เบื้องหลังอัลกอริทึมของเรา: HRP + Long/Short + CVaR กับ Hull-White
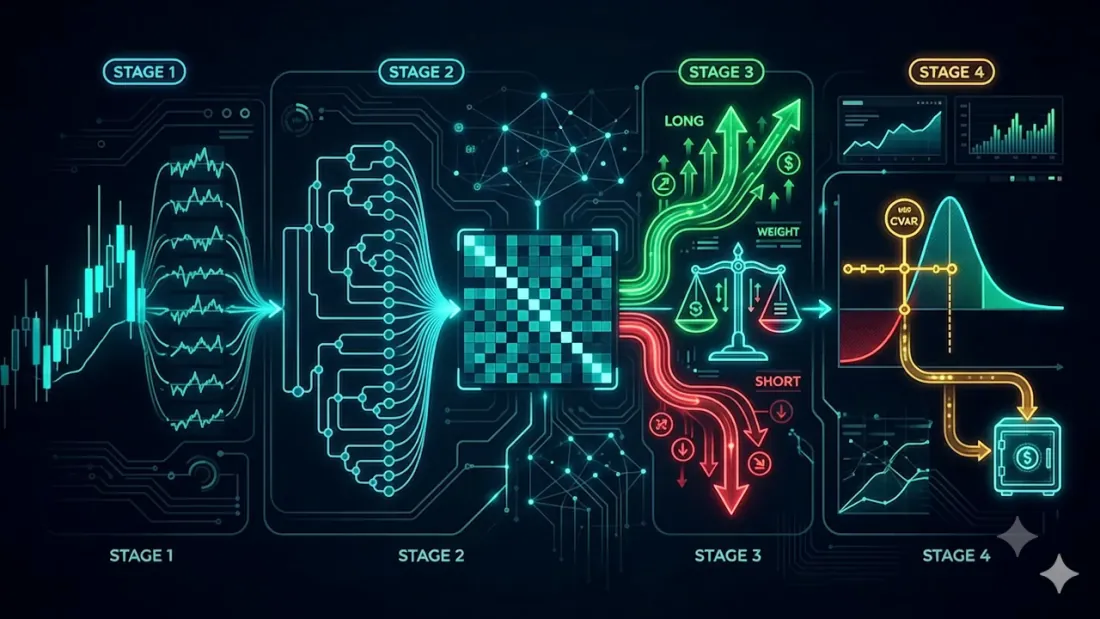
ในบทความภาพรวม «12 อัลกอริทึมการปรับพอร์ตโฟลิโอ เปรียบเทียบกัน» เราได้แข่งขันวิธีการจัดสรรสิบสองแบบเคียงกัน สิบเอ็ดแบบเป็นทฤษฎีคลาสสิก แบบที่สิบสอง คือ Pipeline — เป็นของเรา และมันได้รับเพียงหนึ่งบรรทัดในโพสต์นั้น บทความนี้คือการเจาะลึก: ข้างในมีอะไร แต่ละสูตรมาจากไหน และข้อกำหนดแปลงเป็น Rust ได้อย่างไร
Pipeline ไม่ได้คิดค้นวิธีใหม่ในการคำนวณน้ำหนัก แต่นำสูตรที่แข็งแกร่งที่สุดที่รู้จัก — Hierarchical Risk Parity (HRP) — มาห่อด้วยสองชั้นที่บัญชีซื้อขายจริงต้องการแต่ HRP ธรรมดาขาด: ทิศทาง (long/short จากสัญญาณกลยุทธ์) และ งบประมาณความเสี่ยงแบบเข้มงวด (CVaR ที่ปรับตามระบอบความผันผวนปัจจุบัน) ซึ่งให้สี่ขั้นตอน
สี่ขั้นตอน
- I — log returns ของสินทรัพย์ทุกตัว
- II — น้ำหนักพื้นฐานจาก HRP
- III — การแบ่ง long/short จากสัญญาณ agent โดยส่วนแบ่งความเสี่ยงกำหนดจากระดับความเชื่อมั่น
- IV — การปรับ CVaR ด้วยความผันผวน Hull-White; ส่วนเกินความเสี่ยงไปที่เงินสด
มาทำความเข้าใจแต่ละขั้นตามลำดับ
ขั้นตอน I. Log returns
ทุกอย่างเริ่มต้นด้วยการเปลี่ยนจากราคาเป็น log returns:
โดยที่ คือสินทรัพย์และ คือช่วงเวลา Log returns สะสมตามเวลาและมีความสมมาตรมากกว่าการเปลี่ยนแปลงเปอร์เซ็นต์ธรรมดา — ซึ่งเป็น input มาตรฐานสำหรับคณิตศาสตร์ covariance ทุกประเภท
ขั้นตอน II. HRP เป็นรากฐาน
HRP ที่ Marcos López de Prado เสนอในปี 2016 หลีกเลี่ยงโรคหลักของ Mean-Variance Optimization — การ invert เมทริกซ์ covariance ที่มีเงื่อนไขไม่ดี โดยไม่ต้อง invert เลย แต่ทำงานกับ โครงสร้าง ของ correlations แทน
Covariance และ Correlation
จาก returns เราสร้างเมทริกซ์ covariance และนอร์มัลไลซ์เป็นเมทริกซ์ correlation :
Distance Matrix
เราแปลง correlation เป็น metric ระยะทาง เพื่อให้สินทรัพย์ที่มี correlation สูงอยู่ "ใกล้กัน":
ยิ่ง ใกล้ 1 มากเท่าไร ก็ยิ่งใกล้ 0 — และสินทรัพย์มีโอกาสอยู่ใน cluster เดียวกันมากขึ้น
Dendrogram และลำดับใบ (Leaf Order)
จาก distance matrix เราสร้างลำดับชั้น cluster ผ่าน average linkage และอ่าน ลำดับใบ — การเรียงสับเปลี่ยนสินทรัพย์ที่สินทรัพย์ที่คล้ายกันอยู่ติดกัน
ขั้นตอนเสริม: จำนวน cluster ที่เหมาะสมสามารถเลือกได้ด้วย silhouette coefficient โดยที่ คือระยะทางเฉลี่ยภายใน cluster และ คือระยะทางเฉลี่ยไปยัง cluster เพื่อนบ้านที่ใกล้ที่สุด การผ่านพื้นฐานไม่ต้องการขั้นตอนนี้ — recursive bisection เคารพลำดับชั้นอยู่แล้ว
Quasi-diagonalization
เราเรียงแถวและคอลัมน์ของ ใหม่ตาม โดยรวมค่าขนาดใหญ่ไว้ตามแนวทแยง:
Recursive Bisection
จากนั้น recursion ทำงานจากบนลงล่าง ในแต่ละขั้น cluster จะถูกแบ่งครึ่งเป็น และ และทุนจะถูกจัดสรรระหว่างสองครึ่ง แบบผกผันตามความแปรปรวน (variance):
ความแปรปรวนของ cluster คำนวณบน covariance sub-block เป็น การลงลึกดำเนินต่อจนแต่ละโหนดมีสินทรัพย์เดียว น้ำหนักเป็น long-only ไม่ติดลบ รวมกันได้ 1.0
ใน implementation ของเราสิ่งนี้คือฟังก์ชัน hrp_from_cov(cov) -> Vec<f64>: correlation → distance → average linkage → leaf order → quasi-diagonalization → recursive bisection Pipeline เรียกใช้มันเป็นฐาน — และยังเป็น optimize() สาธารณะสำหรับกรณีที่ไม่มีสัญญาณอีกด้วย
ขั้นตอน III. Long/Short Overlay
HRP ธรรมดาเป็นพอร์ตโฟลิโอ "ซื้ออย่างเดียว" แต่กลยุทธ์มักบอกไม่แค่ เท่าไร แต่ ทิศทางไหน ขั้นตอน III รับสัญญาณต่อสินทรัพย์ (Long/Short) จาก agent และสร้างสอง sub-portfolios
- สินทรัพย์ถูกแบ่งเป็นตะกร้า long และ short ตามสัญญาณ
- ภายใน แต่ละ ตะกร้า น้ำหนักจะคำนวณด้วย HRP เดิม (บน covariance sub-block ของสินทรัพย์เหล่านั้น) โดยรวมกันได้ 1 ต่อตะกร้า
- หาก agent ส่ง confidence ด้วย ส่วนแบ่งความเสี่ยงระหว่างสองฝั่งจะกำหนดจาก confidence รวม:
หากไม่มี confidence ส่วนแบ่งจะย้อนกลับไปใช้จำนวนสินทรัพย์ในแต่ละตะกร้า น้ำหนักสัญลักษณ์ขั้นสุดท้ายคือ สำหรับ long และ สำหรับ short หลังจากนั้น gross exposure ทั้งหมดจะถูกนอร์มัลไลซ์ให้เท่ากับ 1
หมายเหตุตรงไปตรงมาเกี่ยวกับโค้ด ข้อกำหนดต้นฉบับมีตัวประกอบแก้ไข , — แต่ยังทำเครื่องหมายด้วยคำถามว่า "เราต้องการขั้นตอนนี้จริงหรือ?" การ implement ไม่ได้นำไปใช้: สองฝั่งถูกรวมกันโดยตรงด้วยส่วนแบ่งความเสี่ยง ซึ่งรักษา gross exposure ให้อยู่ที่ 1 พอดีและไม่สร้าง leverage ซ่อนเร้น นั่นเป็นการทำให้ข้อกำหนดเรียบง่ายโดยตั้งใจ ไม่ใช่ความผิดพลาด
ขั้นตอน IV. CVaR กับการปรับ Hull-White
HRP สมดุลความเสี่ยง เชิงโครงสร้าง แต่ไม่รู้อะไรเลยเกี่ยวกับระดับความเสี่ยงสัมบูรณ์ในแง่เงิน ขั้นตอนสุดท้ายวางเพดานแน่นบน tail risk — และทำให้มันไวต่อการเปลี่ยนแปลงของระบอบตลาด
Portfolio Return และความผันผวน EWMA
ก่อนอื่นเราสรุปน้ำหนักเป็น portfolio return และประเมินความผันผวนแบบมีเงื่อนไขด้วย EWMA:
โดย (ค่าคลาสสิก RiskMetrics) EWMA ให้ความผันผวน "วันนี้" แทนที่จะเป็นค่าเฉลี่ยตลอดประวัติทั้งหมด
การปรับ Hull-White
แนวคิดหลัก: returns ในอดีตไม่สามารถนำมาใช้ตามที่เป็นได้ — มันเกิดขึ้นภายใต้ความผันผวน ที่แตกต่างกัน วิธี Hull-White ปรับขนาด return ในอดีตแต่ละตัวให้อยู่ในระดับปัจจุบัน:
เดือนที่เงียบสงบถูก "ยืด" เดือนที่ผันผวนถูก "บีบ" และการกระจายถูกนำมาอยู่ในระบอบปัจจุบัน
VaR และ CVaR
บนการกระจายที่ปรับขนาดแล้ว เรานำ loss quantile และค่าเฉลี่ย loss ใน tail:
CVaR (หรือที่เรียกว่า Expected Shortfall) ตอบคำถามไม่ใช่ "วันที่แย่ทั่วไปแย่แค่ไหน" แต่ "แย่แค่ไหน โดยเฉลี่ยทั่ว เปอร์เซ็นต์ที่แย่ที่สุด" — ดังนั้นจึงเห็นความหนาของ tail ไม่แค่ขอบของมัน
งบประมาณความเสี่ยงและเงินสด
หาก CVaR เกินเกณฑ์ที่ยอมรับได้ ตำแหน่งที่มีความเสี่ยงทุกตัวจะถูกลดขนาดด้วยตัวประกอบเดียว และทุนที่ได้กลับมาจะถูกย้ายไปที่เงินสด:
ดังนั้นพอร์ตโฟลิโอจะลดความเสี่ยงเองเมื่อ tail risk เพิ่มขึ้น และกลับเข้าตลาดเมื่อมันสงบลง
จากข้อกำหนดสู่โค้ด
อัลกอริทึมทั้งหมดอยู่ใน Rust crate เดียว portfolio-pipeline และปฏิบัติตาม contract ของ workspace ที่เหมือนกัน:
pub fn optimize(prices: &[Vec<f64>]) -> Vec<f64>
นี่คือ long-only projection (ขั้นตอน I, II, IV ไม่มีสัญญาณ) — interface prices -> weights เดียวกันกับอัลกอริทึมอื่นอีกสิบเอ็ด ดังนั้น Pipeline จึงเป็น drop-in replacement สำหรับอัลกอริทึมใดก็ได้ เวอร์ชันเต็มที่มีทุกขั้นตอนเป็นฟังก์ชันแยก:
pub fn run(
prices: &[Vec<f64>],
signals: Option<&[Side]>, // Long / Short per asset
confidence: Option<&[f64]>, // agent confidence → risk shares λ
cfg: &PipelineConfig, // CVaR / Hull-White parameters
) -> PipelineResult // signed weights + cash + cvar + σ
ค่าเริ่มต้น overlay: tail cvar_alpha = 0.05, budget cvar_max = 0.05, EWMA ewma_lambda = 0.94, Hull-White window hw_window = 0 (ประวัติทั้งหมด) การ implement ไม่มี external dependencies และมีการป้องกันอย่างตั้งใจ: สำหรับประวัติสั้น (น้อยกว่า 4 price points) จะคืน equal weights และ CVaR overlay จะเริ่มทำงานเมื่อมี ≥8 return observations เท่านั้น — มิฉะนั้นไม่มีอะไรให้ประเมิน tail
ทำไมต้อง Rust: codebase เดียวที่กำหนดได้สำหรับทั้ง backtest และ production โดยไม่มีการเลื่อนระหว่าง "Python ในการวิจัย สิ่งอื่นใน prod" และเร็วพอที่จะรันอัลกอริทึมทั้งสิบสองในคำขอเดียวผ่าน comparison backend
ราคาในแง่เวลา
"เร็วพอ" หมายความว่าอะไร? เราดึง HRP core (log returns → covariance → average linkage → quasi-diagonalization → recursive weights) ออกมาเป็น standalone benchmark และรันคณิตศาสตร์เดียวกันใน 7 ภาษา — C, C++, Rust, Zig, Python, Node.js และ Bun — ภายใต้เงื่อนไขเดียวกัน: Apple Silicon, single thread, 365 daily observations ต่อสินทรัพย์, synthetic prices, จำนวนสินทรัพย์ จาก 10 ถึง 10,000
คำพูดเกี่ยวกับความซับซ้อน เพราะมันกำหนดรูปร่างทั้งหมด เวอร์ชันตำราของ average linkage สแกน distance matrix เต็มเพื่อหาคู่ที่ใกล้ที่สุดในทุก merge — นั่นคือ และกลายเป็น bottleneck ที่สินทรัพย์หลายพัน benchmark แทนที่ใช้อัลกอริทึม nearest-neighbour-chain แบบ (Müllner 2011) — เช่นเดียวกับที่อยู่เบื้องหลัง SciPy's linkage(method='average') ด้วยสิ่งนี้ การ clustering ไม่ใช่ขั้นตอนที่ dominant อีกต่อไป: ที่ ใช้เวลา ~15 ms จาก ~0.5 s ต่อ pass ต้นทุนตอนนี้ถูก dominate โดย covariance matrix, — ขั้นตอนเดียวที่วิธีแบบ HRP หลีกเลี่ยงไม่ได้
สิ่งที่การรันแสดงให้เห็น (ตารางต่อภาษาเต็มรูปแบบและ script การทดสอบซ้ำด้วยคำสั่งเดียวอยู่ใน project repository):
- สำหรับพอร์ตโฟลิโอที่สมจริง มันฟรี ตะกร้า crypto มีสินทรัพย์หลายสิบตัว ไม่ค่อยเกินร้อย ที่ การ pass HRP เต็มใช้ millisecond หลักเดียวแม้ใน Node และ microsecond ใน Rust/C การคำนวณน้ำหนักใหม่ทุก tick ไม่ใช่ปัญหา
- Rust อยู่ในช่วง ~1.0–1.3× ของ C — อยู่ใน order of magnitude เดียวกัน ทั้งคู่ compile และผูกกันอย่างมีประสิทธิภาพเมื่อ ถึงพัน C เร็วกว่าเล็กน้อยในการคำนวณ arithmetic แต่ Rust ให้ predictability เดียวกันโดยไม่มี garbage collector และ UB
- ขยายได้ถึงพันสินทรัพย์ ด้วย linkage แบบ การ pass เต็มใช้ ~0.5 s ที่ และไม่กี่วินาทีที่ ในภาษา compile; แม้แต่ Node แบบ interpret ก็ผ่าน ภายในสองวินาที สิ่งที่ตั้งเพดานตอนนี้คือขั้นตอน covariance ไม่ใช่ clustering
ข้อสรุปเชิงปฏิบัติ: ที่ขนาดพอร์ตโฟลิโอของเรา การเลือก Rust ไม่ใช่เพื่อ "เอาชนะ C" (C เร็วกว่าเล็กน้อยที่นี่) — แต่เพื่อ codebase เดียวที่กำหนดได้สำหรับการวิจัยและ production โดยไม่มี GC pauses และมี performance headroom หลายปี benchmark 7 ภาษาเต็ม พร้อมผลลัพธ์และ script ทดสอบซ้ำ เปิดอยู่ใน project repository
Pipeline อยู่ตรงไหนในบรรดาสิบสอง
ในการเปรียบเทียบของเราบนตะกร้าเดียว (ที่จงใจทำให้เอนเอียง) Pipeline ทำงานเหมือน HRP — เพราะผ่าน entry point optimize() แบบ long-only มัน คือ HRP กับ CVaR overlay กลไกทิศทางของมันจะมีชีวิตชีวาก็ต่อเมื่อคุณป้อนสัญญาณกลยุทธ์ให้มัน นั่นคือจุดทั้งหมด: Pipeline ไม่ใช่ "optimizer อีกตัวสำหรับ backtest weights" แต่คือ execution layer ระหว่างสัญญาณกลยุทธ์และคำสั่งจริง — รับ buy/sell calls ของคุณ จัดทุนด้วย HRP ภายในแต่ละฝั่ง สมดุลฝั่งด้วย confidence และตัด tail risk ลงสู่งบประมาณที่กำหนด
สำหรับบริบทเต็ม — วิธีอื่นอีกสิบเอ็ดมีอะไรบ้างและต่างกันอย่างไร — ดูภาพรวม «12 อัลกอริทึมการปรับพอร์ตโฟลิโอ เปรียบเทียบกัน» และคุณสามารถทดลองทั้งหมดได้ที่ portfolio-optimizer.marketmaker.cc
อ้างอิง
- López de Prado, M. (2016). Building Diversified Portfolios that Outperform Out of Sample. The Journal of Portfolio Management.
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
- Hull, J., & White, A. (1998). Incorporating Volatility Updating into the Historical Simulation Method for Value at Risk. Journal of Risk.
- Rockafellar, R. T., & Uryasev, S. (2000). Optimization of Conditional Value-at-Risk. Journal of Risk.
- RiskMetrics Group (1996). RiskMetrics — Technical Document. J.P. Morgan.
- Marketmaker.cc: marketmaker.cc
อ้างอิงบรรณานุกรม
@article{soloviov2026pipeline,
author = {Soloviov, Eugen and Zhuravleva, Marina and Kiselev, Kirill},
title = {Inside Our House Algorithm: HRP + Long/Short + CVaR with Hull-White Adjustment},
year = {2026},
url = {https://marketmaker.cc/th/blog/post/portfolio-pipeline-hrp-cvar},
description = {เจาะลึก Pipeline อัลกอริทึมการจัดสรรพอร์ตโฟลิโอแบบผสมที่สร้างบน Hierarchical Risk Parity ด้วย long/short overlay ที่ขับเคลื่อนด้วยสัญญาณและการปรับ Hull-White CVaR risk-budget พร้อมข้อกำหนดเต็มรูปแบบและ Rust implementation}
}
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3C%2Fsvg%3E)
Financial mathematics
Fifth-year student at Bauman Moscow State Technical University (Automatic Control Systems), specializing in financial mathematics. Background in calibrating stochastic-volatility (Heston) and local-volatility (Dupire) models, fair pricing of options including exotics via both Monte-Carlo and analytic formulas, hedging-error reduction, and exposure to LSV models.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3C%2Fsvg%3E)
Portfolio optimization
Fourth-year student at the Faculty of Mechanics and Mathematics, Novosibirsk State University (NSU); thesis on Heston-model calibration and delta-hedging within the same model. Works on portfolio optimization.
อ่านเพิ่มเติม

12 อัลกอริทึมการปรับพอร์ตโฟลิโอให้เหมาะที่สุด เปรียบเทียบกัน: HRP, Black-Litterman, NCO และอื่น ๆ
Monte Carlo Bootstrap: วิธีรับช่วงความเชื่อมั่นสำหรับ Backtest ใน 10 บรรทัดของโค้ด
