Cascade Strategies: Priority Execution with Fallback Filling

Finale of the "Backtests Without Illusions" series. How to build an orchestrator from N strategies on M pairs, implement cascade mode with priority and fallback execution, choose dual_size, and why strategy portfolios cannot be backtested by simply summing PnL.
Why You Need a Strategy Portfolio
 Multiple strategies compete for limited capital — most sit idle while only a few trade at any given time
Multiple strategies compete for limited capital — most sit idle while only a few trade at any given time
You've put a strategy through the full pipeline. Monte Carlo bootstrap showed an acceptable 5th percentile. Walk-forward confirmed out-of-sample returns. Funding rates are accounted for, plateau analysis passed. The strategy genuinely works.
But it trades 15% of the time. The remaining 85% your capital sits idle.
Run a second strategy? A third? A tenth? The idea is obvious. The implementation is not. A strategy portfolio creates problems that don't exist with a single bot:
- Conflicts: two strategies want to open opposite positions on the same pair.
- Constraints: the exchange/risk management allows no more than simultaneous positions.
- Allocation: what fraction of capital to give each strategy?
- Correlation: 10 strategies on correlated crypto pairs is not 10x diversification.
Cascade strategy is an architectural pattern that solves these problems: the primary strategy gets the full position size, while the fallback strategy fills idle time with a reduced position.
The Cascade Concept: Primary + Fallback

High-Conviction Strategy (Primary)
Primary is a strategy with strict entry criteria. For example, triple timeframe with three confirming levels: signal on daily + 4-hour + hourly, with volatility and volume filtering.
Characteristics:
- Few trades (tens over the backtest period)
- High PnL per trade
- Low time in position (5-15%)
- High confidence in each entry
Fallback Strategy
Fallback is a strategy with relaxed criteria. Dual timeframe, fewer filters, wider tolerances. It trades more frequently, but with lower edge per trade.
Characteristics:
- More trades (hundreds over the period)
- Moderate PnL per trade
- High time in position (30-50%)
- Moderate confidence — compensated by reduced position size
Cascade Mode
timeline: ──────────────────────────────────────────────────
primary: ___████___________________████████____███________
fallback: ███____███████████████████________████___████████
capital: [dual][ full ][ dual_size ][ full ][ dual ]
When primary opens a position — fallback goes silent (or closes). When primary is idle — fallback trades at a reduced position (dual_size). Priority is unconditional: primary always displaces fallback.
Strategies for Examples
Throughout the series we used three strategies. Here are their parameters for the 750-day period:
| Parameter | Strategy A | Strategy B | Strategy C |
|---|---|---|---|
| PnL | +55% | +27% | +300% |
| Trades | ~500 | ~40 | ~400 |
| Trading time | ~15% | ~5% | ~45% |
| MaxDD | ~0.9% | ~0.75% | ~17% |
| PnL/active day | 0.49%/d | 0.72%/d | 0.89%/d |
| Character | Medium activity | Rare, high conviction | Frequent, aggressive |
As we showed in PnL per Active Time, ranking by raw PnL and by PnL/active day produces different results. For cascade orchestration, the second metric is what matters.
Optimal dual_size
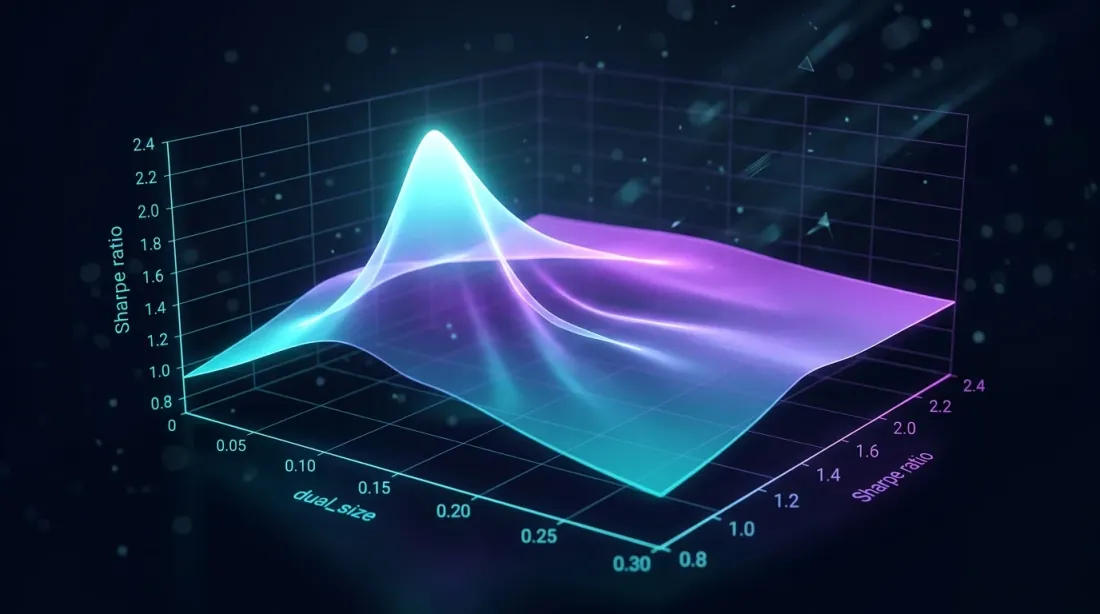 Grid search over dual_size reveals a Sharpe ratio peak — too large increases drawdown, too small wastes idle time
Grid search over dual_size reveals a Sharpe ratio peak — too large increases drawdown, too small wastes idle time
The Selection Problem
dual_size is the fraction of the full position that the fallback strategy receives. It is the key cascade parameter:
-
Too large (e.g., 0.5 = 50%): when primary and fallback are active simultaneously, total exposure = 150% of target. Drawdown doubles. Loss-profit asymmetry makes this disproportionately expensive.
-
Too small (e.g., 0.01 = 1%): fallback fills 85% of idle time but earns pennies. Capital effectively sits idle.
-
Optimal: fallback contributes meaningful PnL without critically increasing drawdown during simultaneous operation with primary.
Formalization
Let:
- — primary PnL per unit of time
- — fallback PnL per unit of time
- — fraction of time in position (primary)
- — fraction of time in position (fallback)
- — dual_size (0..1)
- — fraction of time when both are in position
Total cascade PnL:
Total MaxDD (worst case — full correlation):
If we constrain total drawdown to :
Grid Search
In practice, the optimal dual_size is found via grid search on the cascade backtest:
import numpy as np
from dataclasses import dataclass
@dataclass
class CascadeResult:
dual_size: float
total_pnl: float
max_dd: float
sharpe: float
pnl_per_active_day: float
def grid_search_dual_size(
primary_equity: np.ndarray, # equity curve primary (minute bars)
fallback_equity: np.ndarray, # equity curve fallback (minute bars)
primary_positions: np.ndarray, # 1 = in position, 0 = flat
fallback_positions: np.ndarray,
grid: np.ndarray = np.arange(0.01, 0.30, 0.005),
) -> list[CascadeResult]:
"""
Grid search for dual_size.
primary_equity and fallback_equity are log-returns, minute bars.
"""
results = []
for d in grid:
fallback_active = fallback_positions & ~primary_positions
cascade_returns = (
primary_equity * primary_positions
+ d * fallback_equity * fallback_active
)
equity_curve = np.cumprod(1 + cascade_returns)
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
max_dd = drawdown.min()
total_pnl = equity_curve[-1] - 1
sharpe = (
np.mean(cascade_returns) / np.std(cascade_returns)
* np.sqrt(525_600) # minutes per year
) if np.std(cascade_returns) > 0 else 0
active_minutes = np.sum(primary_positions | fallback_active)
active_days = active_minutes / (24 * 60)
pnl_per_day = total_pnl / active_days if active_days > 0 else 0
results.append(CascadeResult(
dual_size=d,
total_pnl=total_pnl,
max_dd=max_dd,
sharpe=sharpe,
pnl_per_active_day=pnl_per_day,
))
return sorted(results, key=lambda r: r.sharpe, reverse=True)
Typical optimum for crypto strategies: dual_size in the range 0.05-0.10 (5-10% of full position). With Strategy B as primary (MaxDD 0.75%) and Strategy A as fallback (MaxDD 0.9%):
The drawdown constraint is not binding — the optimum is determined by cascade Sharpe. In practice, grid search typically yields (6.8%).
Score-Based Allocation
 Strategies ranked by composite score — confidence adjustment penalizes small samples, funding costs reduce net edge
Strategies ranked by composite score — confidence adjustment penalizes small samples, funding costs reduce net edge
When there are more than two strategies, cascade generalizes to score-based allocation.
Ranking by PnL per Active Time
As described in detail in PnL per Active Time, the strategy score is calculated accounting for:
- PnL per active day — capital utilization efficiency
- Confidence adjustment — penalty for small samples (t-distribution)
- Funding costs — real cost of leverage (Funding rates)
- MaxLev — scaling with drawdown consideration (Loss-profit asymmetry)
Confidence Adjustment for Rare Strategies
Strategy B with 40 trades requires a serious penalty. We use the lower bound of the confidence interval:
import scipy.stats as st
import numpy as np
def confidence_factor(trade_returns: np.ndarray, confidence: float = 0.95) -> float:
"""Confidence factor: 0..1, penalty for small samples."""
n = len(trade_returns)
if n < 10:
return 0.0
mean_r = np.mean(trade_returns)
if mean_r <= 0:
return 0.0
se = np.std(trade_returns, ddof=1) / np.sqrt(n)
t_crit = st.t.ppf(1 - (1 - confidence) / 2, df=n - 1)
ci_lower = mean_r - t_crit * se
return max(0.0, ci_lower / mean_r)
cf_b = confidence_factor(np.random.normal(0.0067, 0.028, 40))
cf_a = confidence_factor(np.random.normal(0.0011, 0.008, 500))
Funding Cost Integration
On perpetual futures, funding is paid every 8 hours. With leverage and average rate :
For Strategy A with MaxLev = 55x and average funding rate 0.01%:
With PnL/active day = 0.49%, net PnL is negative: /day. The strategy is unprofitable at full leverage. Detailed analysis in Funding Rates Kill Your Leverage.
Multi-Strategy Orchestrator
Architecture
The orchestrator manages strategies on trading pairs. Total number of potential positions: . But capital is limited — no more than simultaneous positions (slots) are allowed.
┌─────────────────────────────────────────────┐
│ ORCHESTRATOR │
│ │
│ Signal Queue (sorted by score): │
│ ┌──────────────────────────────────────┐ │
│ │ 1. Strategy C × ETHUSDT score=223 │ │
│ │ 2. Strategy B × BTCUSDT score=142 │ │
│ │ 3. Strategy A × SOLUSDT score=100 │ │
│ │ 4. Strategy C × BTCUSDT score=89 │ │
│ │ 5. Strategy A × ETHUSDT score=76 │ │
│ └──────────────────────────────────────┘ │
│ │
│ Active Slots (max_parallel = 3): │
│ ┌──────────────────────────────────────┐ │
│ │ Slot 1: Strategy C × ETHUSDT [FULL] │ │
│ │ Slot 2: Strategy B × BTCUSDT [FULL] │ │
│ │ Slot 3: Strategy A × SOLUSDT [DUAL] │ │
│ └──────────────────────────────────────┘ │
│ │
│ Conflict Rules: │
│ - One position per pair │
│ - Primary displaces fallback on same pair │
│ - Higher score wins for cross-pair slots │
└─────────────────────────────────────────────┘
Slot Management
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import heapq
import time
class SlotType(Enum):
FULL = "full" # primary strategy, 100% position
DUAL = "dual" # fallback strategy, dual_size position
@dataclass
class Signal:
strategy_id: str
pair: str
direction: str # "long" | "short"
score: float
is_primary: bool # primary or fallback
timestamp: float
@dataclass(order=True)
class Slot:
"""A single orchestrator slot."""
priority: float = field(compare=True) # negative score for min-heap
strategy_id: str = field(compare=False)
pair: str = field(compare=False)
slot_type: SlotType = field(compare=False)
entry_time: float = field(compare=False)
class Orchestrator:
"""
Multi-strategy orchestrator with cascade mode.
Manages N strategies x M pairs within max_parallel_positions slots.
Primary strategies have unconditional priority over fallback.
"""
def __init__(
self,
max_parallel_positions: int = 10,
dual_size: float = 0.068,
min_score: float = 0,
):
self.max_parallel = max_parallel_positions
self.dual_size = dual_size
self.min_score = min_score
self.active_slots: dict[str, Slot] = {} # pair -> Slot
self.pending_signals: list[Signal] = []
def on_signal(self, signal: Signal) -> Optional[dict]:
"""
Process a new signal. Returns an action or None.
Actions:
- {"action": "open", "pair": ..., "size": ..., "slot_type": ...}
- {"action": "replace", "pair": ..., "close_strategy": ..., "open_strategy": ...}
- None (signal rejected)
"""
if signal.score < self.min_score:
return None
pair = signal.pair
if pair in self.active_slots:
existing = self.active_slots[pair]
if signal.is_primary and existing.slot_type == SlotType.DUAL:
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=SlotType.FULL,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": 1.0,
}
if signal.score > -existing.priority:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # existing has higher priority
if len(self.active_slots) < self.max_parallel:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "open",
"pair": pair,
"strategy": signal.strategy_id,
"size": size,
"slot_type": slot_type,
}
worst_pair = min(
self.active_slots,
key=lambda p: -self.active_slots[p].priority,
)
worst_slot = self.active_slots[worst_pair]
if signal.score > -worst_slot.priority:
del self.active_slots[worst_pair]
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": worst_slot.strategy_id,
"close_pair": worst_pair,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # all active slots have higher scores
def on_exit(self, pair: str) -> None:
"""Strategy closed a position."""
if pair in self.active_slots:
del self.active_slots[pair]
def utilization(self) -> float:
"""Current slot utilization."""
return len(self.active_slots) / self.max_parallel
def fill_efficiency_snapshot(self) -> float:
"""Weighted utilization: FULL=1.0, DUAL=dual_size."""
total = sum(
1.0 if s.slot_type == SlotType.FULL else self.dual_size
for s in self.active_slots.values()
)
return total / self.max_parallel
Conflict Resolution
Three levels of conflict:
Level 1 — Same pair, same direction. The strategy with the higher score wins. If both are primary — score determines the winner. If one is primary and the other fallback — primary wins unconditionally.
Level 2 — Same pair, opposite direction. Prohibited: you cannot simultaneously be long and short on the same pair. The strategy with the highest score wins.
Level 3 — Cross-pair competition. When all slots are occupied, a new signal evicts the slot with the lowest score. This works as a priority queue.
Cascade Backtesting: Methodology
 Joint simulation: primary and fallback equity curves with overlap zones and the combined cascade result
Joint simulation: primary and fallback equity curves with overlap zones and the combined cascade result
Why You Can't Just Sum PnL
The naive approach: backtest each strategy separately, sum the PnL. This produces an inflated result for three reasons:
-
Time overlap. When primary and fallback are active simultaneously, fallback should not trade (or trades at dual_size). Simple summing ignores this overlap.
-
Capital constraint. Total position is limited. If 5 strategies want to open simultaneously but there are only 3 slots — two strategies won't enter. Their PnL cannot be counted.
-
Transaction costs. Cascade switching (closing fallback, opening primary) generates additional commissions not present in individual backtests.
Joint Simulation
The correct cascade backtest is a joint simulation of all strategies on a shared timeline:
import numpy as np
from typing import NamedTuple
class Trade(NamedTuple):
strategy: str
pair: str
entry_time: int # minute index
exit_time: int # minute index
pnl_per_minute: float # log-return per minute
is_primary: bool
score: float
def backtest_cascade(
all_trades: list[Trade],
total_minutes: int,
max_slots: int = 10,
dual_size: float = 0.068,
switch_cost: float = 0.0006, # 0.06% round-trip
) -> dict:
"""
Joint simulation of cascade portfolio.
Walk through each minute, apply orchestrator rules,
calculate PnL accounting for overlap and slot constraints.
"""
entries = {}
exits = {}
active_trades = {} # trade_id -> Trade
for i, trade in enumerate(all_trades):
entries.setdefault(trade.entry_time, []).append((i, trade))
exits.setdefault(trade.exit_time, []).append((i, trade))
active_slots = {} # pair -> (trade_id, SlotType)
equity = np.ones(total_minutes)
switch_costs_total = 0.0
for t in range(1, total_minutes):
for trade_id, trade in exits.get(t, []):
if trade.pair in active_slots:
slot_id, _ = active_slots[trade.pair]
if slot_id == trade_id:
del active_slots[trade.pair]
new_signals = sorted(
entries.get(t, []),
key=lambda x: x[1].score,
reverse=True,
)
for trade_id, trade in new_signals:
pair = trade.pair
if pair in active_slots:
existing_id, existing_type = active_slots[pair]
existing_trade = all_trades[existing_id]
if trade.is_primary and existing_type == SlotType.DUAL:
active_slots[pair] = (trade_id, SlotType.FULL)
switch_costs_total += switch_cost
continue
if trade.score > existing_trade.score:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
switch_costs_total += switch_cost
elif len(active_slots) < max_slots:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
minute_return = 0.0
for pair, (trade_id, slot_type) in active_slots.items():
trade = all_trades[trade_id]
size = 1.0 if slot_type == SlotType.FULL else dual_size
minute_return += trade.pnl_per_minute * size
equity[t] = equity[t - 1] * (1 + minute_return)
peak = np.maximum.accumulate(equity)
max_dd = ((equity - peak) / peak).min()
total_pnl = equity[-1] - 1 - switch_costs_total
return {
"total_pnl": total_pnl,
"max_dd": max_dd,
"switch_costs": switch_costs_total,
"equity_curve": equity,
}
Transaction Cost on Switching
Each cascade switch (fallback -> primary) requires:
- Closing the fallback position: taker fee (0.04% on Binance futures)
- Opening the primary position: taker fee (0.04%)
- Spread: ~0.01-0.02%
Total switch cost: ~0.06-0.10% per switch. With 100 switches over the period:
This is a significant amount. A cascade with frequent switching can underperform a single strategy due to transaction costs.
Multi-Pair Extension: N Strategies on M Pairs
 Network of N strategies connected to M trading pairs — correlation strength determines effective diversification
Network of N strategies connected to M trading pairs — correlation strength determines effective diversification
Combination Space
3 strategies on 10 pairs = 30 potential signals. With max_slots = 5, the orchestrator selects the top 5 by score. This is a combinatorial problem: possible portfolios at each moment.
In practice, a greedy algorithm (sort by score, fill top-down) produces near-optimal results in .
Correlation Between Pairs
Crypto pairs are strongly correlated. BTC drops — ETH, SOL, AVAX drop together. This means 5 long positions on 5 different pairs are effectively one large position on the "crypto market."
As we analyzed in detail in Signal Correlation, the effective number of independent positions:
where is the average correlation between pairs.
With and :
Five positions on correlated pairs are equivalent to 1.3 independent positions. Diversification is virtually absent.
Practical Implications for Cascade
def effective_diversification(
positions: list[dict], # [{"pair": "BTCUSDT", "direction": "long"}, ...]
correlation_matrix: np.ndarray,
pair_index: dict[str, int],
) -> float:
"""
Calculate effective diversification of open positions.
Returns:
N_eff / N — diversification coefficient (0..1)
"""
n = len(positions)
if n <= 1:
return 1.0
total_corr = 0.0
pairs_count = 0
for i in range(n):
for j in range(i + 1, n):
idx_i = pair_index[positions[i]["pair"]]
idx_j = pair_index[positions[j]["pair"]]
rho = correlation_matrix[idx_i, idx_j]
if positions[i]["direction"] != positions[j]["direction"]:
rho = -rho
total_corr += rho
pairs_count += 1
avg_rho = total_corr / pairs_count if pairs_count > 0 else 0
n_eff = n / (1 + (n - 1) * max(0, avg_rho))
return n_eff / n
The orchestrator should account for correlation when filling slots. Two options:
- Diversification bonus: when ranking, add a bonus to the score of strategies on uncorrelated pairs.
- Correlation cap: limit the number of same-direction positions on correlated pairs.
Cascade Optimization Pipeline
 Eight connected stages from data preparation through validation to live orchestration — each builds on the previous
Eight connected stages from data preparation through validation to live orchestration — each builds on the previous
The full pipeline from data to production consists of 8 stages:
Stage 0: Data Preparation
Load historical data, build Parquet cache for multi-timeframe access. Without efficient caching, subsequent stages are unacceptably slow.
Stage 1: TF + Length (Hill-Climbing Grid)
Select the base timeframe and indicator window lengths. Coarse grid: TF from {1m, 5m, 15m, 1h, 4h}, Length from {10, 20, 50, 100, 200}. Hill-climbing from the best grid point.
Stage 2: Separation (Coordinate Descent, 12 Parameters)
Optimize separation parameters (entries/exits). Coordinate descent over 12 parameters — indicator thresholds, filters, stop-losses, take-profits. Coordinate descent is cheaper than Optuna for high-dimensional deterministic objective functions.
Stage 3: Meta-Parameters (Coordinate Descent)
Meta-parameters: max hold time, min PnL for exit, trailing stop configuration. Again coordinate descent. Check robustness via plateau analysis — if the optimum is point-like, the strategy is over-optimized.
Stage 4: Combo Optimization
Grid search over pairs (Primary, Fallback). For each combination: select dual_size, calculate cascade PnL via joint simulation.
Stage 5: Validation
Multi-level validation:
- Multi-symbol: strategy tested on 10+ pairs, not just the optimization pair
- Walk-forward: sliding IS/OOS window
- Parameter stability: plateau analysis at each stage
- Monte Carlo bootstrap: confidence intervals for cascade PnL
- Backtest-live parity: comparison of backtest with paper trading
Stage 6: Ranking and Selection
Rank cascade combinations by score. Top-K combinations advance to Stage 7. Score accounts for confidence adjustment, funding costs, and fill_efficiency.
Stage 7: Orchestration
Final stage: launch the orchestrator on strategies and pairs in cascade mode. Slot management, priority queue, conflict resolution — everything described above.
Performance Analysis: Cascade vs. Individual
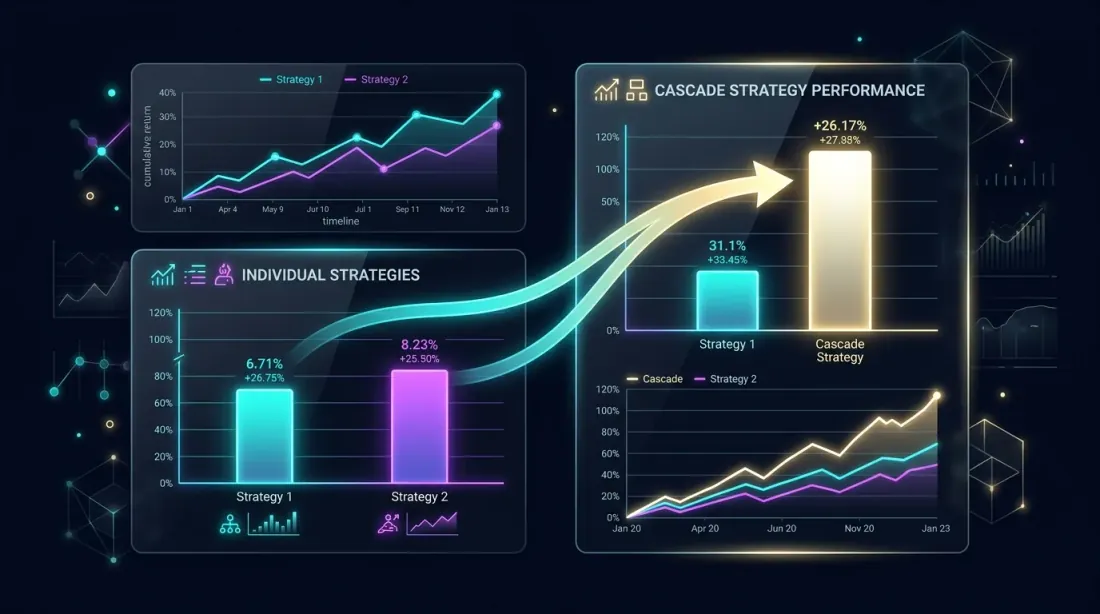 Side-by-side comparison: cascade portfolio outperforms individual strategies through idle time utilization
Side-by-side comparison: cascade portfolio outperforms individual strategies through idle time utilization
Theoretical Cascade Advantage
Suppose primary trades of the time with PnL/day = 0.49%. Fallback trades with PnL/day = 0.89%. Overlap = (assuming independence).
Primary alone (Strategy A):
Cascade (A primary + C fallback):
Cascade gain: +31% to PnL from fallback, with minimal drawdown increase ( added to MaxDD).
When Cascade Doesn't Help
Cascade is ineffective when:
- Primary is active >80% of the time. Little idle time — nowhere for fallback to fit in.
- Strategies are highly correlated. Primary and fallback generate signals simultaneously — overlap is high, and fallback is idle precisely when primary is also idle.
- Switch costs exceed fallback PnL. With frequent switching, cascade commissions eat fallback profits.
- dual_size is too small. At , fallback earns 1% of its potential — below commissions.
Comparison Table
| Configuration | Annual PnL | MaxDD | Sharpe | Switch costs |
|---|---|---|---|---|
| Strategy A alone | 26.8% | 0.9% | 1.42 | 0 |
| Strategy C alone | 146.1% | 17% | 1.15 | 0 |
| Cascade A+C (d=0.068) | 35.2% | 2.06% | 1.58 | ~1.2% |
| Cascade B+A (d=0.068) | 19.4% | 1.36% | 1.71 | ~0.3% |
| 3-strategy orchestrator | 48.7% | 3.1% | 1.63 | ~2.1% |
Cascade A+C: primary A gains +8.4% from fallback C. Sharpe rises through idle time utilization. MaxDD grows moderately ().
Orchestration: fill_efficiency in Practice
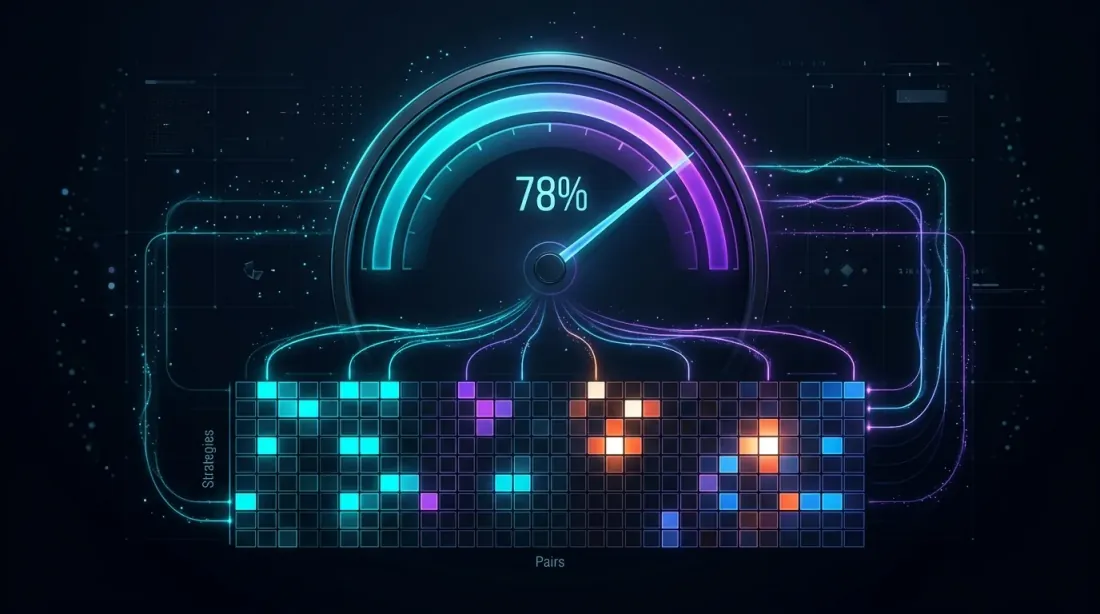 Fill efficiency at ~78%: heatmap shows time utilization across strategies and pairs, bright cells indicate active trading
Fill efficiency at ~78%: heatmap shows time utilization across strategies and pairs, bright cells indicate active trading
The fill_efficiency parameter determines what fraction of idle time the orchestrator actually utilizes. As shown in PnL per Active Time, it can be estimated three ways:
- Fixed constant (0.80) — rough but universal
- Analytical estimate via — accounts for correlation
- Simulation from data — most accurate
For a cascade with 3 strategies on 10 pairs:
def cascade_fill_efficiency(
strategies: list[dict], # [{"trading_time": 0.15, "is_primary": True}, ...]
n_pairs: int = 10,
correlation_factor: float = 3.0,
) -> float:
"""Estimate fill_efficiency for a cascade portfolio."""
n_eff = n_pairs / correlation_factor
primary_times = [s["trading_time"] for s in strategies if s["is_primary"]]
p_primary = 1 - np.prod([(1 - t) ** n_eff for t in primary_times])
fallback_times = [s["trading_time"] for s in strategies if not s["is_primary"]]
p_fallback = 1 - np.prod([(1 - t) ** n_eff for t in fallback_times])
fill = p_primary + (1 - p_primary) * p_fallback
return min(fill, 1.0)
strategies = [
{"trading_time": 0.05, "is_primary": True}, # Strategy B
{"trading_time": 0.15, "is_primary": True}, # Strategy A
{"trading_time": 0.45, "is_primary": False}, # Strategy C as fallback
]
eff = cascade_fill_efficiency(strategies, n_pairs=10, correlation_factor=3.0)
Practical Recommendations
 Six key recommendations for cascade deployment — from starting small to adaptive recalibration
Six key recommendations for cascade deployment — from starting small to adaptive recalibration
1. Start with Two Strategies
Don't launch 10 strategies on 20 pairs right away. Start with one primary + one fallback on 3-5 pairs. Make sure the joint simulation matches real behavior. Backtest-live parity is critical: if the cascade backtest diverges from live by even 5-10% — there's an error in orchestrator logic.
2. dual_size from Grid Search, Not Intuition
The optimal dual_size depends on the specific pair of strategies. 6.8% is a guideline, not a universal constant. Run grid search from 1% to 30% with 0.5% steps and select the Sharpe maximum.
3. Slot Limit Defines Architecture
With max_slots = 1, cascade degenerates into simple strategy switching. With max_slots = 50, the constraint is not binding and the problem reduces to an independent portfolio. The interesting zone: max_slots = 3-10, where slot management genuinely impacts results.
4. Account for Latency
In live trading, cascade switching is not instantaneous. Closing a fallback position + opening primary = 2 API calls + network latency + exchange matching. On a volatile market, the price can move in 200-500ms. Build in a slippage budget.
5. Monitor fill_efficiency
Track real fill_efficiency in production. If it is significantly lower than backtested — the orchestrator is not utilizing idle time as expected. Causes: API delays, rejected orders, margin constraints.
6. Use Adaptive Optimization
Cascade parameters (dual_size, score weights, slot limits) should not be static. Use adaptive drill-down for periodic recalibration on fresh data. The market changes — cascade parameters should follow.
"Backtests Without Illusions" Series: Summary
 Complete system architecture: 13 interconnected modules from mathematics through validation to live orchestration
Complete system architecture: 13 interconnected modules from mathematics through validation to live orchestration
This article is the finale of a 13+ article series. Each article addressed one specific problem on the path from backtest to production. Here's how they connect:
Foundation: Return Mathematics
Loss-Profit Asymmetry — the multiplicative nature of returns, volatility drag, Kelly criterion. This is the mathematical foundation for everything that follows: why MaxDD determines leverage, why Sharpe matters more than raw PnL, why a 50% win rate with symmetric R:R is unprofitable.
Validation: Confidence Intervals and Robustness
Monte Carlo Bootstrap — turning a single-point estimate into a distribution with confidence intervals. Any metric (PnL, MaxDD, Sharpe) only makes sense with a confidence interval.
Walk-Forward Optimization — out-of-sample validation. A backtest on historical data is an IS result; WFO shows how the strategy performs on new data.
Plateau Analysis — parameter robustness check. If the optimum is point-like, the strategy is over-optimized.
Backtest-Live Parity — comparing backtest with real results. The final check before scaling.
Realistic Costs: Funding and Leverage
Funding Rates Kill Leverage — the hidden cost of leverage on perpetual futures. Without accounting for funding, a beautiful backtest turns into a loss.
Funding Rate Arbitrage — how to turn funding from an expense into a revenue source through cross-exchange strategies.
Metrics and Ranking
PnL per Active Time — the metric for ranking strategies in a portfolio. Raw PnL doesn't scale; PnL/active day does.
Signal Correlation — effective diversification in a portfolio of correlated pairs.
Infrastructure and Optimization
Parquet Cache for Multi-Timeframe Backtests — data infrastructure for fast iterations.
Adaptive Drill-Down — adaptive optimization: coarse grid -> fine-tuning in promising zones.
Optuna vs. Coordinate Descent — optimizer selection: Optuna for low dimensions with noisy objectives, coordinate descent for high dimensions with smooth objectives.
Polars vs Pandas — DataFrame operation performance for backtesting.
Orchestration (This Article)
Cascade Strategies — combining all previous components into a working system. Score-based allocation uses PnL/active time, confidence adjustment, funding costs. Cascade mode fills idle time. Joint simulation validates the portfolio. Monte Carlo bootstrap provides confidence intervals for cascade PnL.
Each article is an independent module. Together they form a complete pipeline from data loading to live orchestration of a strategy portfolio.
Conclusion
Cascade is not the only approach to strategy portfolios. But it is one of the simplest and most practical: the primary strategy trades at full capacity, fallback fills idle time at a reduced position. Two key parameters (dual_size and max_slots) provide sufficient flexibility for most configurations.
Three takeaways:
-
Cascade must be backtested via joint simulation only. Summing individual PnL inflates results. Switch costs, overlap, slot constraints — all of this is only captured in joint simulation.
-
dual_size determines the PnL vs. drawdown trade-off. Typical optimum is 5-10%. Grid search on Sharpe is a reliable selection method.
-
The orchestrator is a score-based priority queue. Everything reduces to a single number (score) for each signal. Score = f(PnL/active day, MaxLev, confidence, funding). Strategies with the highest score get slots. The rest wait.
The "Backtests Without Illusions" series demonstrates one thing: between a beautiful backtest and real profit lie dozens of pitfalls. Each article removes one. Cascade orchestration is the last step: turning a set of validated strategies into a working portfolio.
Useful Links
- López de Prado — Advances in Financial Machine Learning: Portfolio Construction
- Pardo, R. — The Evaluation and Optimization of Trading Strategies
- Ernest Chan — Algorithmic Trading: Winning Strategies and Their Rationale
- Perry Kaufman — Trading Systems and Methods, Chapter on Portfolio Allocation
- Tomasini, Jaekle — Trading Systems: A New Approach to System Development and Portfolio Optimisation
- Bailey, D.H. & López de Prado — The Deflated Sharpe Ratio
- Markowitz, H. — Portfolio Selection (1952)
- Kelly, J.L. — A New Interpretation of Information Rate (1956)
Citation
@article{soloviov2026cascadestrategies,
author = {Soloviov, Eugen},
title = {Cascade Strategies: Priority Execution with Fallback Filling},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/cascade-strategies-orchestration},
version = {0.1.0},
description = {Finale of the "Backtests Without Illusions" series. How to build an orchestrator from N strategies x M pairs, implement cascade mode with priority and fallback filling, choose dual\_size, and why strategy portfolios cannot be backtested by summing PnL.}
}
MarketMaker.cc Team
Сандық зерттеулер және стратегия