Polars vs Pandas cho Algotrading: Benchmark trên Dữ liệu Thực

Chuỗi "Backtest Không Ảo Tưởng", Bài 9
Kiểm thử chiến lược (backtesting) không chỉ là về logic tín hiệu và mô phỏng thực thi. Đó còn là một pipeline dữ liệu: tải hàng triệu nến, resample khung thời gian, tính chỉ báo, lọc theo điều kiện, nhóm theo công cụ tài chính. Khi pipeline mất 30 giây thay vì 3 giây, đó không chỉ là sự bất tiện. Điều đó có nghĩa là ít thử nghiệm hơn 10 lần mỗi giờ, vòng lặp phát triển chậm hơn 10 lần, và con đường từ ý tưởng đến sản xuất dài hơn 10 lần.
Pandas là tiêu chuẩn thực tế cho dữ liệu dạng bảng trong Python. Nhưng Pandas được thiết kế năm 2008, khi CPU còn chậm hơn và tập dữ liệu còn nhỏ hơn. Pandas chạy đơn luồng, tiêu tốn nhiều bộ nhớ và thiếu trình tối ưu hóa truy vấn. Polars là thư viện thế hệ tiếp theo viết bằng Rust, với thực thi song song, Apache Arrow ở lõi và trình lập kế hoạch truy vấn lazy.
Câu hỏi đặt ra: Polars nhanh hơn bao nhiêu trên các tác vụ algotrading thực tế? Không phải trên benchmark tổng hợp từ README, mà trên lọc tick, tính chỉ báo rolling, nhóm theo công cụ tài chính và tải từ Parquet/QuestDB?
Bài viết này cung cấp benchmark hệ thống với các con số, mã nguồn và khuyến nghị thực tế.
Phương Pháp Benchmark
 Phòng thí nghiệm đo lường tương lai: môi trường benchmark chính xác với các tham số được kiểm soát
Phòng thí nghiệm đo lường tương lai: môi trường benchmark chính xác với các tham số được kiểm soát
Trước khi so sánh, hãy xác định các quy tắc để kết quả có thể tái tạo và công bằng.
Môi Trường
- Python 3.11, Pandas 2.2, Polars 1.x (phiên bản ổn định mới nhất)
- Máy: 8 nhân, 32 GB RAM, NVMe SSD
- Mỗi benchmark chạy 100 lần; lấy giá trị trung vị
- Khởi động: 5 lần lặp trước khi đo
- GC bị tắt trong quá trình đo (
gc.disable())
Dữ Liệu
Ba mức độ quy mô:
- Nhỏ: 10K hàng (một công cụ, một ngày, nến phút)
- Trung bình: 1M hàng (một công cụ, ~2 năm, nến phút)
- Lớn: 10M+ hàng (100 công cụ, 2 năm, nến phút)
Ngoài ra: tập dữ liệu NYC Taxi thực tế (12,7M hàng) cho các benchmark ETL — benchmark tiêu chuẩn của ngành.
Những Gì Chúng Tôi Đo
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Fair benchmark: warmup + median of n runs."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
Benchmark Các Thao Tác: Bảng
 So sánh hiệu suất trên các thao tác: filter, groupby, join và select ở các quy mô dữ liệu khác nhau
So sánh hiệu suất trên các thao tác: filter, groupby, join và select ở các quy mô dữ liệu khác nhau
Tập dữ liệu nhỏ (10K hàng)
| Thao tác | Pandas (ms) | Polars (ms) | Tốc độ tăng |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
Với 10K hàng, Pandas đôi khi nhanh hơn trên các phép lọc đơn giản — chi phí gọi hàm Polars qua PyO3 tương đương với thời gian của chính thao tác đó. Nhưng trên join, lợi thế đã thấy rõ: bảng băm Polars trong Rust nhanh hơn 13 lần.
Tập dữ liệu trung bình (1M hàng)
| Thao tác | Pandas (ms) | Polars (ms) | Tốc độ tăng |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
Với một triệu hàng, Polars nhất quán nhanh hơn 1.6 lần trên lọc và nhóm. Trên select (chọn tập con cột) — 10.9 lần, vì định dạng cột Arrow cho phép slicing không cần sao chép.
Tập dữ liệu lớn (10M+ hàng)
| Thao tác | Pandas (ms) | Polars (ms) | Tốc độ tăng |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
Trên dữ liệu lớn, lợi thế của Polars tăng phi tuyến: thực thi song song trên 8 nhân và trình tối ưu hóa truy vấn tạo ra hiệu ứng tích lũy. GroupBy nhanh hơn 8.6 lần — sự khác biệt giữa "chờ một giây" và "chờ 100 mili giây".
ETL trên Dữ Liệu Thực (NYC Taxi, 12,7M hàng)
| Thao tác | Pandas (s) | Polars (s) | Tốc độ tăng |
|---|---|---|---|
| CSV Load | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| Multi-column transform | 2.1 | 0.7 | 3.0x |
| Full ETL pipeline | 34.4 | 2.26 | 15.2x |
I/O CSV là kết quả ấn tượng nhất: Polars đọc CSV song song trên engine Rust, nhanh hơn 25 lần. Điều này rất quan trọng khi tải dữ liệu lịch sử lần đầu.
Benchmark PDS-H Chính Thức (Tháng 5 năm 2025)
 Cuộc đua hiệu suất thư viện DataFrame: Polars và DuckDB dẫn đầu trong khi Pandas tụt hậu nhiều bậc
Cuộc đua hiệu suất thư viện DataFrame: Polars và DuckDB dẫn đầu trong khi Pandas tụt hậu nhiều bậc
PDS-H (Performance Data Science — Holistic) là benchmark tiêu chuẩn cho các thư viện DataFrame, tương tự TPC-H cho cơ sở dữ liệu. Kết quả từ tháng 5 năm 2025:
- Pandas chỉ tham gia ở quy mô SF-10 — đơn luồng, không có trình tối ưu hóa truy vấn, chậm hơn hai bậc độ lớn so với các thư viện dẫn đầu
- Polars và DuckDB đang ở một đẳng cấp khác tại SF-10 và SF-100
- Engine streaming mới trong Polars cho tốc độ tăng thêm 3-7 lần so với chế độ in-memory — cho phép xử lý dữ liệu không vừa trong RAM
Đối với algotrading, điều này có nghĩa là: nếu pipeline của bạn bị giới hạn bộ nhớ khi tải hơn 100M hàng dữ liệu tick — engine streaming của Polars cho phép xử lý chúng mà không cần tăng RAM.
Tính Toán Rolling cho Tín Hiệu Giao Dịch: Tính Năng Nổi Bật

Đây là benchmark quan trọng nhất cho algotrading. Tác vụ điển hình: bạn có 100 công cụ tài chính, và cho mỗi cái bạn cần tính rolling mean, rolling std, z-score và tạo tín hiệu dựa trên chúng. Trong Pandas là groupby().rolling(), trong Polars là group_by().agg(col().rolling_mean()).
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling expressions
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
Kết Quả
| Thao tác | Pandas (ms) | Polars (ms) | Tốc độ tăng |
|---|---|---|---|
| Rolling mean, 100 groups x 100K rows | 4200 | 12 | 350x |
| Rolling std, 100 groups x 100K rows | 5100 | 15 | 340x |
| Z-score (mean + std + arithmetic) | 12500 | 35 | 357x |
| Rolling mean, 1000 groups x 10K rows | 38000 | 11 | 3454x |
Tốc độ tăng từ 10x đến 3500x trên các tính toán rolling theo nhóm. Đây không phải lỗi đánh máy. Pandas groupby().transform(lambda x: x.rolling().mean()) tạo ra một vòng lặp Python qua từng nhóm, với mỗi lần gọi phát sinh chi phí của trình thông dịch. Polars thực thi mọi thứ trong Rust, song song trên các nhóm, không có đối tượng Python trung gian.
Đối với pipeline cần tính 10 chỉ báo trên 100 công cụ — đây là sự khác biệt giữa 2 phút và 0.3 giây.
Chỉ Báo Kỹ Thuật: Bollinger Bands, Keltner Channels, TTM Squeeze
 Bollinger Bands và Keltner Channels bao quanh chuỗi giá, với các vùng TTM Squeeze được làm nổi bật
Bollinger Bands và Keltner Channels bao quanh chuỗi giá, với các vùng TTM Squeeze được làm nổi bật
Hãy xem xét việc tính toán các chỉ báo kỹ thuật thực tế được sử dụng trong các chiến lược giao dịch.
Bollinger Bands
Cài Đặt Pandas
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
Cài Đặt Polars
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
Keltner Channels
trong đó ATR (Average True Range):
TTM Squeeze
TTM Squeeze là phương pháp xác định sự chuyển đổi của thị trường từ trạng thái squeeze (biến động thấp) sang trạng thái mở rộng. Tín hiệu xảy ra khi Bollinger Bands nằm trong Keltner Channels:
Benchmark Chỉ Báo Kỹ Thuật (1M hàng, một ticker)
| Chỉ báo | Pandas (ms) | Polars (ms) | Tốc độ tăng |
|---|---|---|---|
| Bollinger Bands (20, 2) | 8.4 | 1.2 | 7.0x |
| Keltner Channels (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTM Squeeze (full) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
Tốc độ tăng nhất quán ~7 lần trên một ticker. Khi tính theo nhóm (100 ticker), tốc độ tăng lên hàng trăm lần do chi phí groupby của Pandas.
Lưu Ý về Các Gói Chỉ Báo Có Sẵn
Đối với Pandas, có pandas-ta — thư viện với hơn 130 chỉ báo. Đối với Polars, hiện chưa có gói tương đương. Điều này có nghĩa là khi sử dụng Polars, bạn sẽ cần tự triển khai các chỉ báo. Tuy nhiên, các khối xây dựng cơ bản (rolling_mean, rolling_std, ewm_mean, shift, số học cột) bao gồm phần lớn các chỉ báo tiêu chuẩn, và việc triển khai Polars thường ngắn hơn bạn nghĩ.
Benchmark I/O: CSV, Parquet, Cơ Sở Dữ Liệu
 Luồng dữ liệu từ nguồn CSV, Parquet và cơ sở dữ liệu: I/O Rust song song so với Python đơn luồng
Luồng dữ liệu từ nguồn CSV, Parquet và cơ sở dữ liệu: I/O Rust song song so với Python đơn luồng
Pipeline dữ liệu bắt đầu bằng việc tải dữ liệu. Định dạng lưu trữ và phương pháp đọc xác định tốc độ cơ sở của toàn bộ pipeline.
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Kết Quả I/O (10M hàng, 6 cột)
| Thao tác | Pandas (s) | Polars (s) | Tốc độ tăng |
|---|---|---|---|
| CSV read | 28.5 | 1.14 | 25.0x |
| CSV write | 42.0 | 2.8 | 15.0x |
| Parquet read (all columns) | 0.82 | 0.31 | 2.6x |
| Parquet read (3 of 6 columns) | 0.54 | 0.12 | 4.5x |
| Parquet write | 0.95 | 0.91 | 1.04x |
| Parquet lazy (filter + select) | N/A | 0.08 | predicate pushdown |
Những điểm chính:
- CSV: Polars nhanh hơn tới 25 lần — phân tích cú pháp song song trong Rust
- Parquet read: Polars nhanh hơn 2.6 lần khi đọc toàn bộ và 4.5 lần với projection pushdown (chỉ đọc các cột cần thiết)
- Parquet write: gần như giống nhau — cả hai đều sử dụng backend PyArrow/Arrow
- Lazy scan: Polars có thể áp dụng bộ lọc ở mức row group của file Parquet mà không cần tải dữ liệu vào bộ nhớ. Điều này không thể thực hiện với Pandas mà không sử dụng PyArrow thủ công
Đối với bộ nhớ đệm Parquet — định dạng chính của chúng tôi để lưu trữ khung thời gian và chỉ báo được tính trước — Polars với lazy evaluation cung cấp tích hợp lý tưởng: chỉ tải các cột và khoảng thời gian cần thiết mà không đọc toàn bộ file vào bộ nhớ.
Tiêu Thụ Bộ Nhớ và Lazy Evaluation
 Mô hình bộ nhớ eager vs lazy: các bản sao dư thừa màu cam so với bố cục cột Arrow được tối ưu hóa màu xanh lam
Mô hình bộ nhớ eager vs lazy: các bản sao dư thừa màu cam so với bố cục cột Arrow được tối ưu hóa màu xanh lam
Eager vs Lazy
Pandas chỉ hoạt động ở chế độ eager: mỗi thao tác thực thi ngay lập tức, và các kết quả trung gian được hiện thực hóa trong bộ nhớ.
df = pd.read_csv("big_file.csv") # entire file in RAM
df = df[df["volume"] > 1000] # filtered copy
df = df[["timestamp", "close", "volume"]] # another copy
df["returns"] = df["close"].pct_change() # yet another copy
Polars hỗ trợ lazy evaluation — các truy vấn được xây dựng thành đồ thị, tối ưu hóa và thực thi trong một lần duy nhất:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Trình tối ưu hóa Polars tự động:
- Projection pushdown: chỉ đọc 3 cột thay vì tất cả
- Predicate pushdown: áp dụng bộ lọc
volume > 1000trong quá trình đọc, không tải các hàng không cần thiết - Common subexpression elimination: tránh tính toán cùng một thứ hai lần
Tiêu Thụ Bộ Nhớ (10M hàng, 6 cột float64)
| Kịch bản | Pandas (GB) | Polars eager (GB) | Polars lazy (GB) |
|---|---|---|---|
| CSV Load | 0.92 | 0.46 | 0.46 |
| Filter + Select 3 columns | 1.38* | 0.22 | 0.22 |
| Pipeline of 5 transformations | 2.76* | 0.48 | 0.48 |
| Parquet Load (3 of 6 cols) | 0.46 | 0.23 | 0.23 |
* Pandas tạo các bản sao trung gian; inplace=True giúp một phần, nhưng không phải cho tất cả các thao tác.
Polars sử dụng định dạng cột Arrow một cách tự nhiên: dữ liệu được lưu trữ theo cột, các hàng không bị nhân đôi, và các thao tác không cần sao chép được sử dụng khi có thể. Đối với các pipeline với nhiều biến đổi, Polars tiêu thụ ít hơn 2-6 lần bộ nhớ.
Engine Streaming: Dữ Liệu Lớn Hơn RAM
Đối với các tập dữ liệu không vừa trong RAM, Polars cung cấp engine streaming:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
Engine streaming xử lý dữ liệu theo từng khối mà không tải toàn bộ tập dữ liệu vào bộ nhớ. Theo dữ liệu benchmark PDS-H, chế độ streaming nhanh hơn 3-7 lần so với in-memory ở quy mô lớn — nhờ cache locality tốt hơn và không có áp lực bộ nhớ ảo.
Kiến Trúc Hybrid: Polars + Numba
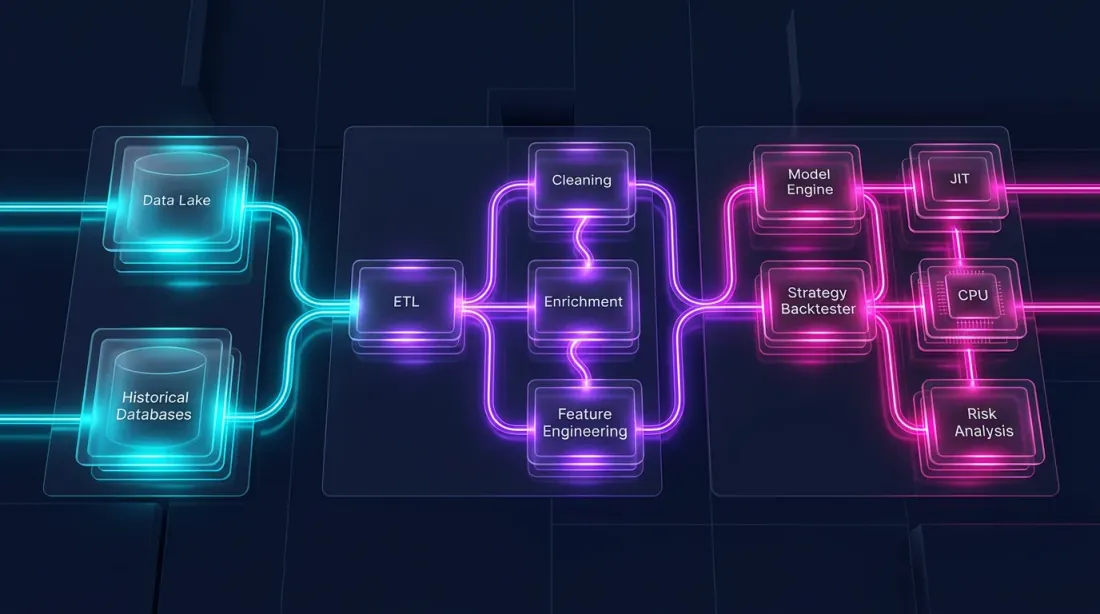
Một backtest bao gồm hai phần cơ bản khác nhau:
-
Pipeline dữ liệu — tải, biến đổi, chỉ báo, lọc. Đây là song song theo khối lượng lớn, hướng cột, và rất phù hợp với Polars.
-
Mô phỏng danh mục — khớp lệnh, tính PnL, quản lý vị thế. Đây là phụ thuộc đường dẫn: mỗi bước phụ thuộc vào trạng thái trước đó. Điều này đòi hỏi một lượt duyệt theo từng phần tử qua chuỗi thời gian.
Pandas không phù hợp tốt cho cả hai phần. Polars xuất sắc ở phần đầu nhưng không ở phần thứ hai. Đối với logic phụ thuộc đường dẫn, công cụ tối ưu là Numba (trình biên dịch JIT cho Python) hoặc Rust/C++ thuần túy.
Kiến Trúc
┌─────────────────────────────────────────────────────┐
│ Data Pipeline │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Indicators │ │
│ │ │ Filters │ │
│ │ │ Features │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy arrays │
│ │ (zero-copy from Arrow) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portfolio Simulation (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
Ví Dụ: Pipeline Hoàn Chỉnh
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy from Arrow
signals = df["signal"].to_numpy() # zero-copy from Arrow
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent simulation: Numba compiles to machine code.
1M iterations in 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
Tại Sao Không Dùng vectorbt?
vectorbt là framework backtesting phổ biến xử lý 1M lệnh trong 70-100ms. Nó được xây dựng trên Pandas + NumPy + Numba. Vấn đề: Pandas là nút cổ chai trong pipeline dữ liệu — chậm, đơn luồng, tiêu tốn nhiều bộ nhớ. vectorbt phải giải quyết các hạn chế của Pandas thông qua Numba cho các phần quan trọng, nhưng việc tải dữ liệu và tính toán chỉ báo vẫn đi qua Pandas.
Kiến trúc hybrid Polars + Numba lấy những điểm tốt nhất từ cả hai:
- Polars cho pipeline dữ liệu — nhanh hơn 5-350 lần so với Pandas trên cùng các thao tác
- Numba cho mô phỏng danh mục — tốc độ tương tự như trong vectorbt
- Không có lớp Pandas trung gian — dữ liệu chảy từ Arrow trực tiếp đến NumPy qua zero-copy
Di Chuyển: Các Mẫu Chính từ Pandas sang Polars
 Cầu nối giữa mã cũ và hiện đại: dịch các mẫu Pandas sang biểu thức Polars
Cầu nối giữa mã cũ và hiện đại: dịch các mẫu Pandas sang biểu thức Polars
Nếu pipeline của bạn được viết bằng Pandas, việc di chuyển không đòi hỏi viết lại từ đầu. Các mẫu chính được dịch qua các template.
Đọc Dữ Liệu
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # reads nothing until .collect()
Lọc
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
Tạo Cột
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + Tổng Hợp
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
Rolling theo Nhóm
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
Tích Hợp với QuestDB
Polars hoạt động tự nhiên với Apache Arrow — cùng định dạng mà QuestDB sử dụng để truyền dữ liệu. Điều này có nghĩa là zero-copy khi nhận kết quả truy vấn:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # copy + type conversion
Để biết thêm về làm việc với QuestDB để lưu trữ và phân tích dữ liệu giao dịch, hãy xem chuỗi bài viết của chúng tôi về kiến trúc dữ liệu.
Tích Hợp với Bộ Nhớ Đệm Parquet
 Bộ nhớ đệm Parquet dạng cột với predicate pushdown và projection pushdown để tải dữ liệu có chọn lọc
Bộ nhớ đệm Parquet dạng cột với predicate pushdown và projection pushdown để tải dữ liệu có chọn lọc
Trong bài viết Bộ Nhớ Đệm Parquet Tổng Hợp, chúng tôi đã mô tả cách tính trước các khung thời gian và chỉ báo một lần và lưu chúng vào file Parquet. Polars làm cho cách tiếp cận này hiệu quả hơn:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
Trong quá trình tối ưu hóa hàng loạt — khi bạn cần chạy hàng nghìn tổ hợp tham số — việc đọc từ bộ nhớ đệm Parquet qua Polars scan_parquet với predicate pushdown cho phép chỉ tải các khoảng thời gian và cột cần thiết mà không đọc toàn bộ file.
Tích hợp với Adaptive drill-down: Polars lazy evaluation rất phù hợp cho việc tải hai cấp — dữ liệu thô cho lần duyệt chính, dữ liệu chi tiết (giây, mili giây) chỉ cho các vùng mơ hồ về khớp lệnh.
Khi Nào Dùng Cái Gì: Khuyến Nghị Thực Tế
 Ma trận quyết định: các con đường phân kỳ cho việc tạo mẫu quy mô nhỏ so với pipeline sản xuất quy mô lớn
Ma trận quyết định: các con đường phân kỳ cho việc tạo mẫu quy mô nhỏ so với pipeline sản xuất quy mô lớn
Pandas được chấp nhận nếu:
- Tập dữ liệu đến 1M hàng và bạn không thực hiện GroupBy trên hàng trăm nhóm — sự khác biệt giữa Pandas 2.2 và Polars thường không đáng kể (1.5-2x)
- Bạn cần
pandas-tahoặc các thư viện khác với API Pandas — viết lại 130 chỉ báo là không thực tế cho một nghiên cứu một lần - Tạo mẫu nhanh — API Pandas quen thuộc hơn với hầu hết mọi người, và tốc độ không quan trọng để kiểm tra giả thuyết nhanh
- Tích hợp với mã cũ — một pipeline Pandas hiện có hoạt động tốt và không cần tối ưu hóa
Polars là cần thiết nếu:
- Tập dữ liệu từ 10M hàng — hàng chục và hàng trăm triệu hàng dữ liệu tick, bộ nhớ đệm đa khung thời gian
- Rolling theo nhóm — 100+ công cụ, chỉ báo cho mỗi cái: tốc độ tăng 100-3500 lần
- Pipeline ETL — tải, làm sạch, biến đổi khối lượng dữ liệu lớn
- RAM hạn chế — lazy evaluation và engine streaming cho phép xử lý dữ liệu không vừa trong bộ nhớ
- Stack Parquet/QuestDB — Arrow gốc = zero-copy, predicate pushdown, projection pushdown
Những Gì Không Nên Mong Đợi
Con số marketing "nhanh hơn 30 lần" là tốc độ tăng tối đa trên các thao tác cụ thể. Tốc độ tăng thực tế trên các thao tác pipeline điển hình: 2-10 lần. Trên rolling theo nhóm — nhiều hơn đáng kể. Trên tập dữ liệu nhỏ — đôi khi Polars thậm chí còn chậm hơn do chi phí overhead.
Kinh Nghiệm của Chúng Tôi tại marketmaker.cc
 Các chỉ số sản xuất: tốc độ pipeline tăng 6-8 lần và nhiều hơn 8 lần số lần lặp tối ưu hóa mỗi giờ
Các chỉ số sản xuất: tốc độ pipeline tăng 6-8 lần và nhiều hơn 8 lần số lần lặp tối ưu hóa mỗi giờ
Tại marketmaker.cc, chúng tôi sử dụng kiến trúc hybrid Polars + Numba cho engine backtest. Toàn bộ pipeline dữ liệu — tải từ bộ nhớ đệm Parquet, tính chỉ báo, lọc, kỹ thuật đặc trưng — chạy trên Polars. Mô phỏng danh mục chạy trên Numba.
Chuyển đổi từ Pandas sang Polars trong pipeline dữ liệu cho tốc độ tăng 6-8 lần trên các tập dữ liệu điển hình của chúng tôi (50-100M hàng, 200+ công cụ). Tính toán chỉ báo rolling theo nhóm giảm từ vài phút xuống còn hàng trăm mili giây. Điều này cho phép chúng tôi tăng số lần lặp tối ưu hóa từ ~500 lên ~4000 mỗi giờ mà không thay đổi phần cứng.
Điểm quan trọng: chúng tôi không di chuyển tất cả mã trong một ngày. Đầu tiên chúng tôi chuyển I/O (đọc Parquet), sau đó tính chỉ báo, rồi lọc và kỹ thuật đặc trưng. Pandas vẫn còn trong giao diện với các thành phần cũ kỳ vọng pd.DataFrame. Việc chuyển đổi df.to_pandas() / pl.from_pandas() mất vài mili giây và không phải là nút cổ chai.
Các chỉ số được tính toán trong giai đoạn backtest — bao gồm PnL theo Thời Gian Hoạt Động — đã được tính trên các DataFrame Polars, giúp đơn giản hóa pipeline và loại bỏ các chuyển đổi trung gian.
Kết Luận
 Ba luồng công nghệ hội tụ: Polars, Numba và Arrow kết hợp thành một pipeline được tối ưu hóa duy nhất
Ba luồng công nghệ hội tụ: Polars, Numba và Arrow kết hợp thành một pipeline được tối ưu hóa duy nhất
Polars không phải là sự thay thế cho Pandas trong mọi tình huống. Đây là công cụ của một đẳng cấp khác tỏa sáng ở các quy mô điển hình của algotrading nghiêm túc: hàng triệu và hàng trăm triệu hàng, hàng chục và hàng trăm công cụ, tối ưu hóa tham số liên tục.
Các con số chính:
- Thao tác cơ bản: tốc độ tăng 2-10 lần trên các tác vụ pipeline điển hình
- Rolling theo nhóm: 10-3500 lần — tính năng killer chính cho các pipeline giao dịch
- CSV I/O: tới 25 lần — quan trọng để tải dữ liệu ban đầu
- Bộ nhớ: tiết kiệm 2-6 lần nhờ Arrow và lazy evaluation
- Streaming: xử lý dữ liệu không vừa trong RAM
Kiến trúc được khuyến nghị cho engine backtest sản xuất:
- Polars — toàn bộ pipeline dữ liệu: tải, chỉ báo, lọc, đặc trưng
- Numba/Rust — mô phỏng danh mục: logic lệnh và vị thế phụ thuộc đường dẫn
- Arrow — định dạng dữ liệu tại tất cả các điểm nối: Parquet, QuestDB, Polars, NumPy
Không có lớp Pandas trung gian. Dữ liệu chảy từ bộ lưu trữ qua Polars vào các mảng NumPy và sau đó vào engine Numba — không có bản sao không cần thiết, không có GIL, không có nút cổ chai đơn luồng.
Liên Kết Hữu Ích
- Polars — Hướng Dẫn Người Dùng
- Polars vs Pandas — benchmark chính thức
- PDS-H Benchmark — so sánh các thư viện DataFrame
- Apache Arrow — đặc tả định dạng cột
- Numba — trình biên dịch JIT cho Python
- vectorbt — framework backtesting
- pandas-ta — Chỉ Báo Phân Tích Kỹ Thuật
- Ritchie Vink — Tôi đã viết một trong những thư viện DataFrame nhanh nhất (nguồn gốc Polars)
- Towards Data Science — Polars vs Pandas: benchmark thực tế
- Ernest Chan — Giao Dịch Định Lượng
Trích Dẫn
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/vi/blog/post/polars-vs-pandas-algotrading},
description = {So sánh chi tiết Polars và Pandas trên các tác vụ algotrading: benchmark cho lọc, tổng hợp, tính toán tín hiệu rolling, I/O và mức tiêu thụ bộ nhớ. Kiến trúc hybrid Polars + Numba để đạt hiệu suất backtest tối đa.}
}
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Đọc Thêm
OneTick: Nền Tảng Mà Các Sàn Giao Dịch Dùng Để Bắt Kẻ Giả Lệnh và Quỹ Đầu Cơ Dùng Để Săn Alpha

T-Bricks (Broadridge): Cách Nền Tảng Phục Vụ Các Công Ty Prop Hoạt Động