カスケード戦略:優先実行とフォールバック補完

「幻想なきバックテスト」シリーズの完結編。N個の戦略をM個のペアで運用するオーケストレーターの構築方法、優先順位とフォールバック実行によるカスケードモードの実装、dual_sizeの選択、そして戦略ポートフォリオのPnLを単純合算ではバックテストできない理由を解説します。
戦略ポートフォリオが必要な理由
 複数の戦略が限られた資本を巡って競合し、任意の時点でトレードしているのはごく一部で、残りは待機状態にある
複数の戦略が限られた資本を巡って競合し、任意の時点でトレードしているのはごく一部で、残りは待機状態にある
あなたの戦略はパイプラインの全工程を通過しました。モンテカルロ・ブートストラップで許容可能な5パーセンタイルを示しました。ウォークフォワードでアウトオブサンプルのリターンを確認しました。ファンディングレートは考慮済み、プラトー分析も合格です。戦略は確かに機能しています。
しかし、トレードしている時間は15%だけです。残り85%の時間、あなたの資本は遊休状態です。
2番目の戦略を動かす?3番目?10番目?アイデアは明白です。実装はそうではありません。戦略ポートフォリオは、単一のボットでは存在しない問題を生み出します:
- 競合:2つの戦略が同じペアで反対のポジションを取ろうとする。
- 制約:取引所/リスク管理が同時ポジション数を以下に制限する。
- 配分:各戦略に資本の何割を割り当てるか?
- 相関:相関の高い暗号資産ペアで10戦略を走らせても10倍の分散にはならない。
カスケード戦略はこれらの問題を解決するアーキテクチャパターンです。プライマリ戦略がフルポジションサイズを取得し、フォールバック戦略がポジションを縮小して遊休時間を埋めます。
カスケードの概念:プライマリ+フォールバック

高確信度戦略(プライマリ)
プライマリは厳格なエントリー基準を持つ戦略です。例えば、3つの確認レベルを持つトリプルタイムフレーム:日足+4時間足+1時間足のシグナル、ボラティリティとボリュームのフィルタリング付き。
特徴:
- 少ないトレード数(バックテスト期間で数十回)
- トレードあたりの高いPnL
- ポジション保有時間の低さ(5-15%)
- 各エントリーへの高い確信度
フォールバック戦略
フォールバックは緩和された基準を持つ戦略です。デュアルタイムフレーム、少ないフィルター、広い許容範囲。より頻繁にトレードしますが、トレードあたりのエッジは低くなります。
特徴:
- 多いトレード数(期間中に数百回)
- トレードあたりの中程度のPnL
- ポジション保有時間の高さ(30-50%)
- 中程度の確信度 — ポジションサイズの縮小で補完
カスケードモード
timeline: ──────────────────────────────────────────────────
primary: ___████___________________████████____███________
fallback: ███____███████████████████________████___████████
capital: [dual][ full ][ dual_size ][ full ][ dual ]
プライマリがポジションを開くと、フォールバックは停止(またはクローズ)します。プライマリが待機中の時、フォールバックは縮小ポジション(dual_size)でトレードします。優先順位は無条件です:プライマリは常にフォールバックを置き換えます。
例題用の戦略
本シリーズを通じて3つの戦略を使用しました。750日間のパラメータは以下の通りです:
| パラメータ | 戦略A | 戦略B | 戦略C |
|---|---|---|---|
| PnL | +55% | +27% | +300% |
| トレード数 | 約500 | 約40 | 約400 |
| トレード時間 | 約15% | 約5% | 約45% |
| MaxDD | 約0.9% | 約0.75% | 約17% |
| PnL/アクティブ日 | 0.49%/日 | 0.72%/日 | 0.89%/日 |
| 特性 | 中程度の活動 | 低頻度、高確信度 | 高頻度、アグレッシブ |
アクティブ時間あたりのPnLで示したように、生のPnLによるランキングとPnL/アクティブ日によるランキングでは異なる結果が得られます。カスケードオーケストレーションにおいては、後者の指標が重要です。
最適なdual_size
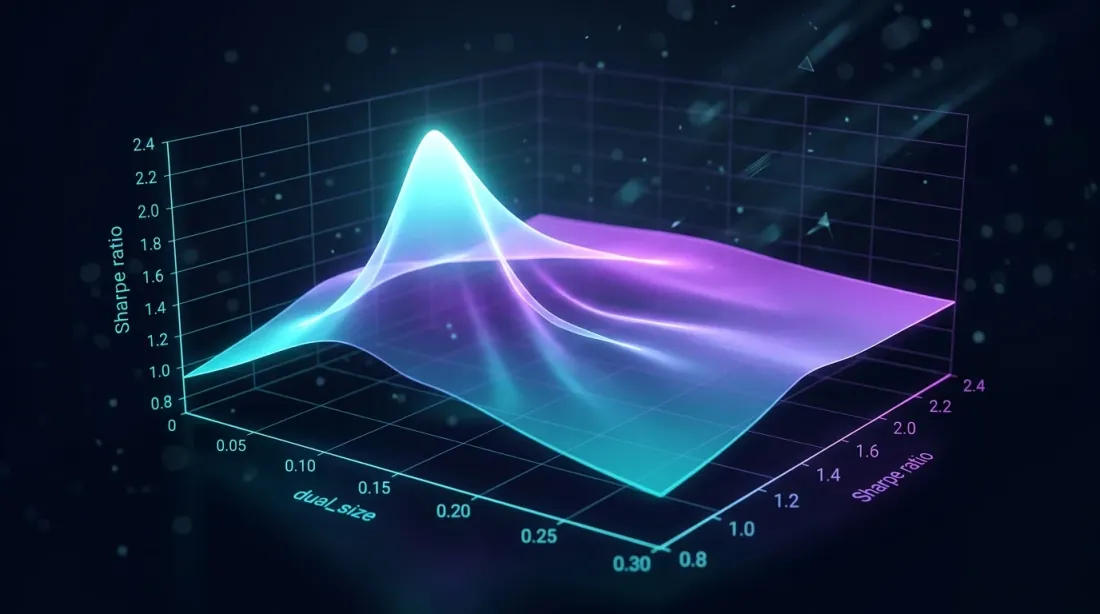 dual_sizeのグリッドサーチによりシャープレシオのピークが明らかになる — 大きすぎるとドローダウンが増加し、小さすぎると遊休時間を無駄にする
dual_sizeのグリッドサーチによりシャープレシオのピークが明らかになる — 大きすぎるとドローダウンが増加し、小さすぎると遊休時間を無駄にする
選択の問題
dual_sizeは、フォールバック戦略が受け取るフルポジションの割合です。これはカスケードの主要パラメータです:
-
大きすぎる場合(例:0.5 = 50%):プライマリとフォールバックが同時にアクティブな場合、総エクスポージャーはターゲットの150%に。ドローダウンが倍増します。損失-利益の非対称性により、これは不釣り合いに高コストとなります。
-
小さすぎる場合(例:0.01 = 1%):フォールバックは遊休時間の85%を埋めますが、利益はわずかです。資本は実質的に遊休状態です。
-
最適値:フォールバックがプライマリとの同時運用中にドローダウンを致命的に増加させることなく、意味のあるPnLを貢献する値。
定式化
以下を定義します:
- — 単位時間あたりのプライマリPnL
- — 単位時間あたりのフォールバックPnL
- — ポジション保有時間の割合(プライマリ)
- — ポジション保有時間の割合(フォールバック)
- — dual_size (0..1)
- — 両方がポジションを保有している時間の割合
カスケード合計PnL:
合計MaxDD(最悪ケース — 完全相関):
合計ドローダウンをに制約する場合:
グリッドサーチ
実務では、最適なdual_sizeはカスケードバックテストでのグリッドサーチにより求められます:
import numpy as np
from dataclasses import dataclass
@dataclass
class CascadeResult:
dual_size: float
total_pnl: float
max_dd: float
sharpe: float
pnl_per_active_day: float
def grid_search_dual_size(
primary_equity: np.ndarray, # equity curve primary (minute bars)
fallback_equity: np.ndarray, # equity curve fallback (minute bars)
primary_positions: np.ndarray, # 1 = in position, 0 = flat
fallback_positions: np.ndarray,
grid: np.ndarray = np.arange(0.01, 0.30, 0.005),
) -> list[CascadeResult]:
"""
Grid search for dual_size.
primary_equity and fallback_equity are log-returns, minute bars.
"""
results = []
for d in grid:
fallback_active = fallback_positions & ~primary_positions
cascade_returns = (
primary_equity * primary_positions
+ d * fallback_equity * fallback_active
)
equity_curve = np.cumprod(1 + cascade_returns)
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
max_dd = drawdown.min()
total_pnl = equity_curve[-1] - 1
sharpe = (
np.mean(cascade_returns) / np.std(cascade_returns)
* np.sqrt(525_600) # minutes per year
) if np.std(cascade_returns) > 0 else 0
active_minutes = np.sum(primary_positions | fallback_active)
active_days = active_minutes / (24 * 60)
pnl_per_day = total_pnl / active_days if active_days > 0 else 0
results.append(CascadeResult(
dual_size=d,
total_pnl=total_pnl,
max_dd=max_dd,
sharpe=sharpe,
pnl_per_active_day=pnl_per_day,
))
return sorted(results, key=lambda r: r.sharpe, reverse=True)
暗号資産戦略の典型的な最適値:dual_sizeは0.05-0.10(フルポジションの5-10%)の範囲。戦略Bをプライマリ(MaxDD 0.75%)、戦略Aをフォールバック(MaxDD 0.9%)とした場合:
ドローダウン制約はバインディングではありません — 最適値はカスケードのシャープレシオにより決定されます。実務では、グリッドサーチは通常(6.8%)を返します。
スコアベースのアロケーション
 複合スコアで戦略をランキング — 信頼度調整が小サンプルにペナルティを与え、ファンディングコストがネットエッジを減少させる
複合スコアで戦略をランキング — 信頼度調整が小サンプルにペナルティを与え、ファンディングコストがネットエッジを減少させる
2つ以上の戦略がある場合、カスケードはスコアベースのアロケーションに一般化されます。
アクティブ時間あたりのPnLによるランキング
アクティブ時間あたりのPnLで詳述されているように、戦略スコアは以下を考慮して計算されます:
- アクティブ日あたりのPnL — 資本利用効率
- 信頼度調整 — 小サンプルへのペナルティ(t分布)
- ファンディングコスト — レバレッジの実コスト(ファンディングレート)
- MaxLev — ドローダウンを考慮したスケーリング(損失-利益の非対称性)
低頻度戦略の信頼度調整
40回のトレードを持つ戦略Bには重大なペナルティが必要です。信頼区間の下限を使用します:
import scipy.stats as st
import numpy as np
def confidence_factor(trade_returns: np.ndarray, confidence: float = 0.95) -> float:
"""Confidence factor: 0..1, penalty for small samples."""
n = len(trade_returns)
if n < 10:
return 0.0
mean_r = np.mean(trade_returns)
if mean_r <= 0:
return 0.0
se = np.std(trade_returns, ddof=1) / np.sqrt(n)
t_crit = st.t.ppf(1 - (1 - confidence) / 2, df=n - 1)
ci_lower = mean_r - t_crit * se
return max(0.0, ci_lower / mean_r)
cf_b = confidence_factor(np.random.normal(0.0067, 0.028, 40))
cf_a = confidence_factor(np.random.normal(0.0011, 0.008, 500))
ファンディングコストの統合
無期限先物では、ファンディングは8時間ごとに支払われます。レバレッジ、平均レートの場合:
MaxLev = 55xの戦略Aで、平均ファンディングレート0.01%の場合:
PnL/アクティブ日 = 0.49%の場合、ネットPnLはマイナスになります:/日。フルレバレッジでは戦略は不採算です。詳細分析はファンディングレートがレバレッジを殺すを参照してください。
マルチ戦略オーケストレーター
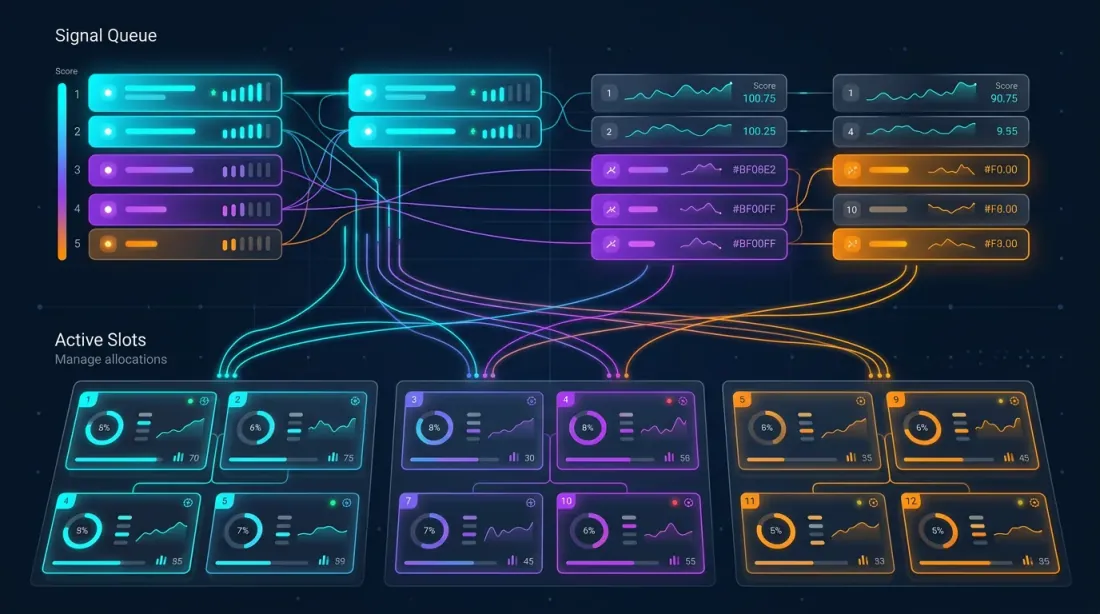
アーキテクチャ
オーケストレーターは個のトレーディングペアで個の戦略を管理します。潜在的なポジションの総数:。しかし資本は限られており、同時ポジション(スロット)は個以下に制限されています。
┌─────────────────────────────────────────────┐
│ ORCHESTRATOR │
│ │
│ Signal Queue (sorted by score): │
│ ┌──────────────────────────────────────┐ │
│ │ 1. Strategy C × ETHUSDT score=223 │ │
│ │ 2. Strategy B × BTCUSDT score=142 │ │
│ │ 3. Strategy A × SOLUSDT score=100 │ │
│ │ 4. Strategy C × BTCUSDT score=89 │ │
│ │ 5. Strategy A × ETHUSDT score=76 │ │
│ └──────────────────────────────────────┘ │
│ │
│ Active Slots (max_parallel = 3): │
│ ┌──────────────────────────────────────┐ │
│ │ Slot 1: Strategy C × ETHUSDT [FULL] │ │
│ │ Slot 2: Strategy B × BTCUSDT [FULL] │ │
│ │ Slot 3: Strategy A × SOLUSDT [DUAL] │ │
│ └──────────────────────────────────────┘ │
│ │
│ Conflict Rules: │
│ - One position per pair │
│ - Primary displaces fallback on same pair │
│ - Higher score wins for cross-pair slots │
└─────────────────────────────────────────────┘
スロット管理
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import heapq
import time
class SlotType(Enum):
FULL = "full" # primary strategy, 100% position
DUAL = "dual" # fallback strategy, dual_size position
@dataclass
class Signal:
strategy_id: str
pair: str
direction: str # "long" | "short"
score: float
is_primary: bool # primary or fallback
timestamp: float
@dataclass(order=True)
class Slot:
"""A single orchestrator slot."""
priority: float = field(compare=True) # negative score for min-heap
strategy_id: str = field(compare=False)
pair: str = field(compare=False)
slot_type: SlotType = field(compare=False)
entry_time: float = field(compare=False)
class Orchestrator:
"""
Multi-strategy orchestrator with cascade mode.
Manages N strategies x M pairs within max_parallel_positions slots.
Primary strategies have unconditional priority over fallback.
"""
def __init__(
self,
max_parallel_positions: int = 10,
dual_size: float = 0.068,
min_score: float = 0,
):
self.max_parallel = max_parallel_positions
self.dual_size = dual_size
self.min_score = min_score
self.active_slots: dict[str, Slot] = {} # pair -> Slot
self.pending_signals: list[Signal] = []
def on_signal(self, signal: Signal) -> Optional[dict]:
"""
Process a new signal. Returns an action or None.
Actions:
- {"action": "open", "pair": ..., "size": ..., "slot_type": ...}
- {"action": "replace", "pair": ..., "close_strategy": ..., "open_strategy": ...}
- None (signal rejected)
"""
if signal.score < self.min_score:
return None
pair = signal.pair
if pair in self.active_slots:
existing = self.active_slots[pair]
if signal.is_primary and existing.slot_type == SlotType.DUAL:
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=SlotType.FULL,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": 1.0,
}
if signal.score > -existing.priority:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # existing has higher priority
if len(self.active_slots) < self.max_parallel:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "open",
"pair": pair,
"strategy": signal.strategy_id,
"size": size,
"slot_type": slot_type,
}
worst_pair = min(
self.active_slots,
key=lambda p: -self.active_slots[p].priority,
)
worst_slot = self.active_slots[worst_pair]
if signal.score > -worst_slot.priority:
del self.active_slots[worst_pair]
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": worst_slot.strategy_id,
"close_pair": worst_pair,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # all active slots have higher scores
def on_exit(self, pair: str) -> None:
"""Strategy closed a position."""
if pair in self.active_slots:
del self.active_slots[pair]
def utilization(self) -> float:
"""Current slot utilization."""
return len(self.active_slots) / self.max_parallel
def fill_efficiency_snapshot(self) -> float:
"""Weighted utilization: FULL=1.0, DUAL=dual_size."""
total = sum(
1.0 if s.slot_type == SlotType.FULL else self.dual_size
for s in self.active_slots.values()
)
return total / self.max_parallel
競合解決
3つのレベルの競合があります:
レベル1 — 同一ペア、同一方向。 スコアの高い戦略が勝ちます。両方がプライマリの場合はスコアで決定します。一方がプライマリで他方がフォールバックの場合、プライマリが無条件で勝ちます。
レベル2 — 同一ペア、反対方向。 禁止:同一ペアで同時にロングとショートを持つことはできません。最もスコアの高い戦略が勝ちます。
レベル3 — クロスペア競合。 すべてのスロットが埋まっている場合、新しいシグナルが最低スコアのスロットを退出させます。これは優先キューとして機能します。
カスケードバックテスト:方法論
 共同シミュレーション:プライマリとフォールバックのエクイティカーブにオーバーラップゾーンとカスケード合計結果を表示
共同シミュレーション:プライマリとフォールバックのエクイティカーブにオーバーラップゾーンとカスケード合計結果を表示
なぜPnLを単純合算できないのか
ナイーブなアプローチ:各戦略を個別にバックテストし、PnLを合算する。これは3つの理由で過大な結果を生みます:
-
時間のオーバーラップ。 プライマリとフォールバックが同時にアクティブな場合、フォールバックはトレードすべきではない(またはdual_sizeでトレードする)。単純な合算はこのオーバーラップを無視します。
-
資本制約。 総ポジションは制限されています。5つの戦略が同時にオープンしたいが3スロットしかない場合、2つの戦略はエントリーできません。それらのPnLはカウントできません。
-
取引コスト。 カスケードの切り替え(フォールバックのクローズ、プライマリのオープン)は、個別のバックテストには存在しない追加の手数料を発生させます。
共同シミュレーション
正しいカスケードバックテストは、共有タイムライン上でのすべての戦略の共同シミュレーションです:
import numpy as np
from typing import NamedTuple
class Trade(NamedTuple):
strategy: str
pair: str
entry_time: int # minute index
exit_time: int # minute index
pnl_per_minute: float # log-return per minute
is_primary: bool
score: float
def backtest_cascade(
all_trades: list[Trade],
total_minutes: int,
max_slots: int = 10,
dual_size: float = 0.068,
switch_cost: float = 0.0006, # 0.06% round-trip
) -> dict:
"""
Joint simulation of cascade portfolio.
Walk through each minute, apply orchestrator rules,
calculate PnL accounting for overlap and slot constraints.
"""
entries = {}
exits = {}
active_trades = {} # trade_id -> Trade
for i, trade in enumerate(all_trades):
entries.setdefault(trade.entry_time, []).append((i, trade))
exits.setdefault(trade.exit_time, []).append((i, trade))
active_slots = {} # pair -> (trade_id, SlotType)
equity = np.ones(total_minutes)
switch_costs_total = 0.0
for t in range(1, total_minutes):
for trade_id, trade in exits.get(t, []):
if trade.pair in active_slots:
slot_id, _ = active_slots[trade.pair]
if slot_id == trade_id:
del active_slots[trade.pair]
new_signals = sorted(
entries.get(t, []),
key=lambda x: x[1].score,
reverse=True,
)
for trade_id, trade in new_signals:
pair = trade.pair
if pair in active_slots:
existing_id, existing_type = active_slots[pair]
existing_trade = all_trades[existing_id]
if trade.is_primary and existing_type == SlotType.DUAL:
active_slots[pair] = (trade_id, SlotType.FULL)
switch_costs_total += switch_cost
continue
if trade.score > existing_trade.score:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
switch_costs_total += switch_cost
elif len(active_slots) < max_slots:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
minute_return = 0.0
for pair, (trade_id, slot_type) in active_slots.items():
trade = all_trades[trade_id]
size = 1.0 if slot_type == SlotType.FULL else dual_size
minute_return += trade.pnl_per_minute * size
equity[t] = equity[t - 1] * (1 + minute_return)
peak = np.maximum.accumulate(equity)
max_dd = ((equity - peak) / peak).min()
total_pnl = equity[-1] - 1 - switch_costs_total
return {
"total_pnl": total_pnl,
"max_dd": max_dd,
"switch_costs": switch_costs_total,
"equity_curve": equity,
}
切り替え時の取引コスト
各カスケード切り替え(フォールバック -> プライマリ)には以下が必要です:
- フォールバックポジションのクローズ:テイカー手数料(Binance先物で0.04%)
- プライマリポジションのオープン:テイカー手数料(0.04%)
- スプレッド:約0.01-0.02%
合計切り替えコスト:切り替えあたり約0.06-0.10%。期間中に100回の切り替えがある場合:
これは相当な金額です。頻繁な切り替えを伴うカスケードは、取引コストにより単一戦略よりもパフォーマンスが悪化する可能性があります。
マルチペア拡張:M個のペアでN個の戦略
 N個の戦略がM個のトレーディングペアに接続されたネットワーク — 相関の強さが実効的な分散を決定する
N個の戦略がM個のトレーディングペアに接続されたネットワーク — 相関の強さが実効的な分散を決定する
組み合わせ空間
10ペアで3戦略 = 30個の潜在的シグナル。max_slots = 5の場合、オーケストレーターはスコア上位5つを選択します。これは組み合わせ問題です:各瞬間に通りの可能なポートフォリオ。
実務では、貪欲アルゴリズム(スコアでソートし、上から埋める)がでほぼ最適な結果を生成します。
ペア間の相関
暗号資産ペアは強く相関しています。BTCが下落すればETH、SOL、AVAXも連動して下落します。つまり、5つの異なるペアでの5つのロングポジションは、実質的に「暗号資産市場」への1つの大きなポジションです。
シグナル相関で詳細に分析したように、独立ポジションの実効数は:
ここではペア間の平均相関です。
、の場合:
相関ペアでの5ポジションは、1.3個の独立ポジションに相当します。分散はほぼ存在しません。
カスケードへの実践的な示唆
def effective_diversification(
positions: list[dict], # [{"pair": "BTCUSDT", "direction": "long"}, ...]
correlation_matrix: np.ndarray,
pair_index: dict[str, int],
) -> float:
"""
Calculate effective diversification of open positions.
Returns:
N_eff / N — diversification coefficient (0..1)
"""
n = len(positions)
if n <= 1:
return 1.0
total_corr = 0.0
pairs_count = 0
for i in range(n):
for j in range(i + 1, n):
idx_i = pair_index[positions[i]["pair"]]
idx_j = pair_index[positions[j]["pair"]]
rho = correlation_matrix[idx_i, idx_j]
if positions[i]["direction"] != positions[j]["direction"]:
rho = -rho
total_corr += rho
pairs_count += 1
avg_rho = total_corr / pairs_count if pairs_count > 0 else 0
n_eff = n / (1 + (n - 1) * max(0, avg_rho))
return n_eff / n
オーケストレーターはスロットを埋める際に相関を考慮すべきです。2つの選択肢があります:
- 分散ボーナス:ランキング時に、無相関ペアの戦略のスコアにボーナスを加える。
- 相関キャップ:相関ペアでの同一方向ポジション数を制限する。
カスケード最適化パイプライン
 データ準備からバリデーション、ライブオーケストレーションまでの8つの接続された段階 — 各段階が前段階の上に構築される
データ準備からバリデーション、ライブオーケストレーションまでの8つの接続された段階 — 各段階が前段階の上に構築される
データからプロダクションまでの完全なパイプラインは8段階で構成されます:
ステージ0:データ準備
ヒストリカルデータを読み込み、マルチタイムフレームアクセス用のParquetキャッシュを構築します。効率的なキャッシングがなければ、後続のステージは受け入れがたいほど遅くなります。
ステージ1:TF + Length(Hill-Climbingグリッド)
ベースタイムフレームとインジケーターのウィンドウ長を選択します。粗いグリッド:TFは{1m, 5m, 15m, 1h, 4h}、Lengthは{10, 20, 50, 100, 200}。最良のグリッドポイントからHill-Climbing。
ステージ2:Separation(座標降下法、12パラメータ)
Separationパラメータ(エントリー/イグジット)を最適化します。12パラメータに対する座標降下法 — インジケーターの閾値、フィルター、ストップロス、テイクプロフィット。高次元の決定論的目的関数に対しては、座標降下法の方がOptunaよりコスト効率が良いです。
ステージ3:メタパラメータ(座標降下法)
メタパラメータ:最大保有時間、イグジット用の最小PnL、トレーリングストップの設定。再び座標降下法。プラトー分析でロバスト性を確認 — 最適値が点状であれば、戦略は過剰最適化されています。
ステージ4:コンボ最適化
ペア(プライマリ、フォールバック)に対するグリッドサーチ。各組み合わせについて:dual_sizeを選択し、共同シミュレーションでカスケードPnLを計算します。
ステージ5:バリデーション
多層バリデーション:
- マルチシンボル:最適化ペアだけでなく10以上のペアで戦略をテスト
- ウォークフォワード:スライディングIS/OOSウィンドウ
- パラメータ安定性:各ステージでのプラトー分析
- モンテカルロ・ブートストラップ:カスケードPnLの信頼区間
- バックテスト-ライブパリティ:バックテストとペーパートレーディングの比較
ステージ6:ランキングと選択
カスケードの組み合わせをスコアでランキングします。上位K個の組み合わせがステージ7に進みます。スコアは信頼度調整、ファンディングコスト、fill_efficiencyを考慮します。
ステージ7:オーケストレーション
最終ステージ:個の戦略と個のペアでカスケードモードのオーケストレーターを起動します。スロット管理、優先キュー、競合解決 — 上記のすべてがここに集約されます。
パフォーマンス分析:カスケード対個別
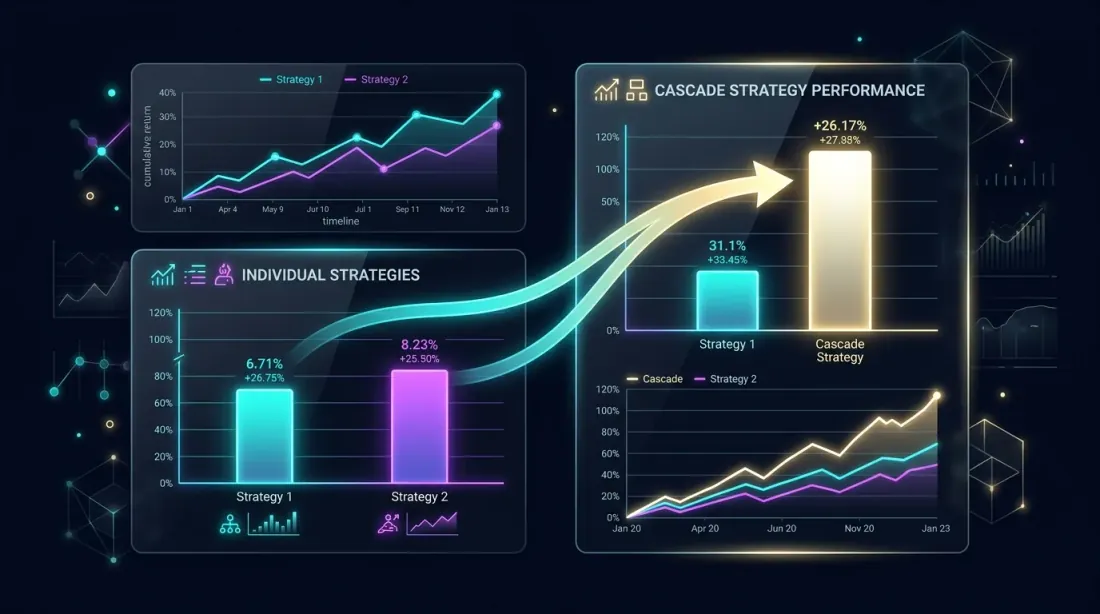 並列比較:カスケードポートフォリオが遊休時間の活用により個別戦略を上回る
並列比較:カスケードポートフォリオが遊休時間の活用により個別戦略を上回る
カスケードの理論的優位性
プライマリがの時間トレードし、PnL/日 = 0.49%と仮定します。フォールバックはでPnL/日 = 0.89%。オーバーラップ = (独立性を仮定)。
プライマリ単独(戦略A):
カスケード(Aプライマリ + Cフォールバック):
カスケードの効果:フォールバックからPnLが+31%増加し、ドローダウンの増加は最小限(MaxDDにが追加)。
カスケードが効果的でない場合
カスケードが効果的でないのは以下の場合です:
- プライマリのアクティブ時間が80%超。 遊休時間が少なく、フォールバックの入る余地がない。
- 戦略の相関が高い。 プライマリとフォールバックが同時にシグナルを生成 — オーバーラップが高く、フォールバックはプライマリも待機中の時に正確に待機する。
- 切り替えコストがフォールバックPnLを超える。 頻繁な切り替えの場合、カスケードの手数料がフォールバックの利益を食う。
- dual_sizeが小さすぎる。 では、フォールバックはポテンシャルの1%しか稼がない — 手数料以下。
比較表
| 構成 | 年間PnL | MaxDD | シャープ | 切り替えコスト |
|---|---|---|---|---|
| 戦略A単独 | 26.8% | 0.9% | 1.42 | 0 |
| 戦略C単独 | 146.1% | 17% | 1.15 | 0 |
| カスケードA+C (d=0.068) | 35.2% | 2.06% | 1.58 | 約1.2% |
| カスケードB+A (d=0.068) | 19.4% | 1.36% | 1.71 | 約0.3% |
| 3戦略オーケストレーター | 48.7% | 3.1% | 1.63 | 約2.1% |
カスケードA+C:プライマリAがフォールバックCから+8.4%を獲得。遊休時間の活用によりシャープが上昇。MaxDDは穏やかに増加()。
オーケストレーション:実践におけるfill_efficiency
 Fill efficiencyが約78%:ヒートマップが戦略とペア間の時間利用率を表示し、明るいセルがアクティブなトレーディングを示す
Fill efficiencyが約78%:ヒートマップが戦略とペア間の時間利用率を表示し、明るいセルがアクティブなトレーディングを示す
fill_efficiencyパラメータは、オーケストレーターが実際に遊休時間のどの程度を活用しているかを決定します。アクティブ時間あたりのPnLで示したように、3つの方法で推定できます:
- 固定定数(0.80) — 粗いが汎用的
- 解析的推定 による — 相関を考慮
- データからのシミュレーション — 最も正確
3戦略10ペアのカスケードの場合:
def cascade_fill_efficiency(
strategies: list[dict], # [{"trading_time": 0.15, "is_primary": True}, ...]
n_pairs: int = 10,
correlation_factor: float = 3.0,
) -> float:
"""Estimate fill_efficiency for a cascade portfolio."""
n_eff = n_pairs / correlation_factor
primary_times = [s["trading_time"] for s in strategies if s["is_primary"]]
p_primary = 1 - np.prod([(1 - t) ** n_eff for t in primary_times])
fallback_times = [s["trading_time"] for s in strategies if not s["is_primary"]]
p_fallback = 1 - np.prod([(1 - t) ** n_eff for t in fallback_times])
fill = p_primary + (1 - p_primary) * p_fallback
return min(fill, 1.0)
strategies = [
{"trading_time": 0.05, "is_primary": True}, # Strategy B
{"trading_time": 0.15, "is_primary": True}, # Strategy A
{"trading_time": 0.45, "is_primary": False}, # Strategy C as fallback
]
eff = cascade_fill_efficiency(strategies, n_pairs=10, correlation_factor=3.0)
実践的な推奨事項
 カスケード展開のための6つの重要な推奨事項 — 小規模な開始から適応的再校正まで
カスケード展開のための6つの重要な推奨事項 — 小規模な開始から適応的再校正まで
1. 2つの戦略から始める
いきなり20ペアで10戦略を起動しないでください。1つのプライマリ+1つのフォールバックを3-5ペアで開始します。共同シミュレーションが実際の動作と一致することを確認してください。バックテスト-ライブパリティは重要です:カスケードバックテストがライブと5-10%でも乖離すれば、オーケストレーターのロジックにエラーがあります。
2. dual_sizeはグリッドサーチで、直感ではなく
最適なdual_sizeは戦略の具体的なペアに依存します。6.8%はガイドラインであり、普遍的な定数ではありません。1%から30%まで0.5%刻みでグリッドサーチを実行し、シャープの最大値を選択してください。
3. スロット制限がアーキテクチャを決定する
max_slots = 1の場合、カスケードは単純な戦略切り替えに退化します。max_slots = 50の場合、制約はバインディングではなく、問題は独立したポートフォリオに帰着します。興味深いゾーン:max_slots = 3-10、スロット管理が結果に真に影響を与える範囲です。
4. レイテンシを考慮する
ライブトレーディングでは、カスケードの切り替えは瞬時ではありません。フォールバックポジションのクローズ+プライマリのオープン = 2つのAPIコール+ネットワークレイテンシ+取引所のマッチング。ボラティリティの高い市場では、200-500msで価格が動く可能性があります。スリッページバジェットを組み込んでください。
5. fill_efficiencyを監視する
プロダクションでのリアルなfill_efficiencyを追跡してください。バックテストよりも大幅に低い場合、オーケストレーターが期待通りに遊休時間を活用していません。原因:APIの遅延、注文の拒否、マージン制約。
6. 適応的最適化を使用する
カスケードパラメータ(dual_size、スコアの重み、スロット制限)は静的であるべきではありません。新しいデータでの定期的な再校正に適応的ドリルダウンを使用してください。市場は変化します — カスケードパラメータも追従すべきです。
「幻想なきバックテスト」シリーズ:まとめ
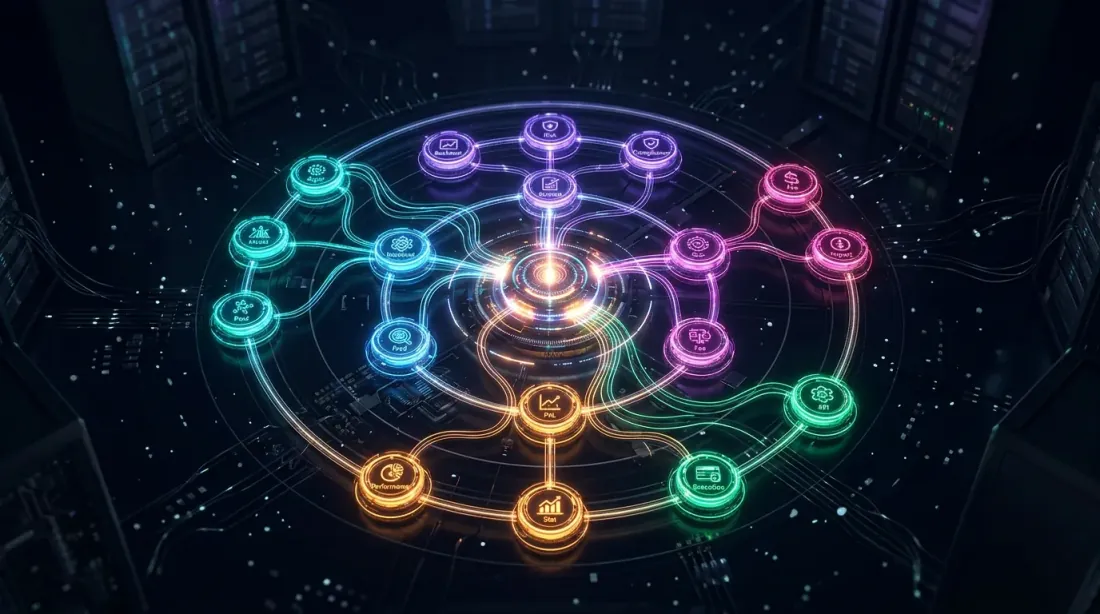 完全なシステムアーキテクチャ:数学からバリデーション、ライブオーケストレーションまでの13の相互接続されたモジュール
完全なシステムアーキテクチャ:数学からバリデーション、ライブオーケストレーションまでの13の相互接続されたモジュール
この記事は13以上の記事からなるシリーズの完結編です。各記事は、バックテストからプロダクションへの道のりにおける1つの具体的な問題に取り組みました。それらがどのように接続されているかを示します:
基盤:リターンの数学
損失-利益の非対称性 — リターンの乗法的性質、ボラティリティドラグ、ケリー基準。これは以降すべての数学的基盤です:なぜMaxDDがレバレッジを決定するのか、なぜシャープが生のPnLより重要なのか、なぜ対称的なR:Rでの50%勝率は不採算なのか。
バリデーション:信頼区間とロバスト性
モンテカルロ・ブートストラップ — 単一点推定を信頼区間付きの分布に変換。あらゆる指標(PnL、MaxDD、シャープ)は信頼区間があって初めて意味を持ちます。
ウォークフォワード最適化 — アウトオブサンプルのバリデーション。ヒストリカルデータでのバックテストはIS結果です。WFOは新しいデータで戦略がどのように機能するかを示します。
プラトー分析 — パラメータのロバスト性チェック。最適値が点状であれば、戦略は過剰最適化されています。
バックテスト-ライブパリティ — バックテストと実際の結果の比較。スケーリング前の最終チェック。
現実的なコスト:ファンディングとレバレッジ
ファンディングレートがレバレッジを殺す — 無期限先物でのレバレッジの隠れたコスト。ファンディングを考慮しなければ、美しいバックテストは損失に変わります。
ファンディングレート・アービトラージ — クロスエクスチェンジ戦略により、ファンディングを費用から収益源に変える方法。
指標とランキング
アクティブ時間あたりのPnL — ポートフォリオ内の戦略ランキング指標。生のPnLはスケールしません。PnL/アクティブ日はスケールします。
シグナル相関 — 相関ペアのポートフォリオにおける実効的な分散。
インフラストラクチャと最適化
マルチタイムフレームバックテスト用Parquetキャッシュ — 高速イテレーションのためのデータインフラストラクチャ。
適応的ドリルダウン — 適応的最適化:粗いグリッド -> 有望なゾーンでの微調整。
Optuna対座標降下法 — オプティマイザーの選択:ノイジーな目的関数の低次元にはOptuna、スムーズな目的関数の高次元には座標降下法。
Polars対Pandas — バックテスティングにおけるDataFrame操作のパフォーマンス。
オーケストレーション(本記事)
カスケード戦略 — 前述のすべてのコンポーネントを動作するシステムに統合。スコアベースのアロケーションはPnL/アクティブ時間、信頼度調整、ファンディングコストを使用。カスケードモードが遊休時間を埋める。共同シミュレーションがポートフォリオをバリデート。モンテカルロ・ブートストラップがカスケードPnLの信頼区間を提供。
各記事は独立したモジュールです。それらが合わさって、データ読み込みから戦略ポートフォリオのライブオーケストレーションまでの完全なパイプラインを形成します。
結論
カスケードは戦略ポートフォリオへの唯一のアプローチではありません。しかし、最もシンプルかつ実践的なアプローチの1つです:プライマリ戦略がフルキャパシティでトレードし、フォールバックが縮小ポジションで遊休時間を埋めます。2つの主要パラメータ(dual_sizeとmax_slots)がほとんどの構成に十分な柔軟性を提供します。
3つの要点:
-
カスケードは共同シミュレーションのみでバックテストすべきです。 個別PnLの合算は結果を過大評価します。切り替えコスト、オーバーラップ、スロット制約 — これらすべては共同シミュレーションでのみ捕捉されます。
-
dual_sizeがPnL対ドローダウンのトレードオフを決定します。 典型的な最適値は5-10%。シャープに基づくグリッドサーチが信頼性の高い選択方法です。
-
オーケストレーターはスコアベースの優先キューです。 すべては各シグナルの単一の数値(スコア)に帰着します。スコア = f(PnL/アクティブ日, MaxLev, 信頼度, ファンディング)。最高スコアの戦略がスロットを獲得します。残りは待機します。
「幻想なきバックテスト」シリーズは一つのことを実証しています:美しいバックテストと実際の利益の間には、数十の落とし穴があります。各記事がその1つを除去します。カスケードオーケストレーションは最後のステップです:バリデート済みの戦略セットを動作するポートフォリオに変えること。
参考リンク
- López de Prado — Advances in Financial Machine Learning: Portfolio Construction
- Pardo, R. — The Evaluation and Optimization of Trading Strategies
- Ernest Chan — Algorithmic Trading: Winning Strategies and Their Rationale
- Perry Kaufman — Trading Systems and Methods, Chapter on Portfolio Allocation
- Tomasini, Jaekle — Trading Systems: A New Approach to System Development and Portfolio Optimisation
- Bailey, D.H. & López de Prado — The Deflated Sharpe Ratio
- Markowitz, H. — Portfolio Selection (1952)
- Kelly, J.L. — A New Interpretation of Information Rate (1956)
Citation
@article{soloviov2026cascadestrategies,
author = {Soloviov, Eugen},
title = {Cascade Strategies: Priority Execution with Fallback Filling},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/cascade-strategies-orchestration},
version = {0.1.0},
description = {Finale of the "Backtests Without Illusions" series. How to build an orchestrator from N strategies x M pairs, implement cascade mode with priority and fallback filling, choose dual\_size, and why strategy portfolios cannot be backtested by summing PnL.}
}
MarketMaker.cc Team
クオンツ・リサーチ&戦略