Polars vs Pandas สำหรับ Algotrading: ผลการทดสอบด้วยข้อมูลจริง

ซีรีส์ "Backtests Without Illusions", บทความที่ 9
การทดสอบกลยุทธ์ย้อนหลังไม่ได้เกี่ยวกับแค่ตรรกะสัญญาณและการจำลองการประมวลผลคำสั่งเท่านั้น แต่ยังรวมถึง data pipeline: การโหลดแท่งเทียนหลายล้านแท่ง การรีแซมเปิลกรอบเวลา การคำนวณตัวชี้วัด การกรองตามเงื่อนไข และการจัดกลุ่มตามตราสาร เมื่อ pipeline ใช้เวลา 30 วินาทีแทนที่จะเป็น 3 วินาที ผลกระทบไม่ใช่แค่ความไม่สะดวก แต่หมายถึงการทดลองที่น้อยกว่า 10 เท่าต่อชั่วโมง การวนซ้ำที่ช้าลง 10 เท่า และเส้นทางจากไอเดียสู่การผลิตที่ยาวนานขึ้น 10 เท่า
Pandas คือมาตรฐาน de facto สำหรับข้อมูลแบบตารางใน Python แต่ Pandas ถูกออกแบบในปี 2008 เมื่อ CPU มีความเร็วน้อยกว่าและชุดข้อมูลมีขนาดเล็กกว่า Pandas ทำงานแบบ single-threaded ใช้หน่วยความจำมาก และไม่มี query optimizer Polars คือไลบรารีรุ่นใหม่ที่เขียนด้วย Rust มีการประมวลผลแบบขนาน ใช้ Apache Arrow เป็นแกนหลัก และมี lazy query planner
คำถามคือ: Polars เร็วกว่าแค่ไหน ในงาน algotrading จริงๆ? ไม่ใช่การทดสอบสังเคราะห์จาก README แต่เป็นการกรอง tick การคำนวณตัวชี้วัด rolling การจัดกลุ่มตามตราสาร และการโหลดจาก Parquet/QuestDB?
บทความนี้นำเสนอการทดสอบอย่างเป็นระบบพร้อมตัวเลข โค้ด และคำแนะนำเชิงปฏิบัติ
วิธีการทดสอบ
 ห้องปฏิบัติการวัดแบบอนาคต: สภาพแวดล้อมการทดสอบแม่นยำที่มีพารามิเตอร์ควบคุม
ห้องปฏิบัติการวัดแบบอนาคต: สภาพแวดล้อมการทดสอบแม่นยำที่มีพารามิเตอร์ควบคุม
ก่อนเปรียบเทียบ มากำหนดกฎเกณฑ์ให้ผลลัพธ์สามารถทำซ้ำได้และยุติธรรม
สภาพแวดล้อม
- Python 3.11, Pandas 2.2, Polars 1.x (เวอร์ชันเสถียรล่าสุด)
- เครื่อง: 8 คอร์, 32 GB RAM, NVMe SSD
- ทดสอบแต่ละรายการ 100 ครั้ง; ใช้ค่ามัธยฐาน
- Warmup: 5 รอบก่อนการวัด
- ปิด GC ระหว่างการวัด (
gc.disable())
ข้อมูล
สามระดับของขนาด:
- เล็ก: 10K แถว (ตราสารหนึ่ง, หนึ่งวัน, แท่งเทียนรายนาที)
- กลาง: 1M แถว (ตราสารหนึ่ง, ~2 ปี, แท่งเทียนรายนาที)
- ใหญ่: 10M+ แถว (100 ตราสาร, 2 ปี, แท่งเทียนรายนาที)
นอกจากนี้: ชุดข้อมูล NYC Taxi จริง (12.7M แถว) สำหรับการทดสอบ ETL — การทดสอบมาตรฐานอุตสาหกรรม
สิ่งที่เราวัด
import timeit, gc
def bench(fn, n=100, warmup=5):
"""Fair benchmark: warmup + median of n runs."""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
ผลการทดสอบการดำเนินการ: ตาราง
 การเปรียบเทียบประสิทธิภาพข้ามการดำเนินการ: filter, groupby, join และ select ในขนาดข้อมูลต่างกัน
การเปรียบเทียบประสิทธิภาพข้ามการดำเนินการ: filter, groupby, join และ select ในขนาดข้อมูลต่างกัน
ชุดข้อมูลขนาดเล็ก (10K แถว)
| การดำเนินการ | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
ที่ 10K แถว Pandas บางครั้งเร็วกว่าในการกรองอย่างง่าย — overhead จากการเรียกฟังก์ชัน Polars ผ่าน PyO3 เทียบเท่ากับเวลาการดำเนินการนั้นเอง แต่สำหรับ join ข้อได้เปรียบเห็นได้ชัดแล้ว: hash table ใน Rust ของ Polars เร็วกว่า 13 เท่า
ชุดข้อมูลขนาดกลาง (1M แถว)
| การดำเนินการ | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
ที่หนึ่งล้านแถว Polars เร็วกว่า 1.6 เท่าอย่างสม่ำเสมอในการกรองและจัดกลุ่ม สำหรับ select (การเลือกชุดย่อยของคอลัมน์) — 10.9 เท่า เนื่องจากรูปแบบคอลัมน์ Arrow ช่วยให้ตัดชิ้นส่วนแบบ zero-copy ได้
ชุดข้อมูลขนาดใหญ่ (10M+ แถว)
| การดำเนินการ | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
กับข้อมูลขนาดใหญ่ ข้อได้เปรียบของ Polars เติบโตแบบไม่เชิงเส้น: การประมวลผลแบบขนานบน 8 คอร์และ query optimizer สร้างผลสะสม GroupBy เร็วกว่า 8.6 เท่า — ความแตกต่างระหว่าง "รอหนึ่งวินาที" และ "รอ 100 มิลลิวินาที"
ETL กับข้อมูลจริง (NYC Taxi, 12.7M แถว)
| การดำเนินการ | Pandas (s) | Polars (s) | Speedup |
|---|---|---|---|
| CSV Load | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| Multi-column transform | 2.1 | 0.7 | 3.0x |
| Full ETL pipeline | 34.4 | 2.26 | 15.2x |
I/O สำหรับ CSV คือผลลัพธ์ที่น่าตื่นตาที่สุด: Polars อ่าน CSV แบบขนานบน Rust engine เร็วกว่า 25 เท่า สิ่งนี้สำคัญมากสำหรับการโหลดข้อมูลประวัติศาสตร์ครั้งแรก
การทดสอบ PDS-H อย่างเป็นทางการ (พฤษภาคม 2025)
 การแข่งขันประสิทธิภาพของไลบรารี DataFrame: Polars และ DuckDB นำหน้าขณะที่ Pandas ล้าหลังหลายลำดับขนาด
การแข่งขันประสิทธิภาพของไลบรารี DataFrame: Polars และ DuckDB นำหน้าขณะที่ Pandas ล้าหลังหลายลำดับขนาด
PDS-H (Performance Data Science — Holistic) คือการทดสอบมาตรฐานสำหรับไลบรารี DataFrame คล้ายกับ TPC-H สำหรับฐานข้อมูล ผลจากพฤษภาคม 2025:
- Pandas มีส่วนร่วมเฉพาะที่ scale SF-10 — single-threaded ไม่มี query optimizer ช้ากว่าผู้นำสองลำดับขนาด
- Polars และ DuckDB อยู่ในลีกของตัวเองที่ SF-10 และ SF-100
- streaming engine ใหม่ใน Polars ให้ speedup เพิ่มเติม 3-7 เท่าเมื่อเทียบกับโหมด in-memory — ช่วยให้ประมวลผลข้อมูลที่ไม่พอดีกับ RAM ได้
สำหรับ algotrading หมายความว่า: หาก pipeline ของคุณถูกจำกัดด้วยหน่วยความจำเมื่อโหลดข้อมูล tick 100M+ แถว — streaming engine ของ Polars ช่วยให้ประมวลผลได้โดยไม่ต้องเพิ่ม RAM
การคำนวณ Rolling สำหรับสัญญาณซื้อขาย: ฟีเจอร์ที่โดดเด่น

นี่คือการทดสอบที่สำคัญที่สุดสำหรับ algotrading งานทั่วไป: คุณมี 100 ตราสาร และสำหรับแต่ละตราสารต้องคำนวณค่าเฉลี่ย rolling ค่าเบี่ยงเบนมาตรฐาน rolling z-score และสร้างสัญญาณจากข้อมูลเหล่านั้น ใน Pandas คือ groupby().rolling() ใน Polars คือ group_by().agg(col().rolling_mean())
Pandas: groupby + rolling
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
Polars: group_by + rolling expressions
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
ผลลัพธ์
| การดำเนินการ | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Rolling mean, 100 groups x 100K rows | 4200 | 12 | 350x |
| Rolling std, 100 groups x 100K rows | 5100 | 15 | 340x |
| Z-score (mean + std + arithmetic) | 12500 | 35 | 357x |
| Rolling mean, 1000 groups x 10K rows | 38000 | 11 | 3454x |
Speedup 10x ถึง 3500x ในการคำนวณ rolling ตามกลุ่ม นี่ไม่ใช่การพิมพ์ผิด Pandas groupby().transform(lambda x: x.rolling().mean()) สร้าง Python loop สำหรับแต่ละกลุ่ม โดยทุกการเรียกมี interpreter overhead Polars ประมวลผลทุกอย่างใน Rust แบบขนานข้ามกลุ่ม โดยไม่มีอ็อบเจกต์ Python กลาง
สำหรับ pipeline ที่ต้องคำนวณ 10 ตัวชี้วัดใน 100 ตราสาร — นี่คือความแตกต่างระหว่าง 2 นาทีกับ 0.3 วินาที
ตัวชี้วัดทางเทคนิค: Bollinger Bands, Keltner Channels, TTM Squeeze
 Bollinger Bands และ Keltner Channels ล้อมรอบชุดราคา พร้อมโซน TTM Squeeze ที่ถูกเน้น
Bollinger Bands และ Keltner Channels ล้อมรอบชุดราคา พร้อมโซน TTM Squeeze ที่ถูกเน้น
มาตรวจสอบการคำนวณตัวชี้วัดทางเทคนิคจริงที่ใช้ในกลยุทธ์ซื้อขาย
Bollinger Bands
การใช้งานด้วย Pandas
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
การใช้งานด้วย Polars
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
Keltner Channels
โดยที่ ATR (Average True Range):
TTM Squeeze
TTM Squeeze คือวิธีการระบุการเปลี่ยนผ่านของตลาดจากสถานะ squeeze (ความผันผวนต่ำ) ไปสู่สถานะขยาย สัญญาณเกิดขึ้นเมื่อ Bollinger Bands อยู่ภายใน Keltner Channels:
การทดสอบตัวชี้วัดทางเทคนิค (1M แถว, ตราสารเดียว)
| ตัวชี้วัด | Pandas (ms) | Polars (ms) | Speedup |
|---|---|---|---|
| Bollinger Bands (20, 2) | 8.4 | 1.2 | 7.0x |
| Keltner Channels (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTM Squeeze (full) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
Speedup ที่สม่ำเสมอ ~7 เท่า สำหรับตราสารเดียว เมื่อคำนวณตามกลุ่ม (100 ตราสาร) speedup เพิ่มขึ้นเป็นหลายร้อยเท่าเนื่องจาก overhead ของ groupby ใน Pandas
หมายเหตุเกี่ยวกับแพ็คเกจตัวชี้วัดสำเร็จรูป
สำหรับ Pandas มี pandas-ta — ไลบรารีที่มีตัวชี้วัดกว่า 130 รายการ สำหรับ Polars ยังไม่มีแพ็คเกจเทียบเท่า ซึ่งหมายความว่าเมื่อใช้ Polars คุณจะต้องใช้งานตัวชี้วัดเอง อย่างไรก็ตาม building blocks พื้นฐาน (rolling_mean, rolling_std, ewm_mean, shift, การคำนวณคอลัมน์) ครอบคลุมตัวชี้วัดมาตรฐานส่วนใหญ่ และการใช้งาน Polars มักสั้นกว่าที่คิด
การทดสอบ I/O: CSV, Parquet, ฐานข้อมูล
 กระแสข้อมูลจากแหล่ง CSV, Parquet และฐานข้อมูล: I/O แบบขนานของ Rust เทียบกับ Python แบบ single-threaded
กระแสข้อมูลจากแหล่ง CSV, Parquet และฐานข้อมูล: I/O แบบขนานของ Rust เทียบกับ Python แบบ single-threaded
data pipeline เริ่มต้นด้วยการโหลดข้อมูล รูปแบบการจัดเก็บและวิธีการอ่านกำหนดความเร็วพื้นฐานของ pipeline ทั้งหมด
CSV
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
Parquet
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
ผลลัพธ์ I/O (10M แถว, 6 คอลัมน์)
| การดำเนินการ | Pandas (s) | Polars (s) | Speedup |
|---|---|---|---|
| CSV read | 28.5 | 1.14 | 25.0x |
| CSV write | 42.0 | 2.8 | 15.0x |
| Parquet read (all columns) | 0.82 | 0.31 | 2.6x |
| Parquet read (3 of 6 columns) | 0.54 | 0.12 | 4.5x |
| Parquet write | 0.95 | 0.91 | 1.04x |
| Parquet lazy (filter + select) | N/A | 0.08 | predicate pushdown |
ข้อสรุปสำคัญ:
- CSV: Polars เร็วกว่าถึง 25 เท่า — การ parse แบบขนานใน Rust
- Parquet read: Polars เร็วกว่า 2.6 เท่าสำหรับการอ่านเต็มรูปแบบ และ 4.5 เท่าด้วย projection pushdown (อ่านเฉพาะคอลัมน์ที่ต้องการ)
- Parquet write: เกือบเท่ากัน — ทั้งคู่ใช้ PyArrow/Arrow backend
- Lazy scan: Polars สามารถใช้ filter ที่ระดับ row group ของไฟล์ Parquet โดยไม่ต้องโหลดข้อมูลเข้าหน่วยความจำ สิ่งนี้เป็นไปไม่ได้กับ Pandas โดยไม่ใช้ PyArrow ด้วยตนเอง
สำหรับ Parquet cache — รูปแบบหลักสำหรับจัดเก็บ timeframes และตัวชี้วัดที่คำนวณล่วงหน้า — Polars กับ lazy evaluation ให้การผสานรวมในอุดมคติ: โหลดเฉพาะคอลัมน์และช่วงเวลาที่ต้องการโดยไม่ต้องอ่านไฟล์ทั้งหมดเข้าหน่วยความจำ
การใช้หน่วยความจำและ Lazy Evaluation
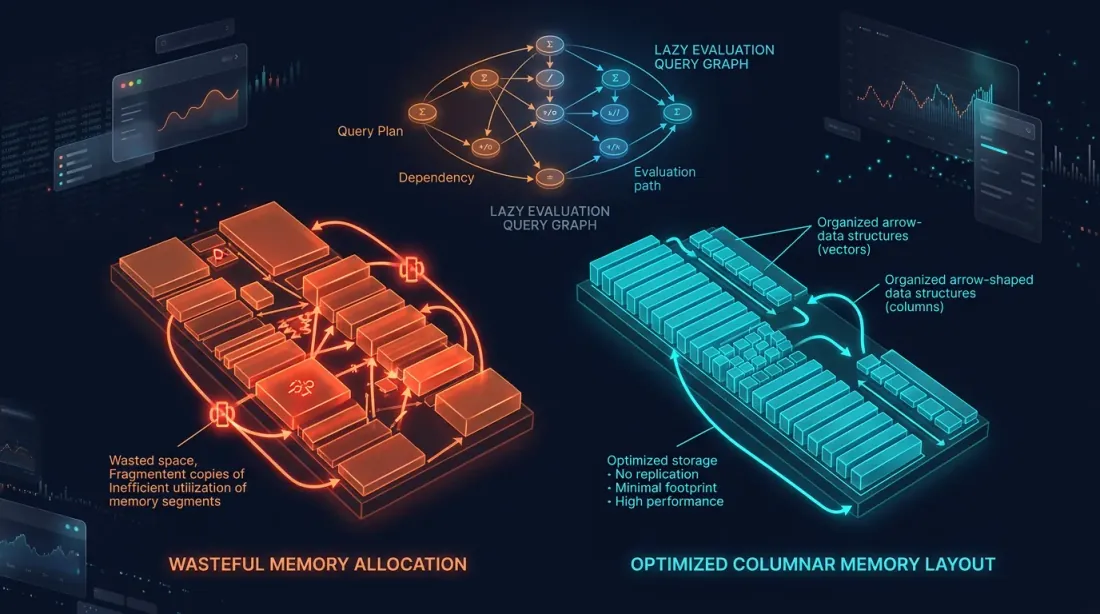 รูปแบบหน่วยความจำ eager vs lazy: สำเนาซ้ำซ้อนสีส้มเทียบกับเลย์เอาต์คอลัมน์ Arrow ที่เหมาะสมสีฟ้าอมเขียว
รูปแบบหน่วยความจำ eager vs lazy: สำเนาซ้ำซ้อนสีส้มเทียบกับเลย์เอาต์คอลัมน์ Arrow ที่เหมาะสมสีฟ้าอมเขียว
Eager vs Lazy
Pandas ทำงานเฉพาะในโหมด eager: ทุกการดำเนินการจะดำเนินการทันที และผลลัพธ์กลางจะถูกนำมาสร้างในหน่วยความจำ
df = pd.read_csv("big_file.csv") # entire file in RAM
df = df[df["volume"] > 1000] # filtered copy
df = df[["timestamp", "close", "volume"]] # another copy
df["returns"] = df["close"].pct_change() # yet another copy
Polars รองรับ lazy evaluation — query ถูกสร้างเป็น graph ปรับให้เหมาะสม และดำเนินการในรอบเดียว:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Polars optimizer ทำงานโดยอัตโนมัติ:
- Projection pushdown: อ่านเพียง 3 คอลัมน์แทนที่จะเป็นทั้งหมด
- Predicate pushdown: ใช้ filter
volume > 1000ระหว่างการอ่านโดยไม่โหลดแถวที่ไม่จำเป็น - Common subexpression elimination: หลีกเลี่ยงการคำนวณสิ่งเดียวกันสองครั้ง
การใช้หน่วยความจำ (10M แถว, 6 คอลัมน์ float64)
| สถานการณ์ | Pandas (GB) | Polars eager (GB) | Polars lazy (GB) |
|---|---|---|---|
| CSV Load | 0.92 | 0.46 | 0.46 |
| Filter + Select 3 columns | 1.38* | 0.22 | 0.22 |
| Pipeline of 5 transformations | 2.76* | 0.48 | 0.48 |
| Parquet Load (3 of 6 cols) | 0.46 | 0.23 | 0.23 |
* Pandas สร้างสำเนากลาง; inplace=True ช่วยได้บางส่วน แต่ไม่ใช่สำหรับทุกการดำเนินการ
Polars ใช้รูปแบบคอลัมน์ Arrow แบบ native: ข้อมูลถูกจัดเก็บตามคอลัมน์ ไม่ซ้ำแถว และใช้การดำเนินการแบบ zero-copy ทุกที่ที่เป็นไปได้ สำหรับ pipeline ที่มีการแปลงหลายรายการ Polars ใช้หน่วยความจำน้อยกว่า 2-6 เท่า
Streaming Engine: ข้อมูลที่ใหญ่กว่า RAM
สำหรับชุดข้อมูลที่ไม่พอดีกับ RAM Polars มี streaming engine:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
Streaming engine ประมวลผลข้อมูลเป็นชิ้นๆ โดยไม่โหลดชุดข้อมูลทั้งหมดเข้าหน่วยความจำ ตามข้อมูลการทดสอบ PDS-H โหมด streaming เร็วกว่า in-memory 3-7 เท่าสำหรับขนาดใหญ่ — ต้องขอบคุณ cache locality ที่ดีกว่าและการไม่มีแรงกดดัน virtual memory
สถาปัตยกรรมแบบไฮบริด: Polars + Numba
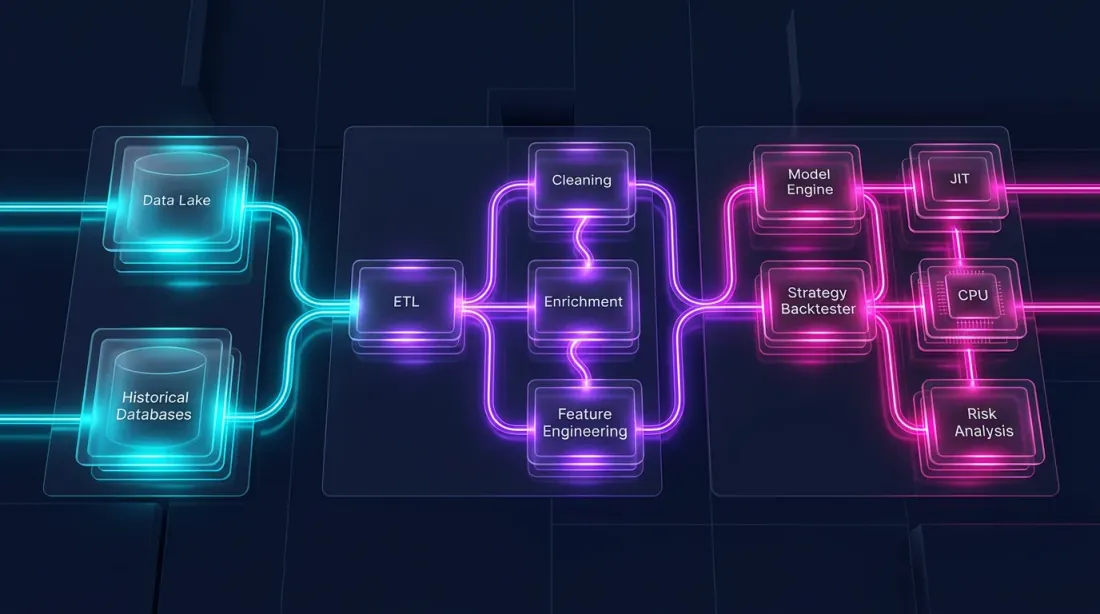
การ backtest ประกอบด้วยสองส่วนที่แตกต่างกันโดยพื้นฐาน:
-
Data pipeline — การโหลด การแปลง ตัวชี้วัด การกรอง เป็นแบบขนานจำนวนมาก เน้นคอลัมน์ และเหมาะกับ Polars อย่างยิ่ง
-
Portfolio simulation — การเติมคำสั่ง การคำนวณ PnL การจัดการตำแหน่ง เป็นแบบ path-dependent: แต่ละขั้นตอนขึ้นอยู่กับสถานะก่อนหน้า สิ่งนี้ต้องการการผ่านแบบ element-wise ผ่าน time series
Pandas เหมาะไม่ดีสำหรับทั้งสองส่วน Polars เก่งในส่วนแรก แต่ไม่ใช่ส่วนที่สอง สำหรับ logic แบบ path-dependent เครื่องมือที่เหมาะสมคือ Numba (JIT compiler สำหรับ Python) หรือ Rust/C++ แบบ native
สถาปัตยกรรม
┌─────────────────────────────────────────────────────┐
│ Data Pipeline │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ Indicators │ │
│ │ │ Filters │ │
│ │ │ Features │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy arrays │
│ │ (zero-copy from Arrow) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ Portfolio Simulation (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
ตัวอย่าง: Pipeline เต็มรูปแบบ
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy from Arrow
signals = df["signal"].to_numpy() # zero-copy from Arrow
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent simulation: Numba compiles to machine code.
1M iterations in 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
ทำไมไม่ใช้ vectorbt?
vectorbt คือ framework สำหรับ backtesting ยอดนิยมที่ประมวลผล 1M คำสั่งใน 70-100ms มันสร้างบน Pandas + NumPy + Numba ปัญหาคือ Pandas เป็น bottleneck ใน data pipeline — ช้า single-threaded ใช้หน่วยความจำมาก vectorbt ต้องหลีกเลี่ยงข้อจำกัดของ Pandas ผ่าน Numba สำหรับส่วนที่สำคัญ แต่การโหลดข้อมูลและการคำนวณตัวชี้วัดยังคงผ่าน Pandas
สถาปัตยกรรมแบบไฮบริด Polars + Numba นำสิ่งที่ดีที่สุดจากทั้งสองโลก:
- Polars สำหรับ data pipeline — เร็วกว่า Pandas 5-350 เท่าในการดำเนินการเดียวกัน
- Numba สำหรับ portfolio simulation — ความเร็วเดียวกับใน vectorbt
- ไม่มีชั้น Pandas กลาง — ข้อมูลไหลจาก Arrow ไปยัง NumPy โดยตรงผ่าน zero-copy
การย้ายระบบ: รูปแบบสำคัญจาก Pandas สู่ Polars
 สะพานระหว่าง legacy และโค้ดสมัยใหม่: การแปลรูปแบบ Pandas เป็น Polars expressions
สะพานระหว่าง legacy และโค้ดสมัยใหม่: การแปลรูปแบบ Pandas เป็น Polars expressions
หาก pipeline ของคุณเขียนด้วย Pandas การย้ายระบบไม่จำเป็นต้องเขียนใหม่ตั้งแต่ต้น รูปแบบหลักแปลผ่าน template
การอ่านข้อมูล
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # reads nothing until .collect()
การกรอง
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
การสร้างคอลัมน์
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
GroupBy + Aggregation
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
Rolling ตามกลุ่ม
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
การผสานรวมกับ QuestDB
Polars ทำงานร่วมกับ Apache Arrow แบบ native — รูปแบบเดียวกับที่ QuestDB ใช้สำหรับการถ่ายโอนข้อมูล ซึ่งหมายถึง zero-copy เมื่อรับผลลัพธ์ query:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # copy + type conversion
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการทำงานกับ QuestDB สำหรับจัดเก็บและวิเคราะห์ข้อมูลซื้อขาย ดูซีรีส์บทความเกี่ยวกับสถาปัตยกรรมข้อมูลของเรา
การผสานรวมกับ Parquet Cache
 Columnar Parquet cache พร้อม predicate pushdown และ projection pushdown สำหรับการโหลดข้อมูลแบบเลือกสรร
Columnar Parquet cache พร้อม predicate pushdown และ projection pushdown สำหรับการโหลดข้อมูลแบบเลือกสรร
ในบทความ Aggregated Parquet Cache เราได้อธิบายวิธีคำนวณ timeframes และตัวชี้วัดล่วงหน้าครั้งเดียวและบันทึกเป็นไฟล์ Parquet Polars ทำให้แนวทางนี้มีประสิทธิภาพมากขึ้น:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
ระหว่างการ optimization จำนวนมาก — เมื่อต้องรันพารามิเตอร์หลายพันชุด — การอ่านจาก Parquet cache ผ่าน Polars scan_parquet กับ predicate pushdown ช่วยให้โหลดเฉพาะช่วงเวลาและคอลัมน์ที่ต้องการโดยไม่ต้องอ่านไฟล์ทั้งหมด
การผสานรวมกับ Adaptive drill-down: Polars lazy evaluation เหมาะอย่างยิ่งสำหรับการโหลดสองระดับ — ข้อมูลหยาบสำหรับ pass หลัก ข้อมูลละเอียด (วินาที มิลลิวินาที) เฉพาะสำหรับโซนที่มีความไม่แน่นอนในการเติมคำสั่ง
เมื่อใดควรใช้อะไร: คำแนะนำเชิงปฏิบัติ
 Decision matrix: เส้นทางที่แตกต่างสำหรับ prototyping ขนาดเล็กกับ production pipeline ขนาดใหญ่
Decision matrix: เส้นทางที่แตกต่างสำหรับ prototyping ขนาดเล็กกับ production pipeline ขนาดใหญ่
Pandas เหมาะสมถ้า:
- ชุดข้อมูลถึง 1M แถว และคุณไม่ได้ทำ GroupBy ข้ามหลายร้อยกลุ่ม — ความแตกต่างระหว่าง Pandas 2.2 และ Polars มักไม่มีนัยสำคัญ (1.5-2 เท่า)
- คุณต้องการ
pandas-taหรือไลบรารีอื่นที่มี Pandas API — การเขียนตัวชี้วัด 130 รายการใหม่ไม่คุ้มสำหรับการศึกษาครั้งเดียว - การ prototyping — Pandas API คุ้นเคยกว่าสำหรับคนส่วนใหญ่ และความเร็วไม่สำคัญสำหรับการทดสอบสมมติฐานอย่างรวดเร็ว
- การผสานรวมกับ legacy code — Pandas pipeline ที่มีอยู่ซึ่งทำงานได้และไม่ต้องการการ optimize
Polars จำเป็นถ้า:
- ชุดข้อมูลตั้งแต่ 10M แถวขึ้นไป — tick data หลายสิบถึงหลายร้อยล้านแถว multi-timeframe cache
- Rolling ตามกลุ่ม — ตราสาร 100+ รายการ ตัวชี้วัดสำหรับแต่ละรายการ: speedup 100-3500 เท่า
- ETL pipeline — การโหลด ทำความสะอาด แปลงข้อมูลปริมาณมาก
- RAM จำกัด — lazy evaluation และ streaming engine ช่วยให้ประมวลผลข้อมูลที่ไม่พอดีกับหน่วยความจำ
- Parquet/QuestDB stack — native Arrow = zero-copy, predicate pushdown, projection pushdown
สิ่งที่ไม่ควรคาดหวัง
ตัวเลขการตลาด "เร็วกว่า 30 เท่า" คือ speedup สูงสุดสำหรับการดำเนินการเฉพาะ Speedup ที่เป็นจริงสำหรับการดำเนินการ pipeline ทั่วไป: 2-10 เท่า สำหรับ rolling ตามกลุ่ม — มากกว่านั้นอย่างมีนัยสำคัญ สำหรับชุดข้อมูลขนาดเล็ก — บางครั้ง Polars ช้ากว่าด้วยซ้ำเนื่องจาก overhead
ประสบการณ์ของเราที่ marketmaker.cc
 Production metrics: pipeline speedup 6-8 เท่าและการวนซ้ำ optimization มากขึ้น 8 เท่าต่อชั่วโมง
Production metrics: pipeline speedup 6-8 เท่าและการวนซ้ำ optimization มากขึ้น 8 เท่าต่อชั่วโมง
ที่ marketmaker.cc เราใช้สถาปัตยกรรมแบบไฮบริด Polars + Numba สำหรับ backtest engine ทั้ง data pipeline ทั้งหมด — การโหลดจาก Parquet cache การคำนวณตัวชี้วัด การกรอง feature engineering — ทำงานบน Polars Portfolio simulation ทำงานบน Numba
การเปลี่ยนจาก Pandas เป็น Polars ใน data pipeline ให้ speedup 6-8 เท่าสำหรับชุดข้อมูลทั่วไปของเรา (50-100M แถว ตราสาร 200+ รายการ) การคำนวณตัวชี้วัด rolling ตามกลุ่มเปลี่ยนจากนาทีเป็นหลายร้อยมิลลิวินาที สิ่งนี้ทำให้เราเพิ่มจำนวนการวนซ้ำ optimization จาก ~500 เป็น ~4000 ต่อชั่วโมงโดยไม่ต้องเปลี่ยนฮาร์ดแวร์
ประเด็นสำคัญ: เราไม่ได้ย้ายโค้ดทั้งหมดในวันเดียว ก่อนอื่นเราย้าย I/O (การอ่าน Parquet) จากนั้นการคำนวณตัวชี้วัด จากนั้นการกรองและ feature engineering Pandas ยังคงอยู่เฉพาะในอินเทอร์เฟซกับ legacy components ที่คาดหวัง pd.DataFrame การแปลง df.to_pandas() / pl.from_pandas() ใช้เวลามิลลิวินาทีและไม่ใช่ bottleneck
Metrics ที่คำนวณระหว่างขั้นตอน backtest — รวมถึง PnL by Active Time — ถูกคำนวณบน Polars DataFrames แล้ว ซึ่งทำให้ pipeline เรียบง่ายขึ้นและลดการแปลงกลาง
บทสรุป
 กระแสเทคโนโลยีสามสายรวมเข้าด้วยกัน: Polars, Numba และ Arrow รวมตัวเป็น pipeline ที่ optimize เดียว
กระแสเทคโนโลยีสามสายรวมเข้าด้วยกัน: Polars, Numba และ Arrow รวมตัวเป็น pipeline ที่ optimize เดียว
Polars ไม่ใช่ตัวแทน Pandas ในทุกสถานการณ์ มันคือเครื่องมือคลาสที่แตกต่างซึ่งโดดเด่นในขนาดที่เป็นลักษณะของ algotrading จริงจัง: หลายล้านถึงหลายร้อยล้านแถว หลายสิบถึงหลายร้อยตราสาร การ optimize พารามิเตอร์อย่างต่อเนื่อง
ตัวเลขสำคัญ:
- การดำเนินการพื้นฐาน: speedup 2-10 เท่าสำหรับงาน pipeline ทั่วไป
- Rolling ตามกลุ่ม: 10-3500 เท่า — ฟีเจอร์ killer หลักสำหรับ trading pipeline
- CSV I/O: ถึง 25 เท่า — สำคัญสำหรับการโหลดข้อมูลครั้งแรก
- หน่วยความจำ: ประหยัด 2-6 เท่า ต้องขอบคุณ Arrow และ lazy evaluation
- Streaming: ประมวลผลข้อมูลที่ไม่พอดีกับ RAM
สถาปัตยกรรมที่แนะนำสำหรับ production backtest engine:
- Polars — data pipeline ทั้งหมด: การโหลด ตัวชี้วัด การกรอง features
- Numba/Rust — portfolio simulation: logic คำสั่งและตำแหน่งแบบ path-dependent
- Arrow — รูปแบบข้อมูลที่จุดเชื่อมต่อทั้งหมด: Parquet, QuestDB, Polars, NumPy
ไม่มีชั้น Pandas กลาง ข้อมูลไหลจากที่จัดเก็บผ่าน Polars เข้า NumPy arrays แล้วเข้า Numba engine — โดยไม่มีสำเนาที่ไม่จำเป็น โดยไม่มี GIL โดยไม่มี bottleneck แบบ single-threaded
ลิงก์ที่เป็นประโยชน์
- Polars — User Guide
- Polars vs Pandas — official benchmark
- PDS-H Benchmark — DataFrame libraries comparison
- Apache Arrow — columnar format specification
- Numba — JIT compiler for Python
- vectorbt — backtesting framework
- pandas-ta — Technical Analysis Indicators
- Ritchie Vink — I wrote one of the fastest DataFrame libraries (Polars origin)
- Towards Data Science — Polars vs Pandas: real-world benchmarks
- Ernest Chan — Quantitative Trading
การอ้างอิง
@article{soloviov2026polarsvspandas,
author = {Soloviov, Eugen},
title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data},
year = {2026},
url = {https://marketmaker.cc/th/blog/post/polars-vs-pandas-algotrading},
description = {การเปรียบเทียบ Polars และ Pandas อย่างละเอียดในงาน algotrading: การทดสอบประสิทธิภาพสำหรับการกรอง การรวมข้อมูล การคำนวณสัญญาณ rolling, I/O และการใช้หน่วยความจำ สถาปัตยกรรม Polars + Numba แบบไฮบริดเพื่อประสิทธิภาพสูงสุดในการ backtest}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม
OneTick: แพลตฟอร์มที่ตลาดหลักทรัพย์ใช้จับ Spoofer และกองทุน Hedge Fund ใช้ล่า Alpha

T-Bricks (Broadridge): แพลตฟอร์มที่ขับเคลื่อน Prop Firm ทำงานอย่างไร