Di Dalam Algoritma Dalaman Kami: HRP + Long/Short + CVaR dengan Hull-White
Dalam ulasan kami «12 Algoritma Pengoptimuman Portfolio, Dibandingkan» kami menguji selusin kaedah peruntukan secara serentak. Sebelas daripadanya adalah klasik buku teks. Yang kedua belas, Pipeline, adalah milik kami — dan ia hanya mendapat satu poin ringkas dalam artikel tersebut. Artikel ini adalah penelitian mendalam: apa yang ada di dalamnya, dari mana setiap formula berasal, dan bagaimana spesifikasi bertukar menjadi Rust.
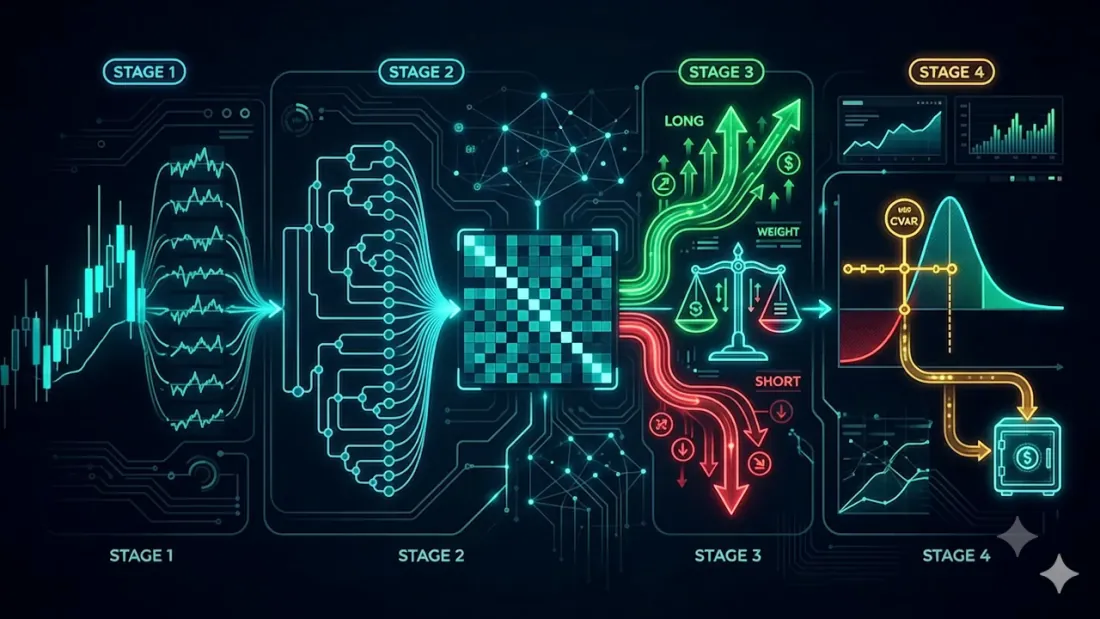
Pipeline tidak mencipta cara baharu untuk mengira wajaran. Ia mengambil resipi paling kukuh yang diketahui — Hierarchical Risk Parity (HRP) — dan membungkusnya dalam dua lapisan yang sebenarnya diperlukan oleh akaun dagangan langsung tetapi HRP biasa tidak mempunyainya: arah (long/short daripada isyarat strategi) dan had belanjawan risiko yang keras (CVaR diselaraskan untuk rejim volatiliti semasa). Ini menghasilkan empat peringkat.
Empat peringkat
- I — pulangan log setiap aset.
- II — wajaran asas daripada HRP.
- III — pembahagian long/short daripada isyarat agen, dengan bahagian risiko ditetapkan mengikut keyakinan.
- IV — pembetulan CVaR dengan volatiliti Hull-White; lebihan risiko dipindahkan ke tunai.
Mari kita lalui satu persatu mengikut urutan.
Peringkat I. Pulangan log
Segalanya bermula dengan peralihan daripada harga kepada pulangan log:
di mana ialah aset dan ialah langkah masa. Pulangan log terkumpul dari masa ke masa dan lebih simetri berbanding perubahan peratusan biasa — input standard untuk sebarang matematik kovarian.
Peringkat II. HRP sebagai asas
HRP, yang dicadangkan oleh Marcos López de Prado pada tahun 2016, mengelakkan penyakit utama Mean-Variance Optimization — pembalikan matriks kovarian yang bersyarat buruk. Ia tidak pernah membalikkannya langsung. Sebaliknya, ia bekerja dengan struktur korelasi.
Kovarian dan korelasi
Daripada pulangan, kami membina matriks kovarian dan menormalisasikannya kepada matriks korelasi :
Matriks jarak
Kami menukar korelasi kepada metrik jarak, supaya aset yang berkorelasi kuat berada "berdekatan":
Semakin dekat kepada 1, semakin dekat kepada 0 — dan semakin besar kemungkinan aset tersebut berkongsi kluster.
Dendrogram dan tertib daun
Daripada matriks jarak, kami membina hierarki kluster melalui average linkage dan membaca tertib daun — satu permutasi aset di mana aset yang serupa berada bersebelahan.
Langkah pilihan: bilangan kluster yang optimum boleh dipilih melalui pekali silhouette , di mana ialah jarak min dalam kluster dan ialah jarak min ke kluster jiran terdekat. Laluan asas tidak memerlukannya — biseksi rekursif sudah menghormati hierarki.
Kuasi-pepenjuruan
Kami menukar baris dan lajur mengikut , mengumpulkan nilai besar sepanjang pepenjuru:
Biseksi rekursif
Kemudian rekursi berjalan dari atas ke bawah. Pada setiap langkah, sebuah kluster dibahagi dua kepada dan , dan modal diagihkan antara kedua-dua bahagian secara songsang berkadar dengan varians mereka:
Varians kluster dikira pada sub-blok kovariannya sebagai . Penurunan diteruskan sehingga setiap nod memegang satu aset sahaja. Wajaran adalah long-only, tidak negatif, dan berjumlah 1.0.
Dalam implementasi kami, ini adalah fungsi hrp_from_cov(cov) -> Vec<f64>: korelasi → jarak → average linkage → tertib daun → kuasi-pepenjuruan → biseksi rekursif. Pipeline memanggilnya sebagai asas — dan ia juga merupakan optimize() awam untuk kes tanpa isyarat.
Peringkat III. Lapisan long/short
HRP biasa adalah portfolio "beli sahaja". Namun, strategi sering mengatakan bukan sahaja berapa banyak tetapi ke arah mana. Peringkat III mengambil isyarat per-aset (Long/Short) daripada agen dan membina dua sub-portfolio.
- Aset dibahagikan kepada bakul long dan short mengikut isyarat.
- Di dalam setiap bakul, wajaran dikira dengan HRP yang sama (pada sub-blok kovarian aset tersebut), berjumlah 1 per bakul.
- Jika agen juga mengeluarkan keyakinan , bahagian risiko antara kedua-dua pihak ditetapkan oleh jumlah keyakinan:
Tanpa keyakinan, bahagian akan kembali kepada bilangan aset dalam setiap bakul. Wajaran bertanda akhir ialah untuk long dan untuk short, selepas itu keseluruhan pendedahan kasar dinormalisasi kepada 1.
Nota jujur tentang kod. Spesifikasi asal membawa faktor pembetulan , — tetapi ia juga menandakannya dengan "adakah kita perlukan langkah ini?". Implementasi tidak menerapkannya: kedua-dua pihak digabungkan secara langsung melalui bahagian risiko , yang mengekalkan pendedahan kasar tepat pada 1 dan tidak mewujudkan leverage tersembunyi. Ini adalah penyederhanaan spesifikasi yang disengajakan, bukan kesilapan.
Peringkat IV. CVaR dengan pelarasan Hull-White
HRP mengimbangi risiko secara struktur, tetapi tidak mengetahui apa-apa tentang tahap risiko mutlak dalam nilai wang. Peringkat akhir meletakkan had keras pada risiko ekor — dan menjadikannya sensitif terhadap perubahan rejim pasaran.
Pulangan portfolio dan volatiliti EWMA
Pertama, kami menggabungkan wajaran kepada pulangan portfolio dan menganggar volatiliti bersyarat dengan EWMA:
dengan (nilai RiskMetrics klasik). EWMA memberikan volatiliti "hari ini" dan bukannya purata sepanjang sejarah.
Penskalaan semula Hull-White
Idea utama: pulangan lalu tidak boleh diambil apa adanya — ia berlaku di bawah volatiliti yang berbeza. Kaedah Hull-White menskala semula setiap pulangan lalu kepada tahap semasa:
Bulan yang tenang "diregangkan", bulan yang bergolak "dimampatkan", dan taburan dibawa ke dalam rejim semasa.
VaR dan CVaR
Pada taburan yang diskala semula, kami mengambil kuantil kerugian dan purata kerugian dalam ekor:
CVaR (juga dikenali sebagai Expected Shortfall) menjawab bukan "seberapa buruk hari buruk yang biasa" tetapi "seberapa buruk ia secara purata merentasi peratus terburuk" — jadi ia melihat ketebalan ekor, bukan sekadar tepinya.
Belanjawan risiko dan tunai
Jika CVaR melebihi ambang yang boleh diterima, setiap kedudukan berisiko dikecilkan oleh satu faktor tunggal, dan modal yang dibebaskan dipindahkan ke tunai:
Jadi portfolio menyahrisiko dirinya sendiri apabila risiko ekor meningkat dan memasuki semula pasaran apabila ia tenang.
Daripada spesifikasi kepada kod
Keseluruhan algoritma berada dalam satu crate Rust, portfolio-pipeline, dan mematuhi kontrak seragam workspace:
pub fn optimize(prices: &[Vec<f64>]) -> Vec<f64>
Ini adalah unjuran long-only (peringkat I, II, IV tanpa isyarat) — antara muka prices -> weights yang sama persis seperti sebelas algoritma lain, jadi Pipeline adalah pengganti langsung untuk mana-mana daripadanya. Versi penuh dengan setiap peringkat adalah fungsi berasingan:
pub fn run(
prices: &[Vec<f64>],
signals: Option<&[Side]>, // Long / Short per asset
confidence: Option<&[f64]>, // agent confidence → risk shares λ
cfg: &PipelineConfig, // CVaR / Hull-White parameters
) -> PipelineResult // signed weights + cash + cvar + σ
Lalai lapisan: ekor cvar_alpha = 0.05, belanjawan cvar_max = 0.05, EWMA ewma_lambda = 0.94, tetingkap Hull-White hw_window = 0 (semua sejarah). Implementasi tidak mempunyai kebergantungan luaran dan sengaja bersifat defensif: pada sejarah pendek (kurang daripada 4 titik harga) ia mengembalikan wajaran sama rata, dan lapisan CVaR hanya diaktifkan pada ≥8 pemerhatian pulangan — jika tidak, tidak ada apa-apa untuk menganggar ekor.
Mengapa Rust: satu pangkalan kod deterministik untuk kedua-dua backtest dan pengeluaran, tanpa penyimpangan "Python dalam penyelidikan, sesuatu yang lain dalam prod", dan cukup pantas untuk menjalankan semua dua belas algoritma dalam satu permintaan melalui backend perbandingan.
Kos dari segi masa
Seberapa pantas "cukup pantas"? Kami mengekstrak teras HRP (pulangan log → kovarian → average linkage → kuasi-pepenjuruan → wajaran rekursif) ke dalam penanda aras berdiri sendiri dan menjalankan matematik yang sama persis merentasi tujuh bahasa — C, C++, Rust, Zig, Python, Node.js dan Bun — di bawah syarat yang sama: Apple Silicon, satu thread, 365 pemerhatian harian per aset, harga sintetik, bilangan aset dari 10 hingga 10,000.
Satu kata tentang kerumitan, kerana ia menentukan keseluruhan bentuk. Versi buku teks average linkage mengimbas semula matriks jarak penuh untuk pasangan terdekat pada setiap gabungan — itu ialah dan menjadi kesesakan pada beberapa ribu aset. Penanda aras sebaliknya menggunakan algoritma rantai jiran terdekat (Müllner 2011) — yang sama di sebalik linkage(method='average') SciPy. Dengan itu, pengklusteran bukan lagi peringkat dominan: pada ia adalah ~15 ms daripada laluan ~0.5 s. Kos kini didominasi oleh matriks kovarian, — peringkat tunggal yang tidak dapat dielakkan oleh mana-mana kaedah bergaya HRP.
Apa yang ditunjukkan oleh larian (jadual per-bahasa penuh dan skrip reproduksi satu arahan terdapat dalam repositori projek):
- Pada portfolio yang realistik, ia percuma. Bakul kripto mengandungi berpuluh-puluh aset, jarang melebihi seratus. Pada , satu laluan HRP penuh adalah milisaat satu digit walaupun dalam Node dan mikrosaat dalam Rust/C. Pengiraan semula wajaran pada setiap detik bukan isu.
- Rust berada dalam ~1.0–1.3× daripada C — order magnitud yang sama, kedua-duanya dikompil, dan pada dasarnya setara apabila mencapai ribuan. C sedikit lebih pantas pada aritmetik mentah, tetapi Rust memberikan kebolehramalan yang sama tanpa pengumpul sampah dan tanpa UB.
- Ia berskala hingga ribuan aset. Dengan linkage , satu laluan penuh adalah ~0.5 s pada dan beberapa saat pada dalam bahasa yang dikompil; malah Node yang ditafsirkan melangkaui dalam bawah dua saat. Apa yang menetapkan siling sekarang ialah peringkat kovarian, bukan pengklusteran.
Pengambilan pragmatik: pada saiz portfolio kami, memilih Rust bukan tentang "mengalahkan C" (C sedikit lebih pantas di sini) — ia tentang satu pangkalan kod deterministik untuk penyelidikan dan pengeluaran, tanpa jeda GC dan bertahun-tahun ruang kepala prestasi. Penanda aras tujuh bahasa penuh, dengan keputusan dan skrip reproduksi, terbuka dalam repositori projek.
Kedudukan Pipeline di antara dua belas
Dalam perbandingan kami pada satu bakul (yang sengaja disediakan), Pipeline berkelakuan seperti HRP — kerana melalui titik masuk long-only optimize() ia adalah HRP dengan lapisan CVaR. Mesin arahnya hanya hidup apabila anda memberinya isyarat strategi. Itulah keseluruhan intipatinya: Pipeline bukan "pengoptimum lain untuk wajaran backtesting" tetapi lapisan pelaksanaan antara isyarat strategi dan pesanan sebenar — ia mengambil panggilan beli/jual anda, mengatur modal mengikut HRP dalam setiap pihak, mengimbangi pihak-pihak mengikut keyakinan, dan memotong risiko ekor kepada belanjawan yang ditetapkan.
Untuk konteks penuh — sebelas kaedah lain yang ada dan bagaimana ia berbeza — lihat ulasan, «12 Algoritma Pengoptimuman Portfolio, Dibandingkan». Dan anda boleh mencubanya secara langsung di portfolio-optimizer.marketmaker.cc.
Rujukan
- López de Prado, M. (2016). Building Diversified Portfolios that Outperform Out of Sample. The Journal of Portfolio Management.
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
- Hull, J., & White, A. (1998). Incorporating Volatility Updating into the Historical Simulation Method for Value at Risk. Journal of Risk.
- Rockafellar, R. T., & Uryasev, S. (2000). Optimization of Conditional Value-at-Risk. Journal of Risk.
- RiskMetrics Group (1996). RiskMetrics — Technical Document. J.P. Morgan.
- Marketmaker.cc: marketmaker.cc
Petikan
@article{soloviov2026pipeline,
author = {Soloviov, Eugen and Zhuravleva, Marina and Kiselev, Kirill},
title = {Inside Our House Algorithm: HRP + Long/Short + CVaR with Hull-White Adjustment},
year = {2026},
url = {https://marketmaker.cc/ms/blog/post/portfolio-pipeline-hrp-cvar},
description = {A deep dive into Pipeline, a composite portfolio allocation algorithm built on Hierarchical Risk Parity with a signal-driven long/short overlay and a Hull-White CVaR risk-budget correction, with the full specification and its Rust implementation.}
}
Pengarang

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3C%2Fsvg%3E)
Financial mathematics
Fifth-year student at Bauman Moscow State Technical University (Automatic Control Systems), specializing in financial mathematics. Background in calibrating stochastic-volatility (Heston) and local-volatility (Dupire) models, fair pricing of options including exotics via both Monte-Carlo and analytic formulas, hedging-error reduction, and exposure to LSV models.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3C%2Fsvg%3E)
Portfolio optimization
Fourth-year student at the Faculty of Mechanics and Mathematics, Novosibirsk State University (NSU); thesis on Heston-model calibration and delta-hedging within the same model. Works on portfolio optimization.
Baca Lagi

12 Algoritma Pengoptimuman Portfolio Dibandingkan: HRP, Black-Litterman, NCO dan Lebih

Teori Portfolio Markowitz untuk Kripto: Dari Nol hingga Mahir