「回测无幻觉」系列终篇。如何构建N策略在M交易对上的编排器,实现级联模式的优先和fallback执行,选择dual_size,以及为什么不能通过简单汇总PnL来回测策略组合。
为什么需要策略组合
 多个策略竞争有限资金——在任何给定时刻,大多数策略处于闲置状态,只有少数在交易
多个策略竞争有限资金——在任何给定时刻,大多数策略处于闲置状态,只有少数在交易
您已经让策略通过了完整的流水线。Monte Carlo bootstrap显示了可接受的第5百分位数。Walk-forward确认了样本外收益。资金费率已计入,平台期分析已通过。策略确实有效。
但它只在15%的时间内交易。其余85%的时间您的资金处于闲置状态。
启动第二个策略?第三个?第十个?想法很明显。实现却不然。策略组合会产生单个机器人不存在的问题:
- 冲突:两个策略想要在同一交易对上开反向仓位。
- 限制:交易所/风控管理最多允许同时持有个仓位。
- 分配:每个策略应分配多少资金比例?
- 相关性:10个策略在相关的加密货币对上——这不是10倍分散化。
Cascade策略——是一种架构模式,用于解决这些问题:优先策略获得完整仓位大小,而fallback策略以缩减仓位填充空闲期。
级联概念:primary + fallback

高确信策略(primary)
Primary——是入场标准严格的策略。例如,三重时间框架加三个确认级别:日线+4小时+小时线上的信号,辅以波动率和成交量过滤。
特征:
- 交易少(回测期间数十笔)
- 每笔交易PnL高
- 持仓时间短(5-15%)
- 每次入场的确信度高
Fallback策略
Fallback——是入场标准放宽的策略。双重时间框架,更少的过滤器,更宽的容差。它交易更频繁,但每笔交易的edge更小。
特征:
- 交易多(期间数百笔)
- 每笔交易PnL适中
- 持仓时间长(30-50%)
- 中等确信度——通过缩减仓位来补偿
Cascade模式
timeline: ──────────────────────────────────────────────────
primary: ___████___________________████████____███________
fallback: ███____███████████████████________████___████████
capital: [dual][ full ][ dual_size ][ full ][ dual ]
当primary开仓时——fallback保持沉默(或平仓)。当primary处于空闲状态时——fallback以缩减仓位(dual_size)进行交易。优先级是无条件的:primary始终取代fallback。
示例中使用的策略
在整个系列中,我们使用了三个策略。以下是它们在750天期间的参数:
| 参数 | Strategy A | Strategy B | Strategy C |
|---|---|---|---|
| PnL | +55% | +27% | +300% |
| 交易数 | ~500 | ~40 | ~400 |
| 交易时间 | ~15% | ~5% | ~45% |
| MaxDD | ~0.9% | ~0.75% | ~17% |
| PnL/活跃天 | 0.49%/天 | 0.72%/天 | 0.89%/天 |
| 特征 | 中等活跃度 | 稀少、高确信度 | 频繁、激进 |
正如我们在文章按活跃时间的PnL中所示,按原始PnL排序和按PnL/活跃天排序会得出不同的结果。对于cascade编排来说,第二个指标才是关键。
最优dual_size
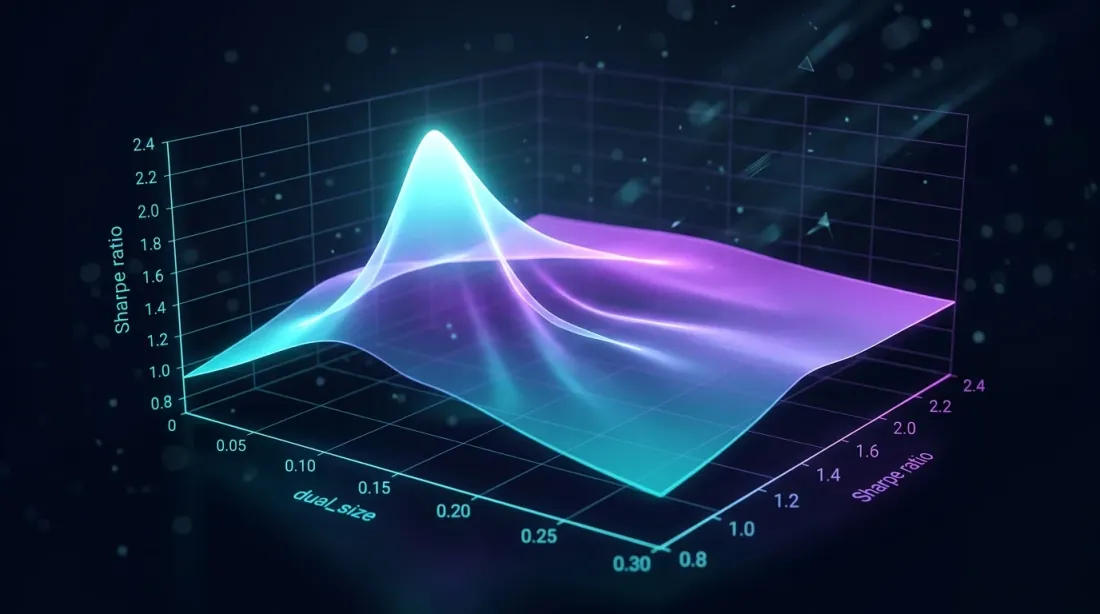 对dual_size进行网格搜索揭示Sharpe ratio峰值——值太大增加回撤,值太小浪费闲置时间
对dual_size进行网格搜索揭示Sharpe ratio峰值——值太大增加回撤,值太小浪费闲置时间
选择问题
dual_size——是fallback策略获得的完整仓位的比例。这是cascade的关键参数:
-
过大(例如,0.5 = 50%):当primary和fallback同时活跃时,总敞口 = 目标的150%。回撤翻倍。亏损不对称性使其代价不成比例地高昂。
-
过小(例如,0.01 = 1%):fallback填充了85%的空闲时间,但收益微乎其微。资金实际上仍在闲置。
-
最优:fallback贡献显著的PnL份额,同时不会在与primary同时运行时显著增加回撤。
形式化
设:
- — primary每单位时间的PnL
- — fallback每单位时间的PnL
- — 持仓时间比例(primary)
- — 持仓时间比例(fallback)
- — dual_size(0..1)
- — 两者同时持仓的时间比例
Cascade总PnL:
总MaxDD(最坏情况——完全相关):
如果将总回撤限制在水平:
网格搜索
在实践中,最优dual_size通过cascade回测的网格搜索来选择:
import numpy as np
from dataclasses import dataclass
@dataclass
class CascadeResult:
dual_size: float
total_pnl: float
max_dd: float
sharpe: float
pnl_per_active_day: float
def grid_search_dual_size(
primary_equity: np.ndarray, # primary的权益曲线(分钟K线)
fallback_equity: np.ndarray, # fallback的权益曲线(分钟K线)
primary_positions: np.ndarray, # 1 = 持仓, 0 = 空仓
fallback_positions: np.ndarray,
grid: np.ndarray = np.arange(0.01, 0.30, 0.005),
) -> list[CascadeResult]:
"""
dual_size的网格搜索。
primary_equity和fallback_equity——对数收益率,分钟K线。
"""
results = []
for d in grid:
fallback_active = fallback_positions & ~primary_positions
cascade_returns = (
primary_equity * primary_positions
+ d * fallback_equity * fallback_active
)
equity_curve = np.cumprod(1 + cascade_returns)
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
max_dd = drawdown.min()
total_pnl = equity_curve[-1] - 1
sharpe = (
np.mean(cascade_returns) / np.std(cascade_returns)
* np.sqrt(525_600) # 一年的分钟数
) if np.std(cascade_returns) > 0 else 0
active_minutes = np.sum(primary_positions | fallback_active)
active_days = active_minutes / (24 * 60)
pnl_per_day = total_pnl / active_days if active_days > 0 else 0
results.append(CascadeResult(
dual_size=d,
total_pnl=total_pnl,
max_dd=max_dd,
sharpe=sharpe,
pnl_per_active_day=pnl_per_day,
))
return sorted(results, key=lambda r: r.sharpe, reverse=True)
加密策略的典型最优值:dual_size在0.05-0.10范围内(完整仓位的5-10%)。以Strategy B作为primary(MaxDD 0.75%)和Strategy A作为fallback(MaxDD 0.9%):
回撤限制不构成约束——最优值由cascade的夏普比率决定。在实践中,网格搜索通常给出(6.8%)。
基于评分的分配
 策略按复合评分排名——置信度调整惩罚小样本,资金费率降低净优势
策略按复合评分排名——置信度调整惩罚小样本,资金费率降低净优势
当策略超过两个时,cascade可以推广为基于评分的分配。
按活跃时间PnL排序
正如在文章按活跃时间的PnL中详细描述的,策略的评分计算考虑:
低频策略的置信度调整
Strategy B只有40笔交易,需要显著的惩罚。我们使用置信区间的下界:
import scipy.stats as st
import numpy as np
def confidence_factor(trade_returns: np.ndarray, confidence: float = 0.95) -> float:
"""置信度因子:0..1,小样本惩罚。"""
n = len(trade_returns)
if n < 10:
return 0.0
mean_r = np.mean(trade_returns)
if mean_r <= 0:
return 0.0
se = np.std(trade_returns, ddof=1) / np.sqrt(n)
t_crit = st.t.ppf(1 - (1 - confidence) / 2, df=n - 1)
ci_lower = mean_r - t_crit * se
return max(0.0, ci_lower / mean_r)
cf_b = confidence_factor(np.random.normal(0.0067, 0.028, 40))
cf_a = confidence_factor(np.random.normal(0.0011, 0.008, 500))
资金费率成本整合
在永续合约上,资金费率每8小时支付一次。在杠杆和平均费率下:
对于Strategy A,MaxLev = 55x,平均资金费率0.01%:
当PnL/活跃天 = 0.49%时,净PnL为负:/天。策略在全杠杆下是亏损的。详细分析见文章资金费率杀死你的杠杆。
多策略编排器
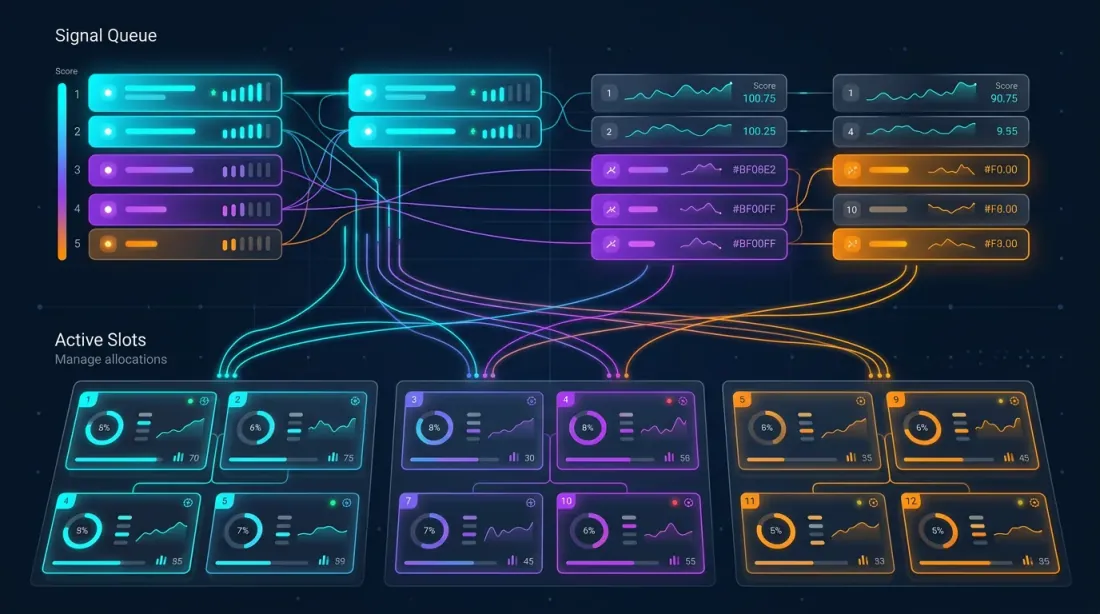
架构
编排器管理个策略在个交易对上。潜在仓位总数:。但资金有限——最多允许个同时仓位(槽位)。
┌─────────────────────────────────────────────┐
│ ORCHESTRATOR │
│ │
│ Signal Queue (sorted by score): │
│ ┌──────────────────────────────────────┐ │
│ │ 1. Strategy C × ETHUSDT score=223 │ │
│ │ 2. Strategy B × BTCUSDT score=142 │ │
│ │ 3. Strategy A × SOLUSDT score=100 │ │
│ │ 4. Strategy C × BTCUSDT score=89 │ │
│ │ 5. Strategy A × ETHUSDT score=76 │ │
│ └──────────────────────────────────────┘ │
│ │
│ Active Slots (max_parallel = 3): │
│ ┌──────────────────────────────────────┐ │
│ │ Slot 1: Strategy C × ETHUSDT [FULL] │ │
│ │ Slot 2: Strategy B × BTCUSDT [FULL] │ │
│ │ Slot 3: Strategy A × SOLUSDT [DUAL] │ │
│ └──────────────────────────────────────┘ │
│ │
│ Conflict Rules: │
│ - One position per pair │
│ - Primary displaces fallback on same pair │
│ - Higher score wins for cross-pair slots │
└─────────────────────────────────────────────┘
槽位管理
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import heapq
import time
class SlotType(Enum):
FULL = "full" # 主策略,100%仓位
DUAL = "dual" # 备用策略,dual_size仓位
@dataclass
class Signal:
strategy_id: str
pair: str
direction: str # "long" | "short"
score: float
is_primary: bool # 主策略还是备用策略
timestamp: float
@dataclass(order=True)
class Slot:
"""编排器的一个槽位。"""
priority: float = field(compare=True) # 负score用于最小堆
strategy_id: str = field(compare=False)
pair: str = field(compare=False)
slot_type: SlotType = field(compare=False)
entry_time: float = field(compare=False)
class Orchestrator:
"""
带cascade模式的多策略编排器。
在max_parallel_positions个槽位范围内管理N策略×M交易对。
Primary策略对fallback具有无条件优先权。
"""
def __init__(
self,
max_parallel_positions: int = 10,
dual_size: float = 0.068,
min_score: float = 0,
):
self.max_parallel = max_parallel_positions
self.dual_size = dual_size
self.min_score = min_score
self.active_slots: dict[str, Slot] = {} # pair -> Slot
self.pending_signals: list[Signal] = []
def on_signal(self, signal: Signal) -> Optional[dict]:
"""
处理新信号。返回action或None。
Actions:
- {"action": "open", "pair": ..., "size": ..., "slot_type": ...}
- {"action": "replace", "pair": ..., "close_strategy": ..., "open_strategy": ...}
- None(信号被拒绝)
"""
if signal.score < self.min_score:
return None
pair = signal.pair
if pair in self.active_slots:
existing = self.active_slots[pair]
if signal.is_primary and existing.slot_type == SlotType.DUAL:
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=SlotType.FULL,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": 1.0,
}
if signal.score > -existing.priority:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": existing.strategy_id,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # 现有槽位优先级更高
if len(self.active_slots) < self.max_parallel:
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "open",
"pair": pair,
"strategy": signal.strategy_id,
"size": size,
"slot_type": slot_type,
}
worst_pair = min(
self.active_slots,
key=lambda p: -self.active_slots[p].priority,
)
worst_slot = self.active_slots[worst_pair]
if signal.score > -worst_slot.priority:
del self.active_slots[worst_pair]
slot_type = SlotType.FULL if signal.is_primary else SlotType.DUAL
size = 1.0 if signal.is_primary else self.dual_size
self.active_slots[pair] = Slot(
priority=-signal.score,
strategy_id=signal.strategy_id,
pair=pair,
slot_type=slot_type,
entry_time=signal.timestamp,
)
return {
"action": "replace",
"pair": pair,
"close_strategy": worst_slot.strategy_id,
"close_pair": worst_pair,
"open_strategy": signal.strategy_id,
"size": size,
}
return None # 所有活跃槽位的score更高
def on_exit(self, pair: str) -> None:
"""策略平仓。"""
if pair in self.active_slots:
del self.active_slots[pair]
def utilization(self) -> float:
"""当前槽位利用率。"""
return len(self.active_slots) / self.max_parallel
def fill_efficiency_snapshot(self) -> float:
"""加权利用率:FULL=1.0,DUAL=dual_size。"""
total = sum(
1.0 if s.slot_type == SlotType.FULL else self.dual_size
for s in self.active_slots.values()
)
return total / self.max_parallel
冲突解决
三级冲突:
第1级——同一交易对,同一方向。 评分更高的策略获胜。如果两者都是primary——评分决定胜者。如果一个是primary,另一个是fallback——primary无条件优先。
第2级——同一交易对,反向方向。 禁止:不能在同一交易对上同时持有多空仓位。评分最高的策略获胜。
第3级——跨交易对竞争。 当所有槽位已满时,新信号淘汰评分最低的槽位。这作为优先级队列工作。
Cascade回测:方法论
 联合模拟:primary和fallback的权益曲线及重叠区域,以及合并后的级联结果
联合模拟:primary和fallback的权益曲线及重叠区域,以及合并后的级联结果
为什么不能简单地累加PnL
简单方法:分别回测每个策略,累加PnL。这会得出偏高的结果,原因有三:
-
时间重叠。 当primary和fallback同时活跃时,fallback不应交易(或以dual_size交易)。简单累加忽略了这种重叠。
-
资金约束。 总仓位有限。如果5个策略想同时开仓,但只有3个槽位——两个策略无法入场。它们的PnL不能计入。
-
交易成本。 Cascade切换(关闭fallback,开启primary)产生额外佣金,这在单独回测中不存在。
联合模拟
正确的cascade回测是所有策略在共同时间轴上的联合模拟:
import numpy as np
from typing import NamedTuple
class Trade(NamedTuple):
strategy: str
pair: str
entry_time: int # 分钟索引
exit_time: int # 分钟索引
pnl_per_minute: float # 每分钟对数收益率
is_primary: bool
score: float
def backtest_cascade(
all_trades: list[Trade],
total_minutes: int,
max_slots: int = 10,
dual_size: float = 0.068,
switch_cost: float = 0.0006, # 0.06%往返
) -> dict:
"""
Cascade组合的联合模拟。
遍历每一分钟,应用编排器规则,
计算考虑重叠和槽位约束的PnL。
"""
entries = {}
exits = {}
active_trades = {} # trade_id -> Trade
for i, trade in enumerate(all_trades):
entries.setdefault(trade.entry_time, []).append((i, trade))
exits.setdefault(trade.exit_time, []).append((i, trade))
active_slots = {} # pair -> (trade_id, SlotType)
equity = np.ones(total_minutes)
switch_costs_total = 0.0
for t in range(1, total_minutes):
for trade_id, trade in exits.get(t, []):
if trade.pair in active_slots:
slot_id, _ = active_slots[trade.pair]
if slot_id == trade_id:
del active_slots[trade.pair]
new_signals = sorted(
entries.get(t, []),
key=lambda x: x[1].score,
reverse=True,
)
for trade_id, trade in new_signals:
pair = trade.pair
if pair in active_slots:
existing_id, existing_type = active_slots[pair]
existing_trade = all_trades[existing_id]
if trade.is_primary and existing_type == SlotType.DUAL:
active_slots[pair] = (trade_id, SlotType.FULL)
switch_costs_total += switch_cost
continue
if trade.score > existing_trade.score:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
switch_costs_total += switch_cost
elif len(active_slots) < max_slots:
slot_type = SlotType.FULL if trade.is_primary else SlotType.DUAL
active_slots[pair] = (trade_id, slot_type)
minute_return = 0.0
for pair, (trade_id, slot_type) in active_slots.items():
trade = all_trades[trade_id]
size = 1.0 if slot_type == SlotType.FULL else dual_size
minute_return += trade.pnl_per_minute * size
equity[t] = equity[t - 1] * (1 + minute_return)
peak = np.maximum.accumulate(equity)
max_dd = ((equity - peak) / peak).min()
total_pnl = equity[-1] - 1 - switch_costs_total
return {
"total_pnl": total_pnl,
"max_dd": max_dd,
"switch_costs": switch_costs_total,
"equity_curve": equity,
}
切换的交易成本
每次cascade切换(fallback -> primary)需要:
- 平仓fallback仓位:taker手续费(Binance期货0.04%)
- 开仓primary仓位:taker手续费(0.04%)
- 价差:~0.01-0.02%
单次切换总成本:~0.06-0.10%。在100次切换的情况下:
这是一个显著的数值。频繁切换的cascade可能因交易成本而不如单一策略。
多交易对扩展:N策略在M交易对上
 N个策略连接到M个交易对的网络——相关性强度决定有效分散化程度
N个策略连接到M个交易对的网络——相关性强度决定有效分散化程度
组合空间
3个策略在10个交易对上 = 30个潜在信号。当max_slots = 5时,编排器选择评分最高的5个。这是一个组合问题:每个时刻有个可能的组合。
在实践中,贪心算法(按score排序,从上到下填充)给出接近最优的结果,时间复杂度为。
交易对间的相关性
加密货币对高度相关。BTC下跌——ETH、SOL、AVAX一起下跌。这意味着5个不同交易对上的5个多头仓位——实际上是对"加密市场"的一个大仓位。
正如我们在文章信号相关性中详细分析的,有效独立仓位数:
其中是交易对之间的平均相关性。
当且时:
相关交易对上的五个仓位等价于1.3个独立仓位。分散化几乎不存在。
对cascade的实际影响
def effective_diversification(
positions: list[dict], # [{"pair": "BTCUSDT", "direction": "long"}, ...]
correlation_matrix: np.ndarray,
pair_index: dict[str, int],
) -> float:
"""
计算持仓的有效分散化程度。
Returns:
N_eff / N — 分散化系数(0..1)
"""
n = len(positions)
if n <= 1:
return 1.0
total_corr = 0.0
pairs_count = 0
for i in range(n):
for j in range(i + 1, n):
idx_i = pair_index[positions[i]["pair"]]
idx_j = pair_index[positions[j]["pair"]]
rho = correlation_matrix[idx_i, idx_j]
if positions[i]["direction"] != positions[j]["direction"]:
rho = -rho
total_corr += rho
pairs_count += 1
avg_rho = total_corr / pairs_count if pairs_count > 0 else 0
n_eff = n / (1 + (n - 1) * max(0, avg_rho))
return n_eff / n
编排器在填充槽位时必须考虑相关性。两种方案:
- 分散化奖励:在排序时,为不相关交易对上的策略评分添加奖励。
- 相关性上限:限制相关交易对上同向仓位的数量。
Cascade优化流水线
 从数据准备到验证再到上线编排的八个相连阶段——每个阶段建立在前一个的基础上
从数据准备到验证再到上线编排的八个相连阶段——每个阶段建立在前一个的基础上
从数据到生产环境的完整流水线由8个阶段组成:
阶段0:数据准备
加载历史数据,构建Parquet缓存以实现多时间框架访问。没有高效的缓存,后续阶段将慢到无法接受。
阶段1:TF + Length(爬山网格)
选择基础时间框架和指标窗口长度。粗网格:TF从{1m, 5m, 15m, 1h, 4h},Length从{10, 20, 50, 100, 200}。从网格最佳点开始爬山搜索。
阶段2:Separation(坐标下降,12个参数)
优化分离参数(入场/出场)。12个参数的坐标下降——指标阈值、过滤器、止损、止盈。在高维度和确定性目标函数下,坐标下降比Optuna更经济。
阶段3:元参数(坐标下降)
元参数:最大持仓时间、退出的最小PnL、跟踪止损配置。同样使用坐标下降。通过平台期分析检验稳健性——如果最优值是孤立的点,则策略过度优化。
阶段4:组合优化
对(Primary, Fallback)交易对进行网格搜索。对每种组合:调整dual_size,通过联合模拟计算cascade PnL。
阶段5:验证
多层验证:
- 多品种:策略在10+交易对上测试,不仅限于优化交易对
- Walk-forward:滑动窗口IS/OOS
- 参数稳定性:每个阶段的平台期分析
- Monte Carlo bootstrap:cascade PnL的置信区间
- 回测与实盘一致性:回测与模拟交易的对照
阶段6:排序和选择
按score排序cascade组合。前K个组合进入阶段7。Score考虑置信度调整、资金费率成本和fill_efficiency。
阶段7:编排
最终阶段:在cascade模式下启动策略和交易对的编排器。槽位管理、优先级队列、冲突解决——以上所有内容。
性能分析:cascade vs 单独策略
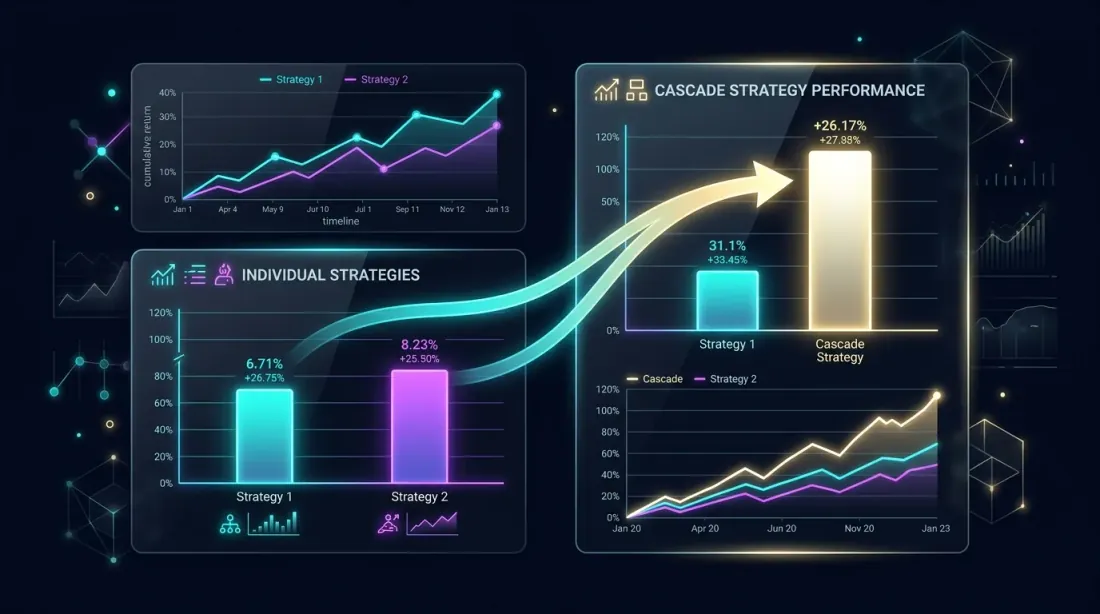 对比:级联组合通过利用闲置时间超越单独策略的表现
对比:级联组合通过利用闲置时间超越单独策略的表现
Cascade的理论优势
假设primary在的时间内交易,PnL/天 = 0.49%。Fallback在的时间内交易,PnL/天 = 0.89%。重叠时间 = (假设独立)。
单独primary(Strategy A):
Cascade(A primary + C fallback):
Cascade增益:fallback贡献+31%的PnL,而回撤仅增加很少(对MaxDD的增加)。
当cascade无效时
Cascade在以下情况下无效:
- Primary活跃时间>80%。 空闲期少——fallback无处插入。
- 策略高度相关。 Primary和fallback同时发出信号——重叠度高,fallback恰好在primary也空闲的时候空闲。
- 切换成本超过fallback的PnL。 频繁切换时,cascade佣金吃掉fallback的利润。
- dual_size太小。 当时,fallback只赚取其潜力的1%——低于佣金。
对比表
| 配置 | 年化PnL | MaxDD | 夏普比率 | 切换成本 |
|---|---|---|---|---|
| Strategy A单独 | 26.8% | 0.9% | 1.42 | 0 |
| Strategy C单独 | 146.1% | 17% | 1.15 | 0 |
| Cascade A+C (d=0.068) | 35.2% | 2.06% | 1.58 | ~1.2% |
| Cascade B+A (d=0.068) | 19.4% | 1.36% | 1.71 | ~0.3% |
| 三策略编排器 | 48.7% | 3.1% | 1.63 | ~2.1% |
Cascade A+C:primary A从fallback C获得+8.4%。夏普比率因空闲时间利用而上升。MaxDD增长适度()。
编排:实践中的fill_efficiency
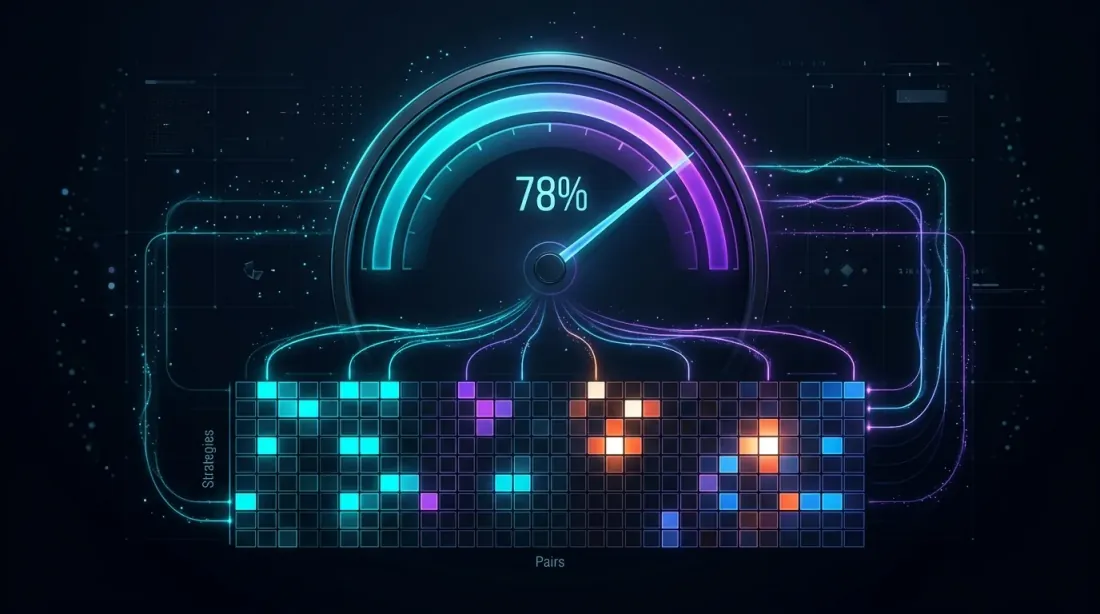 Fill efficiency约78%:热力图显示各策略和交易对的时间利用率,明亮的单元格表示活跃交易
Fill efficiency约78%:热力图显示各策略和交易对的时间利用率,明亮的单元格表示活跃交易
参数fill_efficiency决定了编排器实际利用了多少空闲时间。正如在文章按活跃时间的PnL中所示,可以通过三种方式估算:
- 固定常数(0.80)——粗略但通用
- 解析估计通过——考虑相关性
- 从数据模拟——最精确
对于3个策略在10个交易对上的cascade:
def cascade_fill_efficiency(
strategies: list[dict], # [{"trading_time": 0.15, "is_primary": True}, ...]
n_pairs: int = 10,
correlation_factor: float = 3.0,
) -> float:
"""估算cascade组合的fill_efficiency。"""
n_eff = n_pairs / correlation_factor
primary_times = [s["trading_time"] for s in strategies if s["is_primary"]]
p_primary = 1 - np.prod([(1 - t) ** n_eff for t in primary_times])
fallback_times = [s["trading_time"] for s in strategies if not s["is_primary"]]
p_fallback = 1 - np.prod([(1 - t) ** n_eff for t in fallback_times])
fill = p_primary + (1 - p_primary) * p_fallback
return min(fill, 1.0)
strategies = [
{"trading_time": 0.05, "is_primary": True}, # Strategy B
{"trading_time": 0.15, "is_primary": True}, # Strategy A
{"trading_time": 0.45, "is_primary": False}, # Strategy C作为fallback
]
eff = cascade_fill_efficiency(strategies, n_pairs=10, correlation_factor=3.0)
实践建议
 级联部署的六个关键建议——从简单起步到自适应重新校准
级联部署的六个关键建议——从简单起步到自适应重新校准
1. 从两个策略开始
不要一开始就在20个交易对上运行10个策略。先从一个primary + 一个fallback在3-5个交易对上开始。确保联合模拟与实际行为一致。回测与实盘一致性至关重要:如果cascade回测与实盘偏差哪怕5-10%——编排器逻辑有误。
2. dual_size来自网格搜索,而非直觉
最优dual_size取决于具体的策略对。6.8%——是参考值,不是通用常数。运行从1%到30%、步长0.5%的网格搜索,选择夏普比率最大值。
3. 槽位限制决定架构
当max_slots = 1时,cascade退化为策略间的简单切换。当max_slots = 50时,限制不构成约束,问题简化为独立投资组合。有趣的区域:max_slots = 3-10,槽位管理真正影响结果。
4. 考虑延迟
在实盘交易中,cascade切换不是瞬时的。关闭fallback仓位 + 开启primary = 2次API调用 + 网络延迟 + 交易所撮合。在波动市场中,价格可能在200-500ms内变动。需要预留滑点预算。
5. 监控fill_efficiency
在生产环境中跟踪实际fill_efficiency。如果显著低于回测值——编排器没有按预期利用空闲时间。原因:API延迟、被拒绝的订单、保证金约束。
6. 使用自适应优化
Cascade参数(dual_size、score权重、槽位限制)不应是静态的。使用自适应drill-down定期用最新数据重新校准。市场在变——cascade参数应当跟随变化。
「回测无幻觉」系列:总结
 完整系统架构:从数学基础经过验证到实盘编排的13个互联模块
完整系统架构:从数学基础经过验证到实盘编排的13个互联模块
本文是13+篇文章系列的终篇。每篇文章解决了从回测到生产环境路上的一个具体问题。以下是它们的关联:
基础:收益率数学
亏损与利润的不对称性 ——收益率的乘法本质、波动率拖累、凯利准则。这是所有后续内容的数学基础:为什么MaxDD决定杠杆,为什么夏普比率比原始PnL重要,为什么对称R:R下50%胜率是亏损的。
验证:置信区间和稳健性
Monte Carlo bootstrap ——将单点估计转化为带置信区间的分布。任何指标(PnL、MaxDD、夏普比率)只有带置信区间才有意义。
Walk-forward优化 ——样本外验证。历史数据上的回测是样本内结果;WFO展示策略在新数据上的表现。
平台期分析 ——参数稳健性检验。如果最优值是孤立的点——策略过度优化。
回测与实盘一致性 ——回测与实际结果的对照。规模化前的最终检验。
真实成本:资金费率和杠杆
资金费率杀死杠杆 ——永续合约上杠杆的隐藏成本。不计入资金费率,漂亮的回测就变成亏损。
资金费率套利 ——如何通过跨交易所策略将资金费率从支出变为收入来源。
指标和排序
按活跃时间的PnL ——组合中策略排序的指标。原始PnL不可缩放;PnL/活跃天——可缩放。
信号相关性 ——相关交易对组合中的有效分散化。
基础设施和优化
多时间框架回测的Parquet缓存 ——快速迭代的数据基础设施。
自适应drill-down ——自适应优化:粗网格 -> 有前景区域的精细调优。
Optuna vs 坐标下降 ——优化器选择:Optuna适用于低维度带噪声的目标函数,坐标下降适用于高维度光滑的目标函数。
Polars vs Pandas ——回测中DataFrame操作的性能。
编排(本文)
Cascade策略 ——将所有前述组件统一为一个可运行的系统。基于评分的分配使用PnL/活跃时间、置信度调整、资金费率成本。Cascade模式填充空闲期。联合模拟验证组合。Monte Carlo bootstrap为cascade PnL提供置信区间。
每篇文章是独立的模块。组合在一起,它们形成从数据加载到策略组合实盘编排的完整流水线。
结论
Cascade——不是策略组合的唯一方法。但它是最简单和最实用的方法之一:primary策略以全力交易,fallback以缩减仓位填充空闲期。两个关键参数(dual_size和max_slots)为大多数配置提供了足够的灵活性。
三个结论:
-
Cascade只能通过联合模拟来回测。 累加单独PnL会高估结果。切换成本、重叠、槽位约束——所有这些只有在联合模拟中才能被考虑。
-
dual_size决定了权衡:PnL vs 回撤。 典型最优值5-10%。基于夏普比率的网格搜索——是可靠的选择方法。
-
编排器是基于评分的优先级队列。 一切归结为每个信号的一个数字(score)。Score = f(PnL/活跃天, MaxLev, 置信度, 资金费率)。评分最高的策略获得槽位。其余等待。
「回测无幻觉」系列展示了一件事:在漂亮的回测和真实利润之间——有数十个陷阱。每篇文章消除其中一个。Cascade编排——是最后一步:将一组经过验证的策略转化为可运行的投资组合。
参考链接
- López de Prado — Advances in Financial Machine Learning: Portfolio Construction
- Pardo, R. — The Evaluation and Optimization of Trading Strategies
- Ernest Chan — Algorithmic Trading: Winning Strategies and Their Rationale
- Perry Kaufman — Trading Systems and Methods, Chapter on Portfolio Allocation
- Tomasini, Jaekle — Trading Systems: A New Approach to System Development and Portfolio Optimisation
- Bailey, D.H. & López de Prado — The Deflated Sharpe Ratio
- Markowitz, H. — Portfolio Selection (1952)
- Kelly, J.L. — A New Interpretation of Information Rate (1956)
引用
@article{soloviov2026cascadestrategies,
author = {Soloviov, Eugen},
title = {Cascade策略:优先执行与fallback填充},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/cascade-strategies-orchestration},
version = {0.1.0},
description = {「回测无幻觉」系列终篇。如何构建N策略×M交易对的编排器,实现级联模式的优先和fallback填充,选择dual\_size,以及为什么不能通过简单汇总PnL来回测策略组合。}
}
MarketMaker.cc Team
量化研究与策略