Bên Trong Thuật Toán Nội Bộ: HRP + Long/Short + CVaR với Hull-White
Trong bài tổng quan «12 Thuật Toán Tối Ưu Hóa Danh Mục, So Sánh» chúng tôi đã chạy đua hàng chục phương pháp phân bổ cạnh nhau. Mười một trong số đó là các kinh điển trong sách giáo khoa. Cái thứ mười hai, Pipeline, là của chúng tôi — và chỉ được đề cập một dòng trong bài đó. Bài viết này là khám phá sâu: bên trong nó có gì, mỗi công thức đến từ đâu, và đặc tả chuyển thành Rust như thế nào.
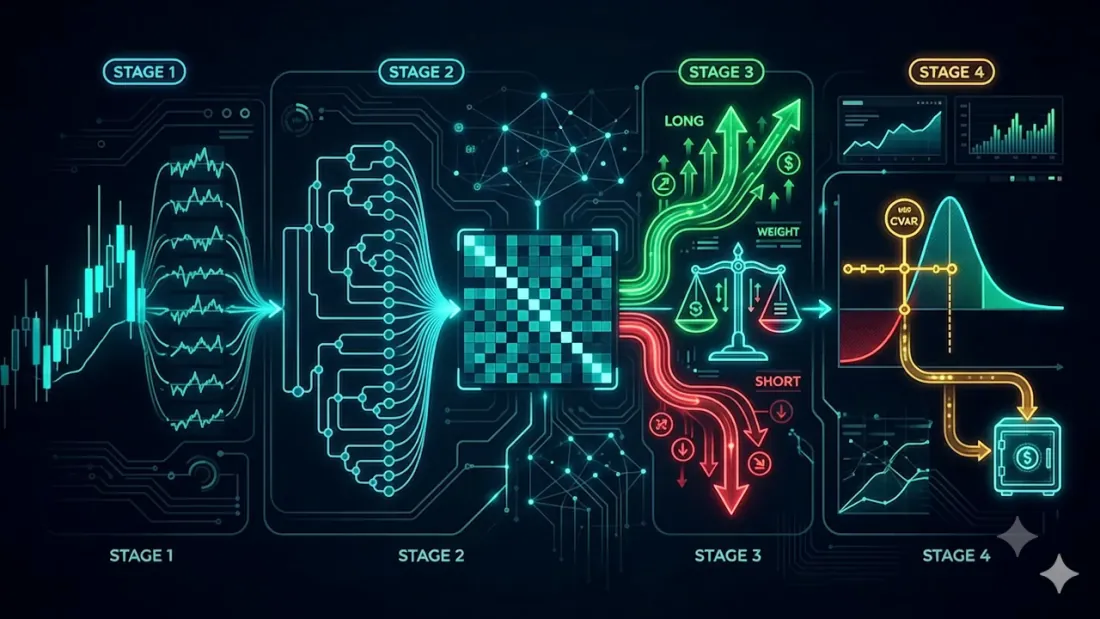
Pipeline không phát minh ra cách tính trọng số mới. Nó lấy công thức bền vững nhất được biết đến — Cân Bằng Rủi Ro Phân Cấp (HRP) — và bọc nó trong hai lớp mà một tài khoản giao dịch trực tiếp thực sự cần nhưng HRP thuần túy còn thiếu: hướng (long/short từ tín hiệu chiến lược) và ngân sách rủi ro cứng (CVaR được điều chỉnh theo chế độ biến động hiện tại). Điều đó tạo ra bốn giai đoạn.
Bốn giai đoạn
- I — log return của mỗi tài sản.
- II — trọng số cơ sở từ HRP.
- III — phân tách long/short từ tín hiệu agent, với phần rủi ro được đặt theo độ tin cậy.
- IV — hiệu chỉnh CVaR với biến động Hull-White; phần rủi ro dư thừa chuyển sang tiền mặt.
Hãy cùng đi qua từng bước theo thứ tự.
Giai Đoạn I. Log return
Mọi thứ bắt đầu với việc chuyển từ giá sang log return:
trong đó là tài sản và là bước thời gian. Log return cộng dồn theo thời gian và đối xứng hơn so với thay đổi phần trăm thông thường — đầu vào tiêu chuẩn cho bất kỳ phép tính hiệp phương sai nào.
Giai Đoạn II. HRP làm nền tảng
HRP, được đề xuất bởi Marcos López de Prado năm 2016, tránh được căn bệnh cốt lõi của Tối Ưu Hóa Trung Bình-Phương Sai — đảo ngược ma trận hiệp phương sai bị điều kiện kém. Nó hoàn toàn không đảo ngược nó. Thay vào đó, nó làm việc với cấu trúc của các tương quan.
Hiệp phương sai và tương quan
Từ các return, chúng ta xây dựng ma trận hiệp phương sai và chuẩn hóa nó thành ma trận tương quan :
Ma trận khoảng cách
Chúng ta chuyển tương quan thành một thước đo khoảng cách, sao cho các tài sản tương quan mạnh nằm "gần nhau":
càng gần 1, càng gần 0 — và các tài sản càng có khả năng chia sẻ một cụm.
Biểu đồ cây và thứ tự lá
Từ ma trận khoảng cách, chúng ta xây dựng phân cấp cụm qua liên kết trung bình và đọc ra thứ tự lá — một hoán vị của các tài sản trong đó các tài sản tương tự nhau ngồi liền kề.
Bước tùy chọn: số cụm tối ưu có thể được chọn bởi hệ số silhouette , trong đó là khoảng cách trung bình trong một cụm và là khoảng cách trung bình đến cụm lân cận gần nhất. Bước cơ sở không cần nó — phép phân đôi đệ quy đã tôn trọng phân cấp.
Quasi-diagonalization (Chuẩn hóa gần đường chéo)
Chúng ta hoán vị các hàng và cột của theo , tập hợp các giá trị lớn dọc theo đường chéo:
Phân đôi đệ quy
Sau đó phép đệ quy chạy từ trên xuống. Ở mỗi bước, một cụm được chia đôi thành và , và vốn được phân bổ giữa hai nửa tỷ lệ nghịch với phương sai của chúng:
Phương sai của một cụm được tính trên khối con hiệp phương sai của nó là . Quá trình phân rã tiếp tục cho đến khi mỗi nút chứa một tài sản duy nhất. Các trọng số chỉ dương (long-only), không âm, tổng bằng 1.0.
Trong cài đặt của chúng tôi, đây là hàm hrp_from_cov(cov) -> Vec<f64>: tương quan → khoảng cách → liên kết trung bình → thứ tự lá → quasi-diagonalization → phân đôi đệ quy. Pipeline gọi nó như nền tảng của mình — và đây cũng là optimize() công khai cho trường hợp không có tín hiệu.
Giai Đoạn III. Lớp phủ long/short
HRP thuần túy là một danh mục "chỉ mua". Nhưng một chiến lược thường nói không chỉ bao nhiêu mà còn theo hướng nào. Giai đoạn III lấy các tín hiệu theo tài sản (Long/Short) từ agent và xây dựng hai danh mục con.
- Tài sản được phân chia thành giỏ long và short theo tín hiệu.
- Bên trong mỗi giỏ, các trọng số được tính với cùng HRP (trên khối con hiệp phương sai của các tài sản đó), tổng bằng 1 mỗi giỏ.
- Nếu agent cũng phát ra độ tin cậy , các phần rủi ro giữa hai bên được đặt bởi tổng độ tin cậy:
Nếu không có độ tin cậy, các phần quay lại số lượng tài sản trong mỗi giỏ. Trọng số có dấu cuối cùng là cho các vị thế long và cho các vị thế short, sau đó toàn bộ mức độ tiếp xúc gộp được chuẩn hóa về 1.
Một ghi chú thành thật về code. Đặc tả gốc mang các hệ số hiệu chỉnh , — nhưng nó cũng đánh dấu chúng với câu hỏi "chúng ta có thực sự cần bước này không?". Cài đặt không áp dụng chúng: hai bên được kết hợp trực tiếp bởi các phần rủi ro , điều này giữ mức độ tiếp xúc gộp chính xác ở mức 1 và không tạo ra đòn bẩy ẩn. Đó là một sự đơn giản hóa có chủ đích của đặc tả, không phải sự bỏ sót.
Giai Đoạn IV. CVaR với điều chỉnh Hull-White
HRP cân bằng rủi ro về mặt cấu trúc, nhưng không biết gì về mức độ tuyệt đối của rủi ro theo giá trị tiền tệ. Giai đoạn cuối đặt trần cứng cho rủi ro đuôi — và làm cho nó nhạy cảm với sự thay đổi của chế độ thị trường.
Return danh mục và biến động EWMA
Đầu tiên chúng ta thu gọn các trọng số thành một return danh mục và ước tính biến động có điều kiện bằng EWMA:
với (giá trị RiskMetrics cổ điển). EWMA cho biến động "hôm nay" thay vì biến động trung bình trên toàn bộ lịch sử.
Tái chuẩn hóa Hull-White
Ý tưởng chính: các return trong quá khứ không thể được lấy nguyên xi — chúng xảy ra dưới một biến động khác. Phương pháp Hull-White tái chuẩn hóa mỗi return trong quá khứ về mức hiện tại:
Một tháng bình lặng bị "kéo giãn", một tháng biến động bị "nén lại", và phân phối được đưa về chế độ hiện tại.
VaR và CVaR
Trên phân phối đã tái chuẩn hóa, chúng ta lấy phân vị tổn thất và tổn thất trung bình trong đuôi:
CVaR (còn gọi là Expected Shortfall) không trả lời "một ngày tệ thông thường xấu đến mức nào" mà là "nó xấu đến mức nào trung bình trên phần trăm tồi tệ nhất" — vì vậy nó thấy được độ dày của đuôi, không chỉ mép của nó.
Ngân sách rủi ro và tiền mặt
Nếu CVaR vượt quá ngưỡng có thể chấp nhận, mọi vị thế rủi ro đều bị thu nhỏ theo một hệ số duy nhất, và vốn được giải phóng chuyển sang tiền mặt:
Vì vậy danh mục tự giảm rủi ro khi rủi ro đuôi tăng và tái gia nhập thị trường khi nó dịu xuống.
Từ đặc tả đến code
Toàn bộ thuật toán nằm trong một Rust crate duy nhất, portfolio-pipeline, và tuân theo hợp đồng thống nhất của workspace:
pub fn optimize(prices: &[Vec<f64>]) -> Vec<f64>
Đây là phép chiếu chỉ-long (giai đoạn I, II, IV không có tín hiệu) — cùng giao diện prices -> weights chính xác như mười một thuật toán khác, vì vậy Pipeline là sự thay thế trực tiếp cho bất kỳ thuật toán nào trong số chúng. Phiên bản đầy đủ với mọi giai đoạn là một hàm riêng biệt:
pub fn run(
prices: &[Vec<f64>],
signals: Option<&[Side]>, // Long / Short per asset
confidence: Option<&[f64]>, // agent confidence → risk shares λ
cfg: &PipelineConfig, // CVaR / Hull-White parameters
) -> PipelineResult // signed weights + cash + cvar + σ
Các giá trị mặc định của lớp phủ: đuôi cvar_alpha = 0.05, ngân sách cvar_max = 0.05, EWMA ewma_lambda = 0.94, cửa sổ Hull-White hw_window = 0 (toàn bộ lịch sử). Cài đặt không có phụ thuộc bên ngoài và được thiết kế phòng thủ có chủ đích: trên các lịch sử ngắn (ít hơn 4 điểm giá) nó trả về trọng số bằng nhau, và lớp phủ CVaR chỉ kích hoạt ở ≥8 quan sát return — nếu không có gì để ước tính đuôi.
Tại sao Rust: một codebase xác định cho cả backtest và production, không có sự trôi dạt "Python trong nghiên cứu, thứ khác trong prod", và đủ nhanh để chạy cả mười hai thuật toán trong một yêu cầu duy nhất qua backend so sánh.
Chi phí về thời gian
"Đủ nhanh" nghĩa là bao nhiêu? Chúng tôi đã tách lõi HRP (log return → hiệp phương sai → liên kết trung bình → quasi-diagonalization → trọng số đệ quy) thành một benchmark độc lập và chạy toán học giống hệt nhau trên bảy ngôn ngữ — C, C++, Rust, Zig, Python, Node.js và Bun — trong điều kiện giống hệt nhau: Apple Silicon, một luồng đơn, 365 quan sát hàng ngày mỗi tài sản, giá tổng hợp, số lượng tài sản từ 10 đến 10,000.
Một lưu ý về độ phức tạp, vì nó định hình toàn bộ bức tranh. Phiên bản sách giáo khoa của liên kết trung bình quét lại toàn bộ ma trận khoảng cách để tìm cặp gần nhất ở mỗi lần hợp nhất — đó là và trở thành nút thắt ở vài nghìn tài sản. Benchmark thay vào đó sử dụng thuật toán chuỗi hàng xóm gần nhất (Müllner 2011) — thuật toán tương tự đằng sau linkage(method='average') của SciPy. Với điều đó, phân cụm không còn là giai đoạn chi phối: ở nó là ~15 ms trong tổng số ~0.5 s. Chi phí hiện được chi phối bởi ma trận hiệp phương sai, — giai đoạn duy nhất mà không phương pháp kiểu HRP nào có thể tránh.
Những gì các lần chạy cho thấy (bảng đầy đủ theo từng ngôn ngữ và script tái tạo một lệnh nằm trong kho dự án):
- Trên các danh mục thực tế, nó miễn phí. Một giỏ crypto gồm hàng chục tài sản, hiếm khi hơn một trăm. Ở một lần chạy HRP đầy đủ là mili giây đơn lẻ ngay cả trong Node và micro giây trong Rust/C. Tính toán lại trọng số trên mỗi tick không phải vấn đề.
- Rust trong khoảng ~1.0–1.3× so với C — cùng bậc độ lớn, cả hai được biên dịch, và về cơ bản ngang nhau khi đạt hàng nghìn. C nhanh hơn một chút trên số học thô, nhưng Rust cho cùng tính dự đoán không có bộ thu gom rác và không có UB.
- Mở rộng đến hàng nghìn tài sản. Với liên kết , một lần chạy đầy đủ là ~0.5 s ở và vài giây ở trong các ngôn ngữ được biên dịch; ngay cả Node thông dịch cũng vượt qua trong dưới hai giây. Những gì đặt ra giới hạn bây giờ là giai đoạn hiệp phương sai, không phải phân cụm.
Kết luận thực tế: ở kích thước danh mục của chúng tôi, chọn Rust không phải về "đánh bại C" (C nhanh hơn một chút ở đây) — mà là về một codebase xác định cho nghiên cứu và production, không có GC pauses và nhiều năm dư địa hiệu suất. Benchmark bảy ngôn ngữ đầy đủ, với kết quả và script tái tạo, được mở trong kho dự án.
Pipeline nằm ở đâu trong số mười hai thuật toán
Trong so sánh của chúng tôi trên một giỏ đơn (được thiết kế có chủ đích), Pipeline hoạt động giống như HRP — vì qua điểm vào optimize() chỉ-long nó là HRP với lớp phủ CVaR. Cỗ máy định hướng của nó chỉ hoạt động khi bạn đưa cho nó các tín hiệu chiến lược. Đó là toàn bộ vấn đề: Pipeline không phải là "một bộ tối ưu hóa khác để backtest trọng số" mà là lớp thực thi giữa tín hiệu chiến lược và lệnh thực — nó nhận các lệnh mua/bán của bạn, phân bổ vốn theo HRP trong mỗi bên, cân bằng các bên theo độ tin cậy, và cắt rủi ro đuôi xuống một ngân sách đã đặt.
Để có bối cảnh đầy đủ — mười một phương pháp khác tồn tại như thế nào và chúng khác nhau ra sao — xem tổng quan, «12 Thuật Toán Tối Ưu Hóa Danh Mục, So Sánh». Và bạn có thể thử tất cả trực tiếp tại portfolio-optimizer.marketmaker.cc.
Tài liệu tham khảo
- López de Prado, M. (2016). Building Diversified Portfolios that Outperform Out of Sample. The Journal of Portfolio Management.
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
- Hull, J., & White, A. (1998). Incorporating Volatility Updating into the Historical Simulation Method for Value at Risk. Journal of Risk.
- Rockafellar, R. T., & Uryasev, S. (2000). Optimization of Conditional Value-at-Risk. Journal of Risk.
- RiskMetrics Group (1996). RiskMetrics — Technical Document. J.P. Morgan.
- Marketmaker.cc: marketmaker.cc
Trích dẫn
@article{soloviov2026pipeline,
author = {Soloviov, Eugen and Zhuravleva, Marina and Kiselev, Kirill},
title = {Inside Our House Algorithm: HRP + Long/Short + CVaR with Hull-White Adjustment},
year = {2026},
url = {https://marketmaker.cc/vi/blog/post/portfolio-pipeline-hrp-cvar},
description = {A deep dive into Pipeline, a composite portfolio allocation algorithm built on Hierarchical Risk Parity with a signal-driven long/short overlay and a Hull-White CVaR risk-budget correction, with the full specification and its Rust implementation.}
}
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3C%2Fsvg%3E)
Financial mathematics
Fifth-year student at Bauman Moscow State Technical University (Automatic Control Systems), specializing in financial mathematics. Background in calibrating stochastic-volatility (Heston) and local-volatility (Dupire) models, fair pricing of options including exotics via both Monte-Carlo and analytic formulas, hedging-error reduction, and exposure to LSV models.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3C%2Fsvg%3E)
Portfolio optimization
Fourth-year student at the Faculty of Mechanics and Mathematics, Novosibirsk State University (NSU); thesis on Heston-model calibration and delta-hedging within the same model. Works on portfolio optimization.
Đọc Thêm

12 Thuật Toán Tối Ưu Hóa Danh Mục Đầu Tư, So Sánh: HRP, Black-Litterman, NCO và Hơn Thế Nữa

Lý thuyết danh mục đầu tư Markowitz cho Crypto: Từ Cơ Bản đến Nâng Cao