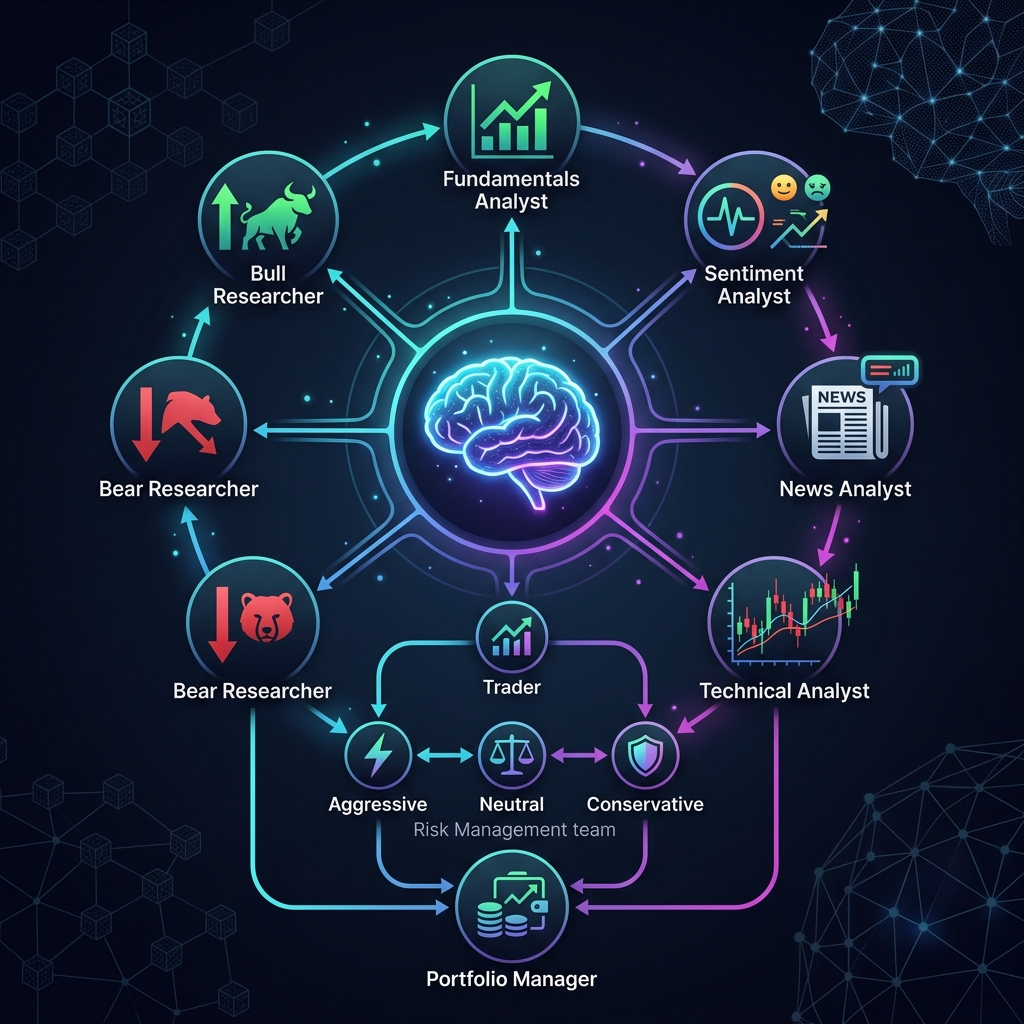
Nel Nostro Algoritmo di Casa: HRP + Long/Short + CVaR con Hull-White
Nella nostra panoramica «12 Algoritmi di Ottimizzazione del Portafoglio a Confronto» abbiamo confrontato fianco a fianco una dozzina di metodi di allocazione. Undici di essi sono classici dei libri di testo. Il dodicesimo, Pipeline, è il nostro — e in quell'articolo ha ricevuto esattamente un punto elenco. Questo articolo è l'analisi approfondita: cosa c'è dentro, da dove proviene ogni formula e come la specifica si trasforma in Rust.
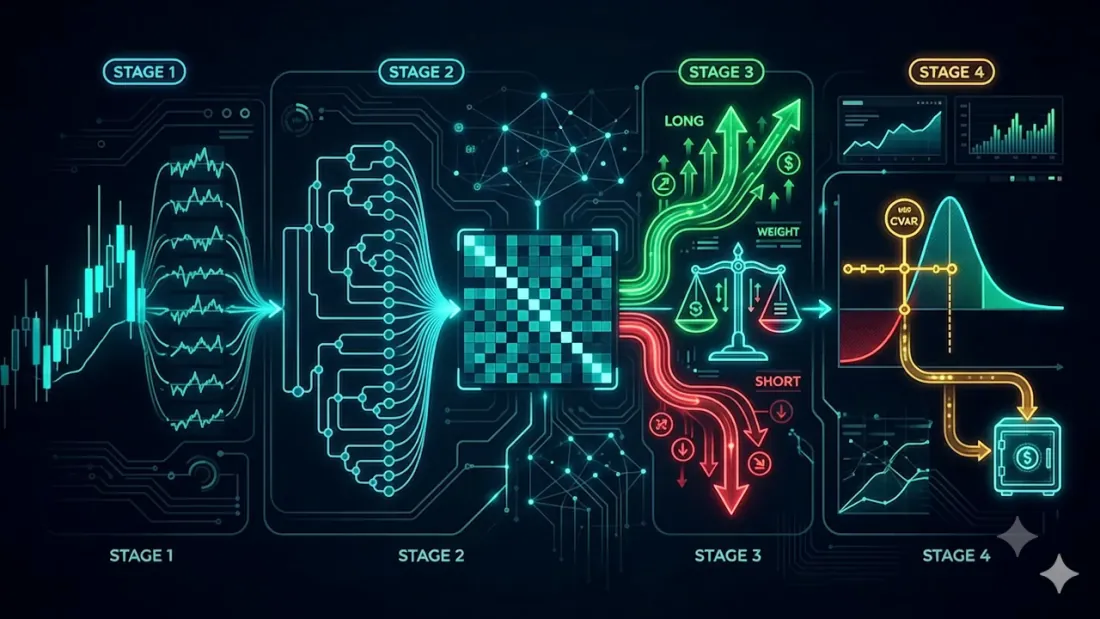
Pipeline non inventa un nuovo modo per calcolare i pesi. Prende la ricetta più robusta conosciuta — Hierarchical Risk Parity (HRP) — e la avvolge nei due livelli che un conto di trading live richiede effettivamente ma di cui l'HRP puro è privo: la direzione (long/short dai segnali di strategia) e un budget di rischio rigido (CVaR corretto per il regime di volatilità corrente). Ciò porta a quattro fasi.
Le quattro fasi
- I — rendimenti logaritmici di ogni asset.
- II — pesi base da HRP.
- III — una suddivisione long/short dai segnali degli agenti, con quote di rischio determinate dalla confidenza.
- IV — una correzione CVaR con volatilità Hull-White; il rischio in eccesso va alla liquidità.
Percorriamoli in ordine.
Fase I. Rendimenti logaritmici
Tutto inizia con il passaggio dai prezzi ai rendimenti logaritmici:
dove è l'asset e il passo temporale. I rendimenti logaritmici si sommano nel tempo e sono più simmetrici delle semplici variazioni percentuali — l'input standard per qualsiasi calcolo di covarianza.
Fase II. HRP come fondamento
HRP, proposto da Marcos López de Prado nel 2016, aggira la malattia centrale dell'Ottimizzazione Media-Varianza — invertire una matrice di covarianza mal condizionata. Non la inverte affatto. Lavora invece con la struttura delle correlazioni.
Covarianza e correlazione
Dai rendimenti costruiamo la matrice di covarianza e la normalizziamo nella matrice di correlazione :
Matrice delle distanze
Trasformiamo la correlazione in una metrica di distanza, in modo che gli asset fortemente correlati si trovino "vicini":
Più si avvicina a 1, più si avvicina a 0 — e più è probabile che gli asset condividano un cluster.
Dendrogramma e ordine delle foglie
Dalla matrice delle distanze costruiamo una gerarchia di cluster tramite average linkage e ricaviamo l'ordine delle foglie — una permutazione degli asset in cui quelli simili sono adiacenti.
Passo opzionale: il numero ottimale di cluster può essere scelto tramite il coefficiente di silhouette , dove è la distanza media all'interno di un cluster e la distanza media verso il cluster vicino più prossimo. Il passaggio base non ne ha bisogno — la bisezione ricorsiva rispetta già la gerarchia.
Quasi-diagonalizzazione
Permutiamo le righe e le colonne di secondo , raccogliendo i valori grandi lungo la diagonale:
Bisezione ricorsiva
Poi la ricorsione procede dall'alto verso il basso. Ad ogni passo un cluster viene diviso a metà in e , e il capitale viene allocato tra le due metà inversamente proporzionale alle loro varianze:
La varianza di un cluster è calcolata sul suo sotto-blocco di covarianza come . La discesa continua finché ogni nodo contiene un singolo asset. I pesi sono solo long, non negativi e sommano a 1.0.
Nella nostra implementazione questa è la funzione hrp_from_cov(cov) -> Vec<f64>: correlazione → distanza → average linkage → ordine delle foglie → quasi-diagonalizzazione → bisezione ricorsiva. Pipeline la chiama come base — ed è anche la funzione pubblica optimize() per il caso senza segnali.
Fase III. L'overlay long/short
L'HRP puro è un portafoglio "solo acquisto". Ma una strategia spesso dice non solo quanto ma in quale direzione. La Fase III prende i segnali per asset (Long/Short) dall'agente e costruisce due sotto-portafogli.
- Gli asset vengono suddivisi in panieri long e short in base al segnale.
- All'interno di ciascun paniere, i pesi vengono calcolati con lo stesso HRP (sul sotto-blocco di covarianza di quegli asset), sommando a 1 per paniere.
- Se l'agente emette anche una confidenza , le quote di rischio tra i lati sono determinate dalla confidenza totale:
Senza confidenza, le quote tornano al conteggio degli asset in ciascun paniere. Il peso con segno finale è per i long e per i short, dopodiché l'intera esposizione lorda viene normalizzata a 1.
Una nota onesta sul codice. La specifica originale prevede fattori di correzione , — ma li contrassegna anche con un "abbiamo davvero bisogno di questo passaggio?". L'implementazione non li applica: i due lati vengono combinati direttamente dalle quote di rischio , il che mantiene l'esposizione lorda esattamente a 1 e non crea leva nascosta. Si tratta di una semplificazione deliberata della specifica, non di una svista.
Fase IV. CVaR con un aggiustamento Hull-White
HRP bilancia il rischio strutturalmente, ma non sa nulla del livello assoluto di rischio in termini monetari. La fase finale pone un tetto rigido al rischio di coda — e lo rende sensibile a un cambiamento del regime di mercato.
Rendimento del portafoglio e volatilità EWMA
Prima collassiamo i pesi in un rendimento di portafoglio e stimiamo la volatilità condizionale con EWMA:
con (il classico valore RiskMetrics). EWMA fornisce la volatilità "di oggi" anziché una media sull'intera storia.
Riscalatura Hull-White
L'idea chiave: i rendimenti passati non possono essere presi così come sono — sono avvenuti in una diversa volatilità. Il metodo Hull-White riscala ogni rendimento passato al livello corrente:
Un mese calmo viene "allungato", uno turbolento "compresso", e la distribuzione viene portata nel regime corrente.
VaR e CVaR
Sulla distribuzione riscalata prendiamo il quantile di perdita e la perdita media nella coda:
CVaR (alias Expected Shortfall) risponde non a "quanto è brutto un giorno tipicamente brutto" ma "quanto è brutto in media attraverso il peggiore percento" — quindi vede lo spessore della coda, non solo il suo bordo.
Budget di rischio e liquidità
Se CVaR supera la soglia accettabile, ogni posizione rischiosa viene ridotta di un singolo fattore, e il capitale liberato si sposta in liquidità:
Così il portafoglio si de-rischia quando il rischio di coda cresce e rientra nel mercato quando si calma.
Dalla specifica al codice
L'intero algoritmo risiede in un singolo crate Rust, portfolio-pipeline, e rispetta il contratto uniforme del workspace:
pub fn optimize(prices: &[Vec<f64>]) -> Vec<f64>
Questa è la proiezione solo-long (fasi I, II, IV senza segnali) — esattamente la stessa interfaccia prezzi -> pesi degli altri undici algoritmi, quindi Pipeline è un sostituto diretto per ciascuno di essi. La versione completa con ogni fase è una funzione separata:
pub fn run(
prices: &[Vec<f64>],
signals: Option<&[Side]>, // Long / Short per asset
confidence: Option<&[f64]>, // confidenza dell'agente → quote di rischio λ
cfg: &PipelineConfig, // parametri CVaR / Hull-White
) -> PipelineResult // pesi con segno + liquidità + cvar + σ
I valori predefiniti dell'overlay: coda cvar_alpha = 0.05, budget cvar_max = 0.05, EWMA ewma_lambda = 0.94, finestra Hull-White hw_window = 0 (tutta la storia). L'implementazione non ha dipendenze esterne ed è volutamente difensiva: su storie brevi (meno di 4 punti di prezzo) restituisce pesi uguali, e l'overlay CVaR si attiva solo a ≥8 osservazioni di rendimento — altrimenti non c'è niente da cui stimare una coda.
Perché Rust: un'unica codebase deterministica sia per il backtest che per la produzione, senza il divario "Python nella ricerca, qualcos'altro in produzione", e abbastanza veloce da eseguire tutti e dodici gli algoritmi in una singola richiesta attraverso il backend di confronto.
Quanto costa in tempo
Quanto è veloce "abbastanza veloce"? Abbiamo estratto il core HRP (rendimenti logaritmici → covarianza → average linkage → quasi-diagonalizzazione → pesi ricorsivi) in un benchmark autonomo e abbiamo eseguito la stessa matematica in sette linguaggi — C, C++, Rust, Zig, Python, Node.js e Bun — in condizioni identiche: Apple Silicon, singolo thread, 365 osservazioni giornaliere per asset, prezzi sintetici, conteggi di asset da 10 a 10.000.
Una parola sulla complessità, perché determina l'intera forma. La versione da manuale dell'average linkage riscansiona l'intera matrice delle distanze per la coppia più vicina ad ogni unione — è e diventa il collo di bottiglia a poche migliaia di asset. Il benchmark usa invece l'algoritmo nearest-neighbour-chain (Müllner 2011) — lo stesso che sta dietro linkage(method='average') di SciPy. Con questo in atto, il clustering non è più la fase dominante: a è ~15 ms su un passaggio di ~0.5 s. Il costo è ora dominato dalla matrice di covarianza, — l'unica fase che nessun metodo in stile HRP può evitare.
Cosa mostrano le esecuzioni (tabelle complete per linguaggio e uno script di riproduzione a un comando sono nel repository del progetto):
- Su portafogli realistici è gratuito. Un paniere crypto è composto da decine di asset, raramente più di un centinaio. Con un passaggio HRP completo è di pochi millisecondi anche in Node e microsecondi in Rust/C. Ricalcolare i pesi ad ogni tick non è un problema.
- Rust è entro ~1.0–1.3× di C — lo stesso ordine di grandezza, entrambi compilati, ed essenzialmente pari una volta che raggiunge le migliaia. C è leggermente più veloce sull'aritmetica pura, ma Rust offre la stessa prevedibilità senza garbage collector e senza UB.
- Scala a migliaia di asset. Con linkage un passaggio completo è ~0.5 s a e pochi secondi a nei linguaggi compilati; anche Node interpretato supera in meno di due secondi. Ciò che ora fissa il limite è la fase di covarianza, non il clustering.
La conclusione pragmatica: alle nostre dimensioni di portafoglio, scegliere Rust non significa "battere C" (C è leggermente più veloce qui) — significa avere un'unica codebase deterministica per la ricerca e la produzione, senza pause GC e anni di margine di performance. Il benchmark completo in sette linguaggi, con risultati e uno script di riproduzione, è aperto nel repository del progetto.
Dove si colloca Pipeline tra i dodici
Nel nostro confronto su un singolo paniere (volutamente scelto), Pipeline si è comportato come HRP — perché attraverso il punto di ingresso optimize() solo-long è HRP con un overlay CVaR. La sua logica direzionale si attiva solo quando si forniscono segnali di strategia. Questo è il punto centrale: Pipeline non è "l'ennesimo ottimizzatore per pesi di backtest" ma il livello di esecuzione tra i segnali di strategia e gli ordini reali — prende le tue chiamate di acquisto/vendita, dispone il capitale tramite HRP all'interno di ciascun lato, bilancia i lati per confidenza e taglia il rischio di coda fino a un budget stabilito.
Per il contesto completo — quali altri undici metodi esistono e come differiscono — vedere la panoramica, «12 Algoritmi di Ottimizzazione del Portafoglio a Confronto». E puoi provarli tutti dal vivo su portfolio-optimizer.marketmaker.cc.
Riferimenti
- López de Prado, M. (2016). Building Diversified Portfolios that Outperform Out of Sample. The Journal of Portfolio Management.
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
- Hull, J., & White, A. (1998). Incorporating Volatility Updating into the Historical Simulation Method for Value at Risk. Journal of Risk.
- Rockafellar, R. T., & Uryasev, S. (2000). Optimization of Conditional Value-at-Risk. Journal of Risk.
- RiskMetrics Group (1996). RiskMetrics — Technical Document. J.P. Morgan.
- Marketmaker.cc: marketmaker.cc
Citazione
@article{soloviov2026pipeline,
author = {Soloviov, Eugen and Zhuravleva, Marina and Kiselev, Kirill},
title = {Inside Our House Algorithm: HRP + Long/Short + CVaR with Hull-White Adjustment},
year = {2026},
url = {https://marketmaker.cc/it/blog/post/portfolio-pipeline-hrp-cvar},
description = {Un'analisi approfondita di Pipeline, un algoritmo composito di allocazione del portafoglio costruito su Hierarchical Risk Parity con un overlay long/short guidato dai segnali e una correzione del budget di rischio CVaR con Hull-White, con la specifica completa e la sua implementazione in Rust.}
}
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3C%2Fsvg%3E)
Financial mathematics
Fifth-year student at Bauman Moscow State Technical University (Automatic Control Systems), specializing in financial mathematics. Background in calibrating stochastic-volatility (Heston) and local-volatility (Dupire) models, fair pricing of options including exotics via both Monte-Carlo and analytic formulas, hedging-error reduction, and exposure to LSV models.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3C%2Fsvg%3E)
Portfolio optimization
Fourth-year student at the Faculty of Mechanics and Mathematics, Novosibirsk State University (NSU); thesis on Heston-model calibration and delta-hedging within the same model. Works on portfolio optimization.
Leggi di Più

12 Algoritmi di Ottimizzazione del Portafoglio a Confronto: HRP, Black-Litterman, NCO e Oltre

Teoria del Portafoglio di Markowitz per le Crypto: Da Zero a Esperto