Algotrading için Polars ve Pandas: Gerçek Verilerle Karşılaştırmalı Testler

"Yanılsamasız Backtestler" Serisi, 9. Makale
Strateji backtesti yalnızca sinyal mantığı ve işlem simülasyonundan ibaret değildir. Aynı zamanda bir veri hattıdır: milyonlarca mum yüklemek, zaman dilimlerini yeniden örneklemek, göstergeler hesaplamak, koşullara göre filtrelemek, enstrümanlara göre gruplamak. Hattın 3 saniye yerine 30 saniye sürmesi yalnızca bir rahatsızlık değildir. Bu, saatte 10 kat daha az deney, 10 kat daha yavaş iterasyon ve fikirden üretime 10 kat daha uzun bir yol anlamına gelir.
Pandas, Python'da tablo verileri için fiili standarttır. Ancak Pandas, CPU çekirdeklerinin daha yavaş ve veri kümelerinin daha küçük olduğu 2008 yılında tasarlandı. Pandas tek iş parçacıklıdır, bellek açısından aç gözlüdür ve sorgu iyileştiriciden yoksundur. Polars ise Rust ile yazılmış, paralel yürütme, özünde Apache Arrow ve tembel sorgu planlayıcısına sahip yeni nesil bir kütüphanedir.
Soru şu: Polars gerçek algotrading görevlerinde ne kadar daha hızlı? README'deki sentetik karşılaştırmalı testlerde değil, tick filtreleme, kayan pencere göstergesi hesaplama, enstrümanlara göre gruplama ve Parquet/QuestDB'den yükleme işlemlerinde?
Bu makale, sayılar, kod ve pratik önerilerle sistematik karşılaştırmalı testler sunmaktadır.
Karşılaştırmalı Test Metodolojisi
 Fütüristik ölçüm laboratuvarı: kontrollü parametrelerle hassas karşılaştırmalı test ortamı
Fütüristik ölçüm laboratuvarı: kontrollü parametrelerle hassas karşılaştırmalı test ortamı
Karşılaştırmadan önce, sonuçların tekrarlanabilir ve adil olması için kuralları tanımlayalım.
Ortam
- Python 3.11, Pandas 2.2, Polars 1.x (en son kararlı sürüm)
- Makine: 8 çekirdek, 32 GB RAM, NVMe SSD
- Her karşılaştırmalı test 100 kez çalıştırılır; medyan alınır
- Isınma: ölçümlerden önce 5 iterasyon
- Ölçüm sırasında GC devre dışı (
gc.disable())
Veriler
Üç ölçek düzeyi:
- Küçük: 10K satır (bir enstrüman, bir gün, dakikalık mumlar)
- Orta: 1M satır (bir enstrüman, ~2 yıl, dakikalık mumlar)
- Büyük: 10M+ satır (100 enstrüman, 2 yıl, dakikalık mumlar)
Ayrıca: ETL karşılaştırmalı testleri için gerçek NYC Taxi veri kümesi (12,7M satır) — standart sektör karşılaştırmalı testi.
Ne Ölçüyoruz
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Adil karşılaştırmalı test: ısınma + n çalıştırmanın medyanı."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
İşlem Karşılaştırmalı Testleri: Tablolar
 Farklı veri ölçeklerinde filtre, groupby, join ve select genelinde performans karşılaştırması
Farklı veri ölçeklerinde filtre, groupby, join ve select genelinde performans karşılaştırması
Küçük veri kümeleri (10K satır)
| İşlem | Pandas (ms) | Polars (ms) | Hız Farkı |
|---|---|---|---|
| Filtre | 0,18 | 0,32 | 0,56x |
| GroupBy | 1,2 | 0,75 | 1,6x |
| Join | 5,5 | 0,4 | 13,75x |
| Select | 0,5 | 0,2 | 2,5x |
10K satırda Pandas, basit filtrelerde bazen daha hızlıdır — PyO3 üzerinden bir Polars fonksiyonu çağırmanın ek yükü, işlemin kendi süresiyle karşılaştırılabilir düzeydedir. Ancak join işlemlerinde avantaj zaten görünür: Rust'taki Polars hash tablosu 13x daha hızlıdır.
Orta veri kümeleri (1M satır)
| İşlem | Pandas (ms) | Polars (ms) | Hız Farkı |
|---|---|---|---|
| Filtre | 12,4 | 7,8 | 1,6x |
| GroupBy | 45,2 | 28,6 | 1,6x |
| Join | 89,0 | 14,3 | 6,2x |
| Select | 21,8 | 2,0 | 10,9x |
Bir milyon satırda Polars, filtreleme ve gruplamayla tutarlı biçimde 1,6x daha hızlıdır. Select işleminde (sütunların bir alt kümesini seçmek) — 10,9x, çünkü Arrow sütunlu biçimi sıfır kopyalı dilimlemeye olanak tanır.
Büyük veri kümeleri (10M+ satır)
| İşlem | Pandas (ms) | Polars (ms) | Hız Farkı |
|---|---|---|---|
| Filtre | 185 | 50 | 3,7x |
| GroupBy | 860 | 100 | 8,6x |
| Join | 1450 | 120 | 12,1x |
| Select | 240 | 40 | 6,0x |
Büyük verilerde Polars avantajı doğrusal olmayan biçimde artar: 8 çekirdekte paralel yürütme ve sorgu iyileştirici kümülatif bir etki üretir. GroupBy 8,6x daha hızlıdır — "bir saniye beklemek" ile "100 milisaniye beklemek" arasındaki fark.
Gerçek Verilerle ETL (NYC Taxi, 12,7M satır)
| İşlem | Pandas (s) | Polars (s) | Hız Farkı |
|---|---|---|---|
| CSV Yükleme | 28,5 | 1,14 | 25,0x |
| Filtre + GroupBy + Agg | 3,8 | 0,42 | 9,0x |
| Çok sütunlu dönüşüm | 2,1 | 0,7 | 3,0x |
| Tam ETL hattı | 34,4 | 2,26 | 15,2x |
CSV G/Ç en çarpıcı sonuçtur: Polars, CSV'yi Rust motorunda paralel olarak okur, 25x daha hızlı. Bu, tarihsel verilerin ilk yüklenmesi için kritik öneme sahiptir.
Resmi PDS-H Karşılaştırmalı Testi (Mayıs 2025)
 DataFrame kütüphanesi performans yarışı: Polars ve DuckDB önde giderken Pandas büyük ölçüde geride kalıyor
DataFrame kütüphanesi performans yarışı: Polars ve DuckDB önde giderken Pandas büyük ölçüde geride kalıyor
PDS-H (Performance Data Science — Holistic), veritabanları için TPC-H'a benzer şekilde DataFrame kütüphaneleri için standart bir karşılaştırmalı testtir. Mayıs 2025 sonuçları:
- Pandas yalnızca SF-10 ölçeğinde katılıyor — tek iş parçacıklı, sorgu iyileştirici yok, liderlerden iki kat daha yavaş
- Polars ve DuckDB SF-10 ve SF-100'de kendi liglerinde
- Polars'taki yeni akış motoru, bellek içi moda kıyasla ek 3-7x hız artışı sağlar — RAM'e sığmayan verilerin işlenmesini mümkün kılar
Algotrading açısından bu şu anlama gelir: hattınız 100M+ satır tick verisi yüklerken bellek sınırlıysa — Polars akış motoru RAM'i artırmadan bunları işlemenize olanak tanır.
Ticaret Sinyalleri için Kayan Pencere Hesaplamaları: Katil Özellik

Bu, algotrading için en önemli karşılaştırmalı testtir. Tipik görev: 100 enstrümanınız var ve her biri için kayan ortalama, kayan standart sapma, z-skoru hesaplamanız ve bunlara dayanarak bir sinyal üretmeniz gerekiyor. Pandas'ta bu groupby().rolling(), Polars'ta ise group_by().agg(col().rolling_mean()).
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling ifadeleri
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
Sonuçlar
| İşlem | Pandas (ms) | Polars (ms) | Hız Farkı |
|---|---|---|---|
| Kayan ortalama, 100 grup x 100K satır | 4200 | 12 | 350x |
| Kayan std, 100 grup x 100K satır | 5100 | 15 | 340x |
| Z-skoru (ortalama + std + aritmetik) | 12500 | 35 | 357x |
| Kayan ortalama, 1000 grup x 10K satır | 38000 | 11 | 3454x |
Kayan pencere hesaplamalarında 10x ile 3500x arasında hız artışı. Bu bir yazım hatası değildir. Pandas groupby().transform(lambda x: x.rolling().mean()), her grup üzerinde bir Python döngüsü oluşturur ve her çağrıda yorumlayıcı ek yükü oluşur. Polars her şeyi Rust'ta, gruplar arasında paralel olarak, ara Python nesneleri olmadan yürütür.
100 enstrümanda 10 gösterge hesaplaması gereken bir hat için — bu 2 dakika ile 0,3 saniye arasındaki farktır.
Teknik Göstergeler: Bollinger Bantları, Keltner Kanalları, TTM Squeeze
 Bir fiyat serisini çevreleyen Bollinger Bantları ve Keltner Kanalları ile vurgulanan TTM Squeeze bölgeleri
Bir fiyat serisini çevreleyen Bollinger Bantları ve Keltner Kanalları ile vurgulanan TTM Squeeze bölgeleri
Ticaret stratejilerinde kullanılan gerçek teknik göstergelerin hesaplanmasını inceleyelim.
Bollinger Bantları
Pandas Uygulaması
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
Polars Uygulaması
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
Keltner Kanalları
burada ATR (Ortalama Gerçek Aralık):
TTM Squeeze
TTM Squeeze, piyasanın sıkışma durumundan (düşük volatilite) genişleme durumuna geçişini belirlemek için kullanılan bir yöntemdir. Sinyal, Bollinger Bantları Keltner Kanallarının içinde olduğunda gerçekleşir:
Teknik Göstergeler Karşılaştırmalı Testi (1M satır, tek ticker)
| Gösterge | Pandas (ms) | Polars (ms) | Hız Farkı |
|---|---|---|---|
| Bollinger Bantları (20, 2) | 8,4 | 1,2 | 7,0x |
| Keltner Kanalları (20, 1,5) | 14,2 | 2,1 | 6,8x |
| TTM Squeeze (tam) | 28,6 | 4,1 | 7,0x |
| RSI (14) | 6,8 | 1,1 | 6,2x |
| MACD (12, 26, 9) | 5,2 | 0,8 | 6,5x |
Tek bir ticker'da tutarlı biçimde ~7x hız artışı. Gruba göre (100 ticker) hesaplama yapıldığında, Pandas groupby ek yükü nedeniyle hız artışı yüzlerce kata çıkar.
Hazır Gösterge Paketleri Hakkında Not
Pandas için pandas-ta — 130'dan fazla göstergeye sahip bir kütüphane vardır. Polars için henüz eşdeğer bir paket yoktur. Bu, Polars kullanırken göstergeleri kendiniz uygulamanız gerektiği anlamına gelir. Ancak temel yapı taşları (rolling_mean, rolling_std, ewm_mean, shift, sütun aritmetiği), standart göstergelerin büyük çoğunluğunu kapsar ve Polars uygulaması genellikle göründüğünden daha kısadır.
G/Ç Karşılaştırmalı Testleri: CSV, Parquet, Veritabanı
 CSV, Parquet ve veritabanı kaynaklarından veri akışları: paralel Rust G/Ç'ye karşı tek iş parçacıklı Python
CSV, Parquet ve veritabanı kaynaklarından veri akışları: paralel Rust G/Ç'ye karşı tek iş parçacıklı Python
Veri hattı, veri yükleme ile başlar. Depolama biçimi ve okuma yöntemi, tüm hattın temel hızını belirler.
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
G/Ç Sonuçları (10M satır, 6 sütun)
| İşlem | Pandas (s) | Polars (s) | Hız Farkı |
|---|---|---|---|
| CSV okuma | 28,5 | 1,14 | 25,0x |
| CSV yazma | 42,0 | 2,8 | 15,0x |
| Parquet okuma (tüm sütunlar) | 0,82 | 0,31 | 2,6x |
| Parquet okuma (6'dan 3 sütun) | 0,54 | 0,12 | 4,5x |
| Parquet yazma | 0,95 | 0,91 | 1,04x |
| Parquet lazy (filtre + select) | Yok | 0,08 | koşul aşağı itme |
Temel çıkarımlar:
- CSV: Polars 25x'e kadar daha hızlı — Rust'ta paralel ayrıştırma
- Parquet okuma: Polars, tam okumada 2,6x daha hızlı ve projeksiyon aşağı itme ile 4,5x (yalnızca gerekli sütunları okuma)
- Parquet yazma: neredeyse aynı — her ikisi de PyArrow/Arrow arka ucunu kullanır
- Lazy tarama: Polars, filtreyi veriyi belleğe yüklemeden Parquet dosyası satır grubu düzeyinde uygulayabilir. Bu, PyArrow'u manuel olarak kullanmadan Pandas ile imkansızdır
Parquet önbelleği için — önceden hesaplanmış zaman dilimlerini ve göstergeleri depolamak için birincil biçimimiz — tembel değerlendirmeli Polars ideal entegrasyon sağlar: tüm dosyayı belleğe okumadan yalnızca gerekli sütunları ve dönemleri yükler.
Bellek Tüketimi ve Tembel Değerlendirme
 İstekli ve tembel bellek desenleri: turuncuda gereksiz kopyalar ile camgöbeğinde optimize edilmiş Arrow sütunlu düzeni
İstekli ve tembel bellek desenleri: turuncuda gereksiz kopyalar ile camgöbeğinde optimize edilmiş Arrow sütunlu düzeni
İstekli ve Tembel
Pandas yalnızca istekli modda çalışır: her işlem hemen yürütülür ve ara sonuçlar bellekte somutlaştırılır.
df = pd.read_csv("big_file.csv") # tüm dosya RAM'de
df = df[df["volume"] > 1000] # filtrelenmiş kopya
df = df[["timestamp", "close", "volume"]] # başka bir kopya
df["returns"] = df["close"].pct_change() # bir kopya daha
Polars tembel değerlendirmeyi destekler — sorgular bir grafik olarak oluşturulur, optimize edilir ve tek bir geçişte yürütülür:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Polars iyileştiricisi otomatik olarak:
- Projeksiyon aşağı itme: tüm sütunlar yerine yalnızca 3 sütun okur
- Koşul aşağı itme: gereksiz satırları yüklemeden okuma sırasında
volume > 1000filtresini uygular - Ortak alt ifade eleme: aynı şeyi iki kez hesaplamaktan kaçınır
Bellek Tüketimi (10M satır, 6 float64 sütun)
| Senaryo | Pandas (GB) | Polars istekli (GB) | Polars tembel (GB) |
|---|---|---|---|
| CSV Yükleme | 0,92 | 0,46 | 0,46 |
| Filtre + 3 sütun seçimi | 1,38* | 0,22 | 0,22 |
| 5 dönüşüm hattı | 2,76* | 0,48 | 0,48 |
| Parquet yükleme (6'dan 3 sütun) | 0,46 | 0,23 | 0,23 |
* Pandas ara kopyalar oluşturur; inplace=True kısmen yardımcı olur, ancak tüm işlemler için değil.
Polars, Arrow sütunlu biçimini doğal olarak kullanır: veriler sütunlara göre depolanır, satırlar çoğaltılmaz ve mümkün olan her yerde sıfır kopyalı işlemler kullanılır. Birden fazla dönüşümlü hatlarda Polars 2-6x daha az bellek tüketir.
Akış Motoru: RAM'den Büyük Veriler
RAM'e sığmayan veri kümeleri için Polars bir akış motoru sunar:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
Akış motoru, tüm veri kümesini belleğe yüklemeden veriyi parçalar halinde işler. PDS-H karşılaştırmalı test verilerine göre, akış modu büyük ölçeklerde bellek içinden 3-7x daha hızlıdır — daha iyi önbellek konumu ve sanal bellek baskısının olmaması sayesinde.
Hibrit Mimari: Polars + Numba
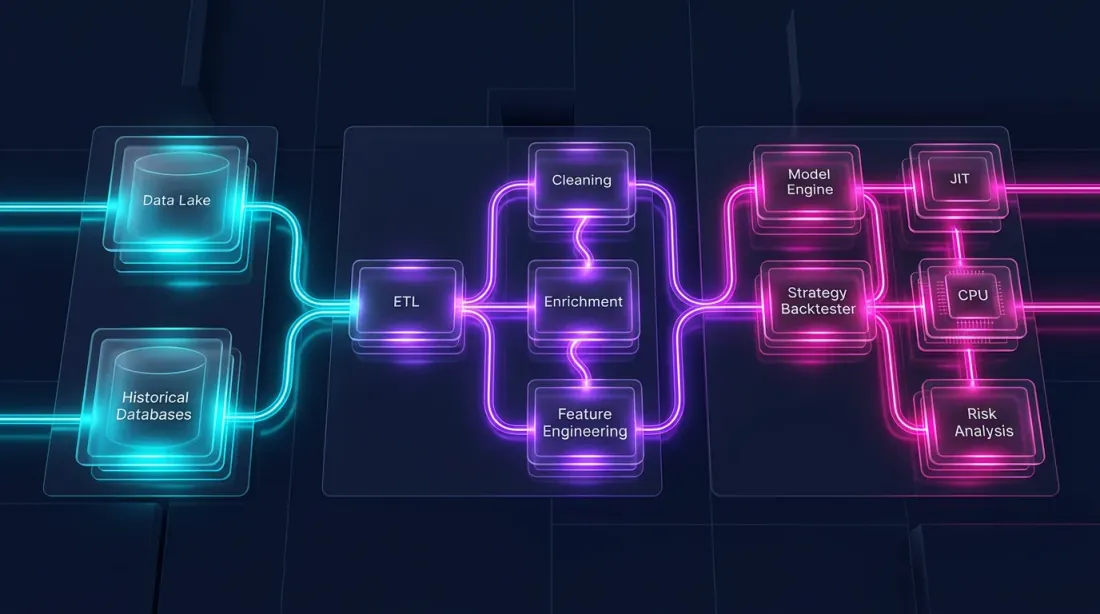
Bir backtest, temelden farklı iki bölümden oluşur:
-
Veri hattı — yükleme, dönüşüm, göstergeler, filtreleme. Bu, kitlesel paralel, sütun odaklıdır ve Polars için mükemmel uygundur.
-
Portföy simülasyonu — emir doldurma, PnL hesaplama, pozisyon yönetimi. Bu yol bağımlıdır: her adım önceki duruma bağlıdır. Bu, zaman serisi üzerinde eleman bazlı geçiş gerektirir.
Pandas her iki bölüm için de yetersizdir. Polars birincisinde mükemmel ancak ikincisinde değil. Yol bağımlı mantık için en iyi araç Numba (Python için JIT derleyicisi) veya yerel Rust/C++'dır.
Mimari
┌─────────────────────────────────────────────────────┐
│ Veri Hattı │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Göstergeler │ │
│ │ │ Filtreler │ │
│ │ │ Özellikler │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy dizileri │
│ │ (Arrow'dan sıfır kopyalı) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portföy Simülasyonu (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
Örnek: Tam Hat
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # Arrow'dan sıfır kopyalı
signals = df["signal"].to_numpy() # Arrow'dan sıfır kopyalı
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Yol bağımlı simülasyon: Numba makine koduna derlenir.
1M iterasyon 70-100ms'de.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
Neden vectorbt Değil?
vectorbt, 1M emri 70-100ms'de işleyen popüler bir backtesting çerçevesidir. Pandas + NumPy + Numba üzerine inşa edilmiştir. Sorun: Pandas veri hattındaki darboğazdır — yavaş, tek iş parçacıklı, bellek açısından aç gözlü. vectorbt, kritik parçalar için Numba aracılığıyla Pandas sınırlamalarını aşmak zorundadır, ancak veri yükleme ve gösterge hesaplama hâlâ Pandas üzerinden geçer.
Hibrit Polars + Numba mimarisi her iki dünyanın en iyisini alır:
- Polars veri hattı için — aynı işlemlerde Pandas'tan 5-350x daha hızlı
- Numba portföy simülasyonu için — vectorbt ile aynı hız
- Ara Pandas katmanı yok — veri Arrow'dan sıfır kopyalı olarak doğrudan NumPy'ye akar
Geçiş: Pandas'tan Polars'a Temel Desenler
 Eski ve modern kod arasındaki köprü: Pandas desenlerini Polars ifadelerine çevirme
Eski ve modern kod arasındaki köprü: Pandas desenlerini Polars ifadelerine çevirme
Hattınız Pandas ile yazılmışsa, geçiş sıfırdan yeniden yazmayı gerektirmez. Temel desenler şablonlarla çevrilir.
Veri Okuma
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # .collect() çağrılana kadar hiçbir şey okumaz
Filtreleme
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
Sütun Oluşturma
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + Gruplama
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
Gruba Göre Kayan Pencere
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
QuestDB ile Entegrasyon
Polars, QuestDB'nin veri aktarımı için kullandığı biçimle aynı olan Apache Arrow ile doğal olarak çalışır. Bu, sorgu sonuçlarını alırken sıfır kopyalı işlem anlamına gelir:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # sıfır kopyalı!
df_pd = arrow_table.to_pandas() # kopya + tür dönüşümü
Ticaret verilerini depolamak ve analiz etmek için QuestDB ile çalışma hakkında daha fazla bilgi için veri mimarisine ilişkin makale serimize bakın.
Parquet Önbelleği ile Entegrasyon
 Seçici veri yükleme için koşul aşağı itme ve projeksiyon aşağı itme ile sütunlu Parquet önbelleği
Seçici veri yükleme için koşul aşağı itme ve projeksiyon aşağı itme ile sütunlu Parquet önbelleği
Toplu Parquet Önbelleği makalesinde, zaman dilimlerini ve göstergeleri bir kez önceden hesaplayıp Parquet dosyasına kaydetmeyi anlattık. Polars bu yaklaşımı daha da verimli hale getirir:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
Toplu optimizasyon sırasında — binlerce parametre kombinasyonu çalıştırmanız gerektiğinde — koşul aşağı itme ile Polars scan_parquet aracılığıyla Parquet önbelleğinden okuma, tüm dosyayı okumadan yalnızca gerekli dönem ve sütunları yüklemenizi sağlar.
Uyarlamalı yakınlaştırma ile entegrasyon: Polars tembel değerlendirme, iki düzeyli yükleme için mükemmel uygundur — ana geçiş için kaba veriler, yalnızca doldurma belirsizliği bölgeleri için ayrıntılı veriler (saniyeler, milisaniyeler).
Ne Zaman Ne Kullanılır: Pratik Öneriler
 Karar matrisi: küçük ölçekli prototipleme ile büyük ölçekli üretim hatları için ayrılan yollar
Karar matrisi: küçük ölçekli prototipleme ile büyük ölçekli üretim hatları için ayrılan yollar
Pandas şu durumlarda gerekçelidir:
- 1M satıra kadar veri kümesi ve yüzlerce grup üzerinde GroupBy yapmıyorsanız — Pandas 2.2 ile Polars arasındaki fark genellikle ihmal edilebilir düzeydedir (1,5-2x)
pandas-ta'ya ihtiyacınız varsa veya Pandas API'li diğer kütüphanelere — 130 göstergeyi tek seferlik bir çalışma için yeniden yazmak pratik değildir- Prototipleme — Pandas API'si çoğu kişi için daha tanıdıktır ve hızlı hipotez testi için hız kritik değildir
- Eski kod ile entegrasyon — çalışan ve optimizasyon gerektirmeyen mevcut bir Pandas hattı
Polars şu durumlarda gereklidir:
- 10M satırdan itibaren veri kümesi — on milyonlarca ve yüz milyonlarca satır tick verisi, çok zaman dilimli önbellekler
- Gruba göre kayan pencere — 100+ enstrüman, her biri için göstergeler: 100-3500x hız artışı
- ETL hattı — büyük hacimli veriyi yükleme, temizleme, dönüştürme
- Sınırlı RAM — tembel değerlendirme ve akış motoru, belleğe sığmayan verilerin işlenmesini sağlar
- Parquet/QuestDB yığını — yerel Arrow = sıfır kopyalı, koşul aşağı itme, projeksiyon aşağı itme
Ne Beklenmemeli
Pazarlama rakamı "30x daha hızlı", belirli işlemlerdeki tepe hız artışıdır. Tipik hat işlemlerindeki gerçekçi hız artışı: 2-10x. Gruba göre kayan pencerede — önemli ölçüde daha fazla. Küçük veri kümelerinde — ek yük nedeniyle Polars bazen daha yavaş bile olabilir.
marketmaker.cc'deki Deneyimimiz
 Üretim metrikleri: 6-8x hat hız artışı ve saatte 8x daha fazla optimizasyon iterasyonu
Üretim metrikleri: 6-8x hat hız artışı ve saatte 8x daha fazla optimizasyon iterasyonu
marketmaker.cc adresinde, backtest motoru için hibrit Polars + Numba mimarisi kullanıyoruz. Tüm veri hattı — Parquet önbelleğinden yükleme, gösterge hesaplama, filtreleme, özellik mühendisliği — Polars üzerinde çalışır. Portföy simülasyonu Numba üzerinde çalışır.
Veri hattında Pandas'tan Polars'a geçiş, tipik veri kümelerimizde (50-100M satır, 200+ enstrüman) 6-8x hız artışı sağladı. Gruba göre kayan pencere gösterge hesaplama dakikalardan yüz milisaniyelere geriledi. Bu, donanımı değiştirmeden optimizasyon iterasyonu sayısını saatte ~500'den ~4000'e çıkarmamızı sağladı.
Kritik bir nokta: tüm kodu tek bir günde taşımadık. Önce G/Ç'yi (Parquet okuma), sonra gösterge hesaplamayı, ardından filtreleme ve özellik mühendisliğini taşıdık. Pandas yalnızca pd.DataFrame bekleyen eski bileşenlerle arayüzde kaldı. df.to_pandas() / pl.from_pandas() dönüşümü milisaniyeler alır ve bir darboğaz değildir.
Backtest aşamasında hesaplanan metrikler — Aktif Zamana Göre PnL dahil — zaten Polars DataFrame'ler üzerinde hesaplanmaktadır; bu hattı basitleştirir ve ara dönüşümleri ortadan kaldırır.
Sonuç
 Birleşen üç teknoloji akışı: Polars, Numba ve Arrow tek bir optimize edilmiş hatta birleşiyor
Birleşen üç teknoloji akışı: Polars, Numba ve Arrow tek bir optimize edilmiş hatta birleşiyor
Polars, her senaryoda Pandas'ın yerini almaz. Ciddi algotrading için tipik ölçeklerde parlayan farklı bir sınıf araçtır: milyonlarca ve yüz milyonlarca satır, onlarca ve yüzlerce enstrüman, sürekli parametre optimizasyonu.
Temel rakamlar:
- Temel işlemler: tipik hat görevlerinde 2-10x hız artışı
- Gruba göre kayan pencere: 10-3500x — ticaret hatları için ana katil özellik
- CSV G/Ç: 25x'e kadar — ilk veri yükleme için kritik
- Bellek: Arrow ve tembel değerlendirme sayesinde 2-6x tasarruf
- Akış: RAM'e sığmayan verilerin işlenmesi
Üretim backtest motoru için önerilen mimari:
- Polars — tüm veri hattı: yükleme, göstergeler, filtreleme, özellikler
- Numba/Rust — portföy simülasyonu: yol bağımlı emir ve pozisyon mantığı
- Arrow — tüm bağlantı noktalarındaki veri biçimi: Parquet, QuestDB, Polars, NumPy
Ara Pandas katmanı yok. Veri, depolamadan Polars üzerinden NumPy dizilerine ve ardından Numba motoruna akar — gereksiz kopyalar, GIL ve tek iş parçacıklı darboğazlar olmadan.
Faydalı Bağlantılar
- Polars — Kullanıcı Rehberi
- Polars ve Pandas — resmi karşılaştırmalı test
- PDS-H Karşılaştırmalı Testi — DataFrame kütüphaneleri karşılaştırması
- Apache Arrow — sütunlu biçim belirtimi
- Numba — Python için JIT derleyicisi
- vectorbt — backtesting çerçevesi
- pandas-ta — Teknik Analiz Göstergeleri
- Ritchie Vink — En hızlı DataFrame kütüphanelerinden birini yazdım (Polars'ın kökeni)
- Towards Data Science — Polars ve Pandas: gerçek dünya karşılaştırmalı testleri
- Ernest Chan — Quantitative Trading
Atıf
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/tr/blog/post/polars-vs-pandas-algotrading},
description = {Polars ve Pandas'ın algotrading görevlerindeki ayrıntılı karşılaştırması: filtreleme, gruplama, kayan pencere sinyal hesaplama, G/Ç ve bellek tüketimi için karşılaştırmalı testler. Maksimum backtest performansı için hibrit Polars + Numba mimarisi.}
}
Yazarlar

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Daha Fazla Oku

T-Bricks (Broadridge): Prop Firmaların Kullandığı Platform Nasıl Çalışır
VectorBT: Python için En Hızlı Backtesting Çerçevesi
