Rolling std, 100 kumpulan x 100K baris | 5100 | 15 | 340x |
| Z-score (min + std + aritmetik) | 12500 | 35 | 357x |
| Rolling mean, 1000 kumpulan x 10K baris | 38000 | 11 | 3454x |
10x hingga 3500x pelajaran pada pengiraan bergulir mengikut kumpulan. Ini bukan kesilapan taip. Pandas groupby().transform(lambda x: x.rolling().mean()) mencipta gelung Python merentasi setiap kumpulan, dengan setiap panggilan menanggung overhed penterjemah. Polars melaksanakan semuanya dalam Rust, secara selari merentasi kumpulan, tanpa objek Python perantaraan.
Untuk saluran yang perlu mengira 10 penunjuk merentasi 100 instrumen — ini adalah perbezaan antara 2 minit dan 0.3 saat.
Penunjuk Teknikal: Bollinger Bands, Keltner Channels, TTM Squeeze
 Bollinger Bands dan Keltner Channels menyelubungi siri harga, dengan zon TTM Squeeze diserlahkan
Bollinger Bands dan Keltner Channels menyelubungi siri harga, dengan zon TTM Squeeze diserlahkan
Mari kita kaji pengiraan penunjuk teknikal sebenar yang digunakan dalam strategi dagangan.
Bollinger Bands
Pelaksanaan Pandas
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
Pelaksanaan Polars
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
Keltner Channels
di mana ATR (Average True Range):
TTM Squeeze
TTM Squeeze adalah kaedah untuk mengenal pasti peralihan pasaran dari keadaan tekanan (volatiliti rendah) ke keadaan pengembangan. Isyarat berlaku apabila Bollinger Bands berada di dalam Keltner Channels:
Penanda Aras Penunjuk Teknikal (1M baris, satu tiker)
| Penunjuk | Pandas (ms) | Polars (ms) | Pelajaran |
|---|---|---|---|
| Bollinger Bands (20, 2) | 8.4 | 1.2 | 7.0x |
| Keltner Channels (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTM Squeeze (penuh) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
Pelajaran yang konsisten ~7x pada satu tiker. Apabila mengira mengikut kumpulan (100 tiker), pelajaran meningkat ke ratusan kali ganda akibat overhed groupby Pandas.
Nota tentang Pakej Penunjuk Sedia Ada
Untuk Pandas, terdapat pandas-ta — perpustakaan dengan 130+ penunjuk. Untuk Polars, tiada pakej setara lagi. Ini bermakna apabila menggunakan Polars, anda perlu melaksanakan penunjuk sendiri. Walau bagaimanapun, blok binaan asas (rolling_mean, rolling_std, ewm_mean, shift, aritmetik lajur) meliputi sebahagian besar penunjuk standard, dan pelaksanaan Polars biasanya lebih pendek daripada yang disangkakan.
Penanda Aras I/O: CSV, Parquet, Pangkalan Data
 Aliran data dari sumber CSV, Parquet, dan pangkalan data: I/O Rust selari berbanding Python satu benang
Aliran data dari sumber CSV, Parquet, dan pangkalan data: I/O Rust selari berbanding Python satu benang
Saluran data bermula dengan pemuatan data. Format storan dan kaedah pembacaan menentukan kelajuan asas keseluruhan saluran.
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Keputusan I/O (10M baris, 6 lajur)
| Operasi | Pandas (s) | Polars (s) | Pelajaran |
|---|---|---|---|
| Baca CSV | 28.5 | 1.14 | 25.0x |
| Tulis CSV | 42.0 | 2.8 | 15.0x |
| Baca Parquet (semua lajur) | 0.82 | 0.31 | 2.6x |
| Baca Parquet (3 dari 6 lajur) | 0.54 | 0.12 | 4.5x |
| Tulis Parquet | 0.95 | 0.91 | 1.04x |
| Parquet lazy (filter + select) | N/A | 0.08 | predicate pushdown |
Kesimpulan utama:
- CSV: Polars sehingga 25x lebih cepat — penghuraian selari dalam Rust
- Baca Parquet: Polars adalah 2.6x lebih cepat pada pembacaan penuh dan 4.5x dengan projection pushdown (membaca hanya lajur yang diperlukan)
- Tulis Parquet: hampir sama — kedua-duanya menggunakan backend PyArrow/Arrow
- Imbasan malas: Polars boleh menerapkan penapis pada tahap kumpulan baris fail Parquet tanpa memuatkan data ke dalam memori. Ini mustahil dengan Pandas tanpa menggunakan PyArrow secara manual
Untuk cache Parquet — format utama kami untuk menyimpan jangka masa dan penunjuk yang telah dikira — Polars dengan penilaian malas menyediakan integrasi ideal: memuatkan hanya lajur dan tempoh yang diperlukan tanpa membaca keseluruhan fail ke dalam memori.
Penggunaan Memori dan Penilaian Malas
 Corak memori eager berbanding lazy: salinan berlebihan dalam oren berbanding susun atur lajur Arrow yang dioptimumkan dalam sian
Corak memori eager berbanding lazy: salinan berlebihan dalam oren berbanding susun atur lajur Arrow yang dioptimumkan dalam sian
Eager vs Lazy
Pandas hanya berfungsi dalam mod eager: setiap operasi dilaksanakan segera, dan hasil perantaraan diwujudkan dalam memori.
df = pd.read_csv("big_file.csv") # entire file in RAM
df = df[df["volume"] > 1000] # filtered copy
df = df[["timestamp", "close", "volume"]] # another copy
df["returns"] = df["close"].pct_change() # yet another copy
Polars menyokong penilaian malas — pertanyaan dibina sebagai graf, dioptimumkan, dan dilaksanakan dalam satu laluan:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Pengoptimum Polars secara automatik:
- Projection pushdown: membaca hanya 3 lajur bukannya semua
- Predicate pushdown: menerapkan penapis
volume > 1000semasa pembacaan, tanpa memuatkan baris yang tidak perlu - Penghapusan subungkapan biasa: mengelak mengira perkara yang sama dua kali
Penggunaan Memori (10M baris, 6 lajur float64)
| Senario | Pandas (GB) | Polars eager (GB) | Polars lazy (GB) |
|---|---|---|---|
| Muatan CSV | 0.92 | 0.46 | 0.46 |
| Filter + Select 3 lajur | 1.38* | 0.22 | 0.22 |
| Saluran 5 transformasi | 2.76* | 0.48 | 0.48 |
| Muatan Parquet (3 dari 6 lajur) | 0.46 | 0.23 | 0.23 |
* Pandas mencipta salinan perantaraan; inplace=True membantu sebahagiannya, tetapi tidak untuk semua operasi.
Polars secara asalnya menggunakan format lajur Arrow: data disimpan mengikut lajur, baris tidak diduplikasi, dan operasi sifar-salin digunakan di mana sahaja. Untuk saluran dengan pelbagai transformasi, Polars menggunakan memori 2-6x lebih sedikit.
Enjin Penstriman: Data Lebih Besar daripada RAM
Untuk set data yang tidak muat dalam RAM, Polars menawarkan enjin penstriman:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
Enjin penstriman memproses data dalam kepingan tanpa memuatkan keseluruhan set data ke dalam memori. Menurut data penanda aras PDS-H, mod penstriman adalah 3-7x lebih cepat daripada dalam memori pada skala besar — berkat lokaliti cache yang lebih baik dan ketiadaan tekanan memori maya.
Seni Bina Hibrid: Polars + Numba
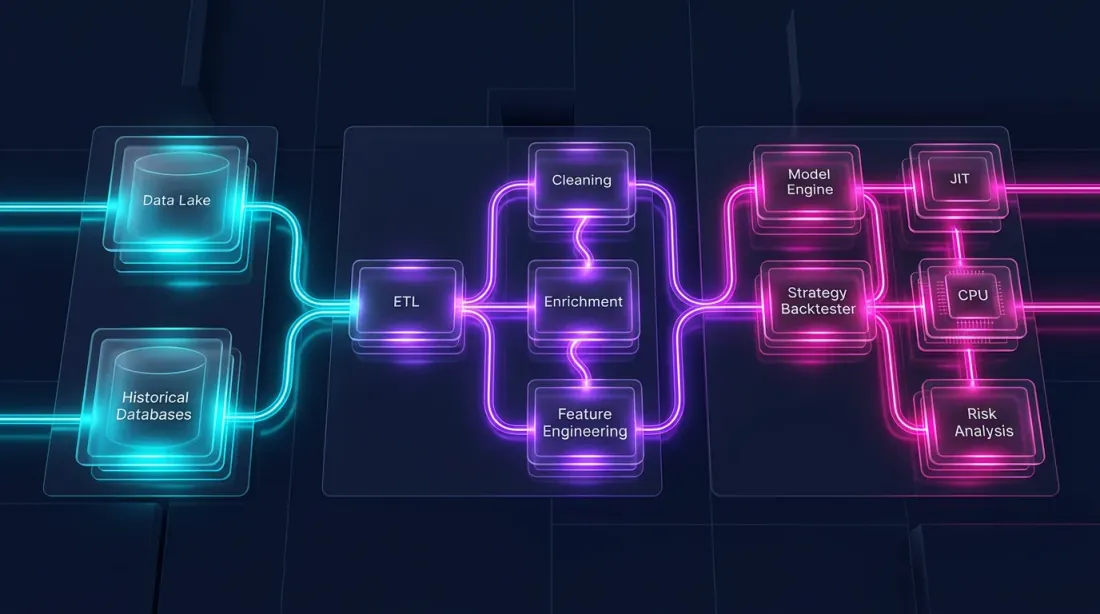
Backtest terdiri daripada dua bahagian yang berbeza asasnya:
-
Saluran data — pemuatan, transformasi, penunjuk, penapisan. Ini adalah sangat selari, berorientasikan lajur, dan sesuai sempurna untuk Polars.
-
Simulasi portfolio — pengisian pesanan, pengiraan PnL, pengurusan kedudukan. Ini bergantung pada laluan: setiap langkah bergantung pada keadaan sebelumnya. Ini memerlukan laluan berasaskan elemen merentasi siri masa.
Pandas tidak sesuai untuk kedua-dua bahagian. Polars cemerlang pada yang pertama tetapi bukan yang kedua. Untuk logik bergantung laluan, alat optimum adalah Numba (pengkompil JIT untuk Python) atau Rust/C++ asli.
Seni Bina
┌─────────────────────────────────────────────────────┐
│ Data Pipeline │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Indicators │ │
│ │ │ Filters │ │
│ │ │ Features │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy arrays │
│ │ (zero-copy from Arrow) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portfolio Simulation (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
Contoh: Saluran Penuh
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy from Arrow
signals = df["signal"].to_numpy() # zero-copy from Arrow
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent simulation: Numba compiles to machine code.
1M iterations in 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
Mengapa Bukan vectorbt?
vectorbt adalah rangka kerja backtesting popular yang memproses 1M pesanan dalam 70-100ms. Ia dibina di atas Pandas + NumPy + Numba. Masalahnya: Pandas adalah kesesakan dalam saluran data — perlahan, satu benang, memerlukan banyak memori. vectorbt terpaksa mengelakkan batasan Pandas melalui Numba untuk bahagian kritikal, tetapi pemuatan data dan pengiraan penunjuk masih melalui Pandas.
Seni bina hibrid Polars + Numba mengambil yang terbaik dari kedua-dua dunia:
- Polars untuk saluran data — 5-350x lebih cepat daripada Pandas pada operasi yang sama
- Numba untuk simulasi portfolio — kelajuan yang sama seperti dalam vectorbt
- Tiada lapisan Pandas perantaraan — data mengalir dari Arrow terus ke NumPy melalui sifar-salin
Migrasi: Corak Utama dari Pandas ke Polars
 Jambatan antara kod lama dan moden: menterjemahkan corak Pandas ke ungkapan Polars
Jambatan antara kod lama dan moden: menterjemahkan corak Pandas ke ungkapan Polars
Jika saluran anda ditulis dalam Pandas, migrasi tidak memerlukan penulisan semula dari awal. Corak utama diterjemahkan melalui templat.
Membaca Data
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # reads nothing until .collect()
Penapisan
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
Mencipta Lajur
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + Pengagregatan
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
Rolling mengikut Kumpulan
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
Integrasi dengan QuestDB
Polars secara asalnya berfungsi dengan Apache Arrow — format yang sama yang digunakan QuestDB untuk pemindahan data. Ini bermakna sifar-salin apabila menerima keputusan pertanyaan:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # copy + type conversion
Untuk maklumat lanjut tentang bekerja dengan QuestDB untuk menyimpan dan menganalisis data dagangan, lihat siri artikel kami tentang seni bina data.
Integrasi dengan Cache Parquet
 Cache Parquet lajur dengan predicate pushdown dan projection pushdown untuk pemuatan data selektif
Cache Parquet lajur dengan predicate pushdown dan projection pushdown untuk pemuatan data selektif
Dalam artikel Cache Parquet Teragregat, kami menerangkan cara mengira jangka masa dan penunjuk sekali dan menyimpannya ke fail Parquet. Polars menjadikan pendekatan ini lebih cekap lagi:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
Semasa pengoptimuman besar-besaran — apabila anda perlu menjalankan ribuan kombinasi parameter — membaca dari cache Parquet melalui Polars scan_parquet dengan predicate pushdown membolehkan pemuatan hanya tempoh dan lajur yang diperlukan tanpa membaca keseluruhan fail.
Integrasi dengan Drill-down adaptif: penilaian malas Polars sesuai sempurna untuk pemuatan dua peringkat — data kasar untuk laluan utama, data terperinci (saat, milisaat) hanya untuk zon kekaburan pengisian.
Bila Menggunakan Apa: Cadangan Praktikal
 Matriks keputusan: laluan berbeza untuk prototaip skala kecil berbanding saluran pengeluaran skala besar
Matriks keputusan: laluan berbeza untuk prototaip skala kecil berbanding saluran pengeluaran skala besar
Pandas wajar jika:
- Set data sehingga 1M baris dan anda tidak melakukan GroupBy merentasi ratusan kumpulan — perbezaan antara Pandas 2.2 dan Polars sering tidak ketara (1.5-2x)
- Anda memerlukan
pandas-taatau perpustakaan lain dengan API Pandas — menulis semula 130 penunjuk adalah tidak praktikal untuk kajian sekali sahaja - Prototaip — API Pandas lebih biasa kepada kebanyakan orang, dan kelajuan tidak kritikal untuk ujian hipotesis pantas
- Integrasi dengan kod lama — saluran Pandas sedia ada yang berfungsi dan tidak memerlukan pengoptimuman
Polars diperlukan jika:
- Set data dari 10M baris — puluhan dan ratusan juta baris data tik, cache berbilang jangka masa
- Rolling mengikut kumpulan — 100+ instrumen, penunjuk untuk setiap satu: pelajaran 100-3500x
- Saluran ETL — memuatkan, membersihkan, mengubah suai jumlah data yang besar
- RAM terhad — penilaian malas dan enjin penstriman membolehkan pemprosesan data yang tidak muat dalam memori
- Tindanan Parquet/QuestDB — Arrow asli = sifar-salin, predicate pushdown, projection pushdown
Apa yang Tidak Perlu Dijangka
Angka pemasaran "30x lebih cepat" adalah pelajaran puncak pada operasi tertentu. Pelajaran realistik pada operasi saluran tipikal: 2-10x. Pada rolling mengikut kumpulan — jauh lebih banyak. Pada set data kecil — kadangkala Polars malah lebih perlahan akibat overhed.
Pengalaman Kami di marketmaker.cc
 Metrik pengeluaran: pelajaran saluran 6-8x dan 8x lebih banyak lelaran pengoptimuman sejam
Metrik pengeluaran: pelajaran saluran 6-8x dan 8x lebih banyak lelaran pengoptimuman sejam
Di marketmaker.cc, kami menggunakan seni bina hibrid Polars + Numba untuk enjin backtest. Keseluruhan saluran data — pemuatan dari cache Parquet, pengiraan penunjuk, penapisan, kejuruteraan ciri — berjalan pada Polars. Simulasi portfolio berjalan pada Numba.
Bertukar dari Pandas ke Polars dalam saluran data memberikan pelajaran 6-8x pada set data tipikal kami (50-100M baris, 200+ instrumen). Pengiraan penunjuk bergulir mengikut kumpulan berubah dari minit ke ratusan milisaat. Ini membolehkan kami meningkatkan bilangan lelaran pengoptimuman dari ~500 ke ~4000 sejam tanpa menukar perkakasan.
Perkara utama: kami tidak memindahkan semua kod dalam satu hari. Pertama kami memindahkan I/O (membaca Parquet), kemudian pengiraan penunjuk, kemudian penapisan dan kejuruteraan ciri. Pandas kekal hanya dalam antara muka dengan komponen lama yang menjangkakan pd.DataFrame. Penukaran df.to_pandas() / pl.from_pandas() mengambil milisaat dan bukan kesesakan.
Metrik yang dikira semasa peringkat backtest — termasuk PnL mengikut Masa Aktif — sudah dikira pada DataFrames Polars, yang memudahkan saluran dan menghapuskan penukaran perantaraan.
Kesimpulan
 Tiga aliran teknologi menggabungkan: Polars, Numba, dan Arrow bersatu menjadi satu saluran yang dioptimumkan
Tiga aliran teknologi menggabungkan: Polars, Numba, dan Arrow bersatu menjadi satu saluran yang dioptimumkan
Polars bukan pengganti Pandas dalam setiap senario. Ia adalah alat kelas berbeza yang bersinar pada skala yang tipikal untuk algotrading serius: jutaan dan ratusan juta baris, puluhan dan ratusan instrumen, pengoptimuman parameter yang berterusan.
Nombor utama:
- Operasi asas: pelajaran 2-10x pada tugas saluran tipikal
- Rolling mengikut kumpulan: 10-3500x — ciri pembunuh utama untuk saluran dagangan
- I/O CSV: sehingga 25x — kritikal untuk pemuatan data awal
- Memori: penjimatan 2-6x berkat Arrow dan penilaian malas
- Penstriman: memproses data yang tidak muat dalam RAM
Seni bina yang disyorkan untuk enjin backtest pengeluaran:
- Polars — keseluruhan saluran data: pemuatan, penunjuk, penapisan, ciri
- Numba/Rust — simulasi portfolio: logik pesanan dan kedudukan bergantung laluan
- Arrow — format data pada semua persimpangan: Parquet, QuestDB, Polars, NumPy
Tiada lapisan Pandas perantaraan. Data mengalir dari storan melalui Polars ke tatasusunan NumPy dan kemudian ke enjin Numba — tanpa salinan yang tidak perlu, tanpa GIL, tanpa kesesakan satu benang.
Pautan Berguna
- Polars — Panduan Pengguna
- Polars vs Pandas — penanda aras rasmi
- Penanda Aras PDS-H — perbandingan perpustakaan DataFrame
- Apache Arrow — spesifikasi format lajur
- Numba — pengkompil JIT untuk Python
- vectorbt — rangka kerja backtesting
- pandas-ta — Penunjuk Analisis Teknikal
- Ritchie Vink — Saya menulis salah satu perpustakaan DataFrame terpantas (asal usul Polars)
- Towards Data Science — Polars vs Pandas: penanda aras dunia sebenar
- Ernest Chan — Dagangan Kuantitatif
Petikan
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/ms/blog/post/polars-vs-pandas-algotrading},
description = {Perbandingan terperinci Polars dan Pandas pada tugas algotrading: penanda aras untuk penapisan, pengagregatan, pengiraan isyarat bergulir, I/O, dan penggunaan memori. Seni bina hibrid Polars + Numba untuk prestasi backtest yang maksimum.}
}
Pengarang

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Lagi

T-Bricks (Broadridge): Cara Platform yang Menjanakan Prop Firms Berfungsi
Fincept Terminal: Alternatif Terminal Bloomberg Sumber Terbuka Dibina dengan C++ dan AI